







AIを使った名寄せの方法|プロンプト設計からツール選定まで解説

「生成AIで名寄せができる」と聞いても、実際にどう動くのか、どこまで信頼できるのか、判断しにくいと感じている方は多いはずです。
ルールベースのSQLやスクリプトで表記ゆれに対応してきたものの、新しいパターンが出るたびに修正が発生し、前処理だけで時間を使い果たしてしまう。そういった状況で、LLMの活用を検討し始めているのではないでしょうか。
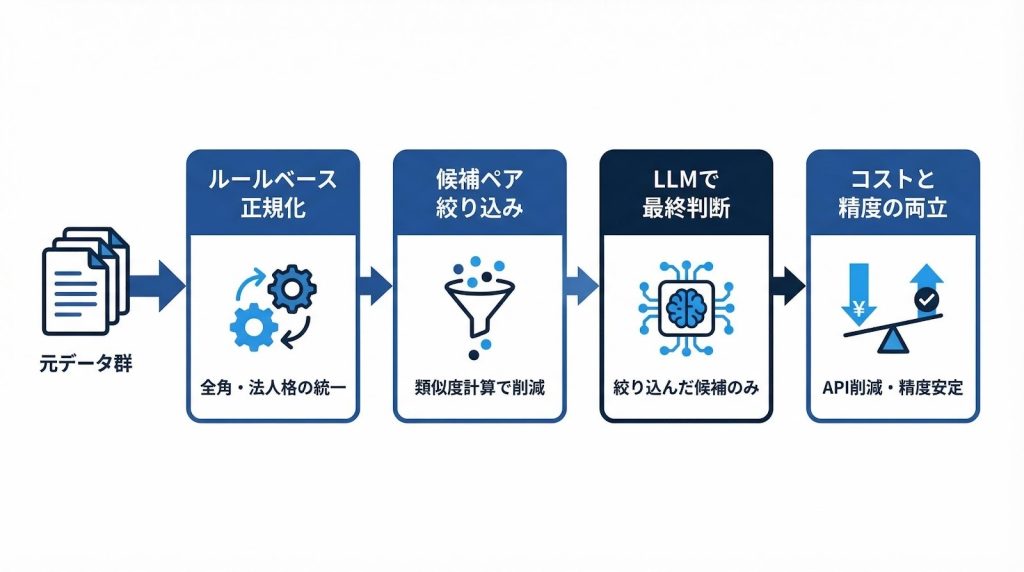
生成AI(LLM)を名寄せに使うことは、技術的に十分可能です。ただし「LLMに全部任せれば解決する」わけではなく、ルールベースの正規化処理と組み合わせるハイブリッド手法が実用的な選択肢になります。
この記事では、ルールベース名寄せが限界を迎える構造的な理由から始め、LLMが意味的な判断でどう補完できるかを整理します。プロンプト設計とPythonコード例を含む実装手順、ハルシネーション対策と情報漏洩リスクへの対処、既存ツールと自作APIの使い分け判断まで、自社での適用可否を判断するために必要な情報を順に押さえていきます。
ルールベース名寄せが限界を迎える3つの理由

名寄せの自動化を検討するとき、最初に突き当たるのが「ルールを増やしても追いつかない」という問題です。全角半角の統一や法人格の正規化といった処理はルールで対応できますが、それだけでは実務の表記ゆれを網羅できません。
マスターデータが整備されていない環境では、そもそも「正しい表記」の基準が存在しないという、より根本的な問題もあります。以下の3つの理由が重なることで、ルールベース名寄せは構造的な限界を迎えます。
理由1: 表記ゆれパターンはルールで網羅できない
企業名ひとつをとっても、「株式会社ジーニー」「㈱ジーニー」「GENIEE」と、同一企業を指す表記は複数のシステムに混在しています。全角半角の違い、法人格の位置(前株・後株)、略称、英日混在、さらには入力ミスによる誤字脱字まで含めると、パターンの組み合わせは際限なく広がります。
ルールベースで対応しようとすると、新しいパターンが見つかるたびにSQLやスクリプトを修正する必要が生じます。修正のたびに既存ルールとの整合性確認が必要になり、メンテナンスコストは累積的に増大していきます。「いたちごっこ」という表現がよく使われますが、実態はそれ以上で、ルールの数が増えるほど管理コストが指数的に膨らむ構造的な問題です。
理由2: マスターデータ不在が一意識別を困難にする
ルールベース名寄せが機能するには、「どれが正しい表記か」を判断する基準が必要です。しかし、商品マスターや顧客マスターが整備されていない環境では、その基準自体が存在しません。
この問題が顕在化しやすいのは、SFAやCRMへのデータ移行・統合プロジェクトです。複数の部門や拠点がそれぞれ独自に管理してきた顧客データを一元化しようとすると、「どのレコードが同一顧客か」を判断する共通の軸がないまま作業を進めることになります。ルールを書いても、照合先のマスターがなければ判断の拠り所を失います。
ECサイトや基幹システムで商品マスターが存在しないケースも同様です。商品名の表記ゆれを名寄せしようにも、「正規の商品名」が定義されていなければ、どの表記に統一すべきかをルールで決めることができません。マスターデータの整備とセットで考えなければ、名寄せの問題は解決しません。
理由3: 手作業前処理が分析工数を圧迫する
名寄せの問題は、精度だけの話ではありません。前処理の手作業に工数が集中することで、本来の分析・施策立案に充てる時間が慢性的に不足するという構造的な問題があります。
複数システムに分散した顧客データを統合する場合、各システムのデータ形式の違いを吸収しながら、重複レコードを目視で確認し、表記ゆれを手動で修正するという作業が発生します。データ量が増えるほど、この前処理工数は線形以上に膨らみます。
データ活用の課題として「利活用方法の欠如」や「人材不足」を挙げる企業が少なくない背景には、こうした前処理の負荷が分析担当者の時間を奪っている実態があります。名寄せの自動化は、精度向上だけでなく、分析工数の解放という観点からも重要な課題です。
生成AIが名寄せに有効な理由:意味理解とハイブリッド活用

ルールベースが苦手とする「意味的な判断」こそ、LLMが得意とする領域です。文字列の一致ではなく、単語や文脈の意味的な近さで判断するため、略称・誤字脱字・多言語混在といったパターンにも対応できます。
ただし、LLMを単独で使うと処理コストと精度の安定性に課題が生じます。ルールベースとLLMをそれぞれの得意領域で使い分けるハイブリッド手法が、実用的な設計の基本です。
ルールベース名寄せとAI名寄せの役割の違い
ルールベースとLLMは、得意な処理が明確に異なります。どちらが優れているかではなく、どの処理をどちらに任せるかを設計することが重要です。
| 比較軸 | ルールベース | LLM(生成AI) |
| 対象データ | 全角半角・フォーマット統一・明示的パターン | 略称・誤字脱字・多言語混在・意味的類似 |
| 判断の仕組み | 文字列の完全一致・正規表現 | トランスフォーマーによる文脈理解と言語知識を活用した意味的判断(候補絞り込みにはEmbeddingを活用) |
| 精度 | 定義済みパターンは高精度・未定義パターンは対応不可 | 未定義パターンにも対応できるが、ハルシネーションのリスクあり |
| コスト | 初期構築後は低コスト | APIコストとレイテンシが発生 |
| メンテナンス性 | 新パターンのたびに修正が必要 | プロンプト調整で対応できるが、出力の一貫性管理が必要 |
ルールベースは、電話番号のフォーマット統一や全角半角の正規化など、「正解が一意に決まる処理」に強みを持ちます。処理速度が速く、APIコストも発生しないため、大量データの前処理には適しています。
一方、「ジーニー」と「GENIEE」が同一企業かどうかの判断、外国人名の英語表記とカタカナ表記の対応付けといった意味的な判断は、ルールでは対応できません。LLMはこうした曖昧な判断を、学習済みの言語知識を使って処理できます。
ハイブリッド手法が実用的な理由
LLMを名寄せに使う場合、全件をAPIに投げる設計は現実的ではありません。処理コストが高くなるだけでなく、類似度が低い無関係なレコードまでLLMに判断させることで、精度も不安定になります。
前処理でルールベース正規化を行い、候補ペアを絞り込んでからLLMに渡す設計が、コストと精度のバランスを取る上で合理的です。
具体的には、まず全角半角統一・法人格の正規化・不要文字の除去をルールベースで処理します。その後、編集距離やTF-IDFなどの軽量な類似度計算で「同一エンティティの可能性がある候補ペア」を絞り込み、その候補ペアのみをLLMに渡して最終判断を行います。この設計により、LLMへのAPI呼び出し回数を大幅に削減できます。
多言語混在データへの対応では、プロンプトの中で言語混在を明示的に指示することが有効です。
「英語表記と日本語カタカナ表記は同一人物を指す可能性があります。翻字の揺れを考慮して判断してください」といった指示を加えることで、対応精度を高められます。
複数システムのデータが散在|CDP活用でデータクレンジングと名寄せを自動化
生成AIを使った名寄せの実装手順:プロンプト設計からコード例まで

実装の全体像は「前処理→プロンプト設計→API呼び出し→結果検証」の4ステップで構成されます。
各ステップには明確な役割があり、順番を守ることが精度とコストの両立につながります。以下では各ステップの具体的な手順を順に示します。
ステップ1:前処理でルールベース正規化を行う
LLMに渡す前のデータを整えることが、精度とコスト削減の両方に直結します。前処理の目的は2つあります。ひとつはLLMが判断しやすい形にデータを標準化すること、もうひとつは候補ペアを絞り込んでAPI呼び出し回数を減らすことです。
前処理で実施する主な正規化処理は次のとおりです。
- 全角英数字・記号を半角に統一
- 法人格の正規化(「株式会社」「㈱」「(株)」を統一表記に変換)
- 不要文字の除去(空白・括弧・特殊記号など)
- 大文字・小文字の統一
- 住所表記の正規化(「丁目」「番地」の表記統一など)
正規化後、編集距離(レーベンシュタイン距離)やJaccard係数などの軽量な類似度計算で候補ペアを生成します。閾値を設定して「一定以上の類似度を持つペアのみ」をLLMに渡すことで、全件処理と比べてAPI呼び出し回数を大幅に削減できます。
ステップ2:プロンプトを設計する
名寄せの精度はプロンプトの設計で大きく変わります。判断基準が曖昧なプロンプトでは、同じ入力でも毎回異なる結果が返ってくることがあります。出力の一貫性を確保するために、次の要素をシステムプロンプトに含めてください。
Temperature=0の設定
名寄せはクリエイティブな生成ではなく、判断の一貫性が求められるタスクです。temperature=0 に設定することで、出力の一貫性を最大限に高められます。同一入力に対してほぼ同じ判断結果を得やすくなるため、本番運用では原則としてこの設定を使用してください。なお、GPU処理の特性上、完全な決定論的出力が保証されるわけではない点に留意してください出力フォーマットの指定
出力をJSON形式で指定することで、後続の処理でパースしやすくなります。以下のようなフォーマットを指定します。
{
“is_same_entity”: true,
“confidence”: 0.95,
“reason”: “略称と正式名称の関係にあり、同一企業と判断”
}
システムプロンプトのサンプル(企業名名寄せ)
あなたは企業名の名寄せ専門家です。
2つの企業名が同一企業を指しているかどうかを判断してください。
判断基準:
– 略称と正式名称の関係(例:トヨタ → トヨタ自動車株式会社)
– 法人格の違いは同一企業と判断する(株式会社、㈱、(株)など)
– 英語表記と日本語表記の対応(例:TOYOTA → トヨタ自動車)
– 明らかに異なる企業名は false とする
出力はJSON形式で返してください:
{
“is_same_entity”: true/false,
“confidence”: 0.0〜1.0,
“reason”: “判断理由を1文で”
}
【Few-shot例】
入力:「株式会社ジーニー」と「GENIEE」
出力:{“is_same_entity”: true, “confidence”: 0.95, “reason”: “英語表記と日本語正式名称の対応関係にある”}
入力:「本田技研工業株式会社」と「本多技研」
出力:{“is_same_entity”: false, “confidence”: 0.85, “reason”: “「本多」と「本田」は異なる企業名であり、同一企業とは判断できない”}
Few-shot例示(正解例・不正解例)をプロンプト内に含めることで、LLMが判断基準を具体的に理解しやすくなります。特に判断が難しいケースを例示に含めると、精度向上に効果的です。
ステップ3:APIを呼び出してバッチ処理を設計する
候補ペアのリストをLLMに渡してバッチ処理する際は、レート制限対応・エラーハンドリング・リトライロジックを組み込むことが安定運用の前提です。
モデルの選択は、精度とコストのトレードオフで判断します。判断が難しい曖昧なケースが多い場合は高性能モデルを使い、前処理で候補ペアを十分に絞り込めている場合は軽量モデルで対応できます。両者を組み合わせて、信頼度スコアが低いケースのみ高性能モデルで再判断する設計も有効です。
ステップ4:結果を検証・修正する
LLMの出力をそのまま本番データに適用するのは危険です。まずサンプルを確認し、失敗例のパターンを分析してプロンプトを調整するサイクルを繰り返すことが、実運用に耐える精度に近づく唯一の方法です。
成功例と失敗例を比較すると、改善の方向性が見えてきます。
| 入力ペア | LLMの判断 | 正解 | 評価 |
| 「ソニー」/ 「Sony Group Corporation」 | 同一(信頼度0.92) | 同一 | ✓ 成功 |
| 「日本電気㈱」/ 「NEC」 | 同一(信頼度0.88) | 同一 | ✓ 成功 |
| 「三菱商事」/ 「三菱電機」 | 同一(信頼度0.61) | 別企業 | ✗ 失敗(グループ企業の誤同定) |
| 「本多技研」/ 「本田技研工業」 | 同一(信頼度0.55) | 別企業 | ✗ 失敗(類似名称の誤同定) |
失敗例を見ると、グループ企業の誤同定と類似名称の誤同定という2つのパターンが浮かび上がります。
前者はFew-shot例示に「同じグループ名を持つ別企業は false とする」という例を追加することで改善できます。後者は「漢字1文字の違いは別企業の可能性が高い」という判断基準をシステムプロンプトに追記することで対応できます。
信頼度スコアが低いケース(0.7未満など)を人間確認に回すワークフローについては、次章で詳しく説明します。
AI名寄せの精度限界とセキュリティリスクへの対処
LLMを名寄せに使う上で、精度の限界とセキュリティリスクの2つは避けて通れない問題です。どちらも「使わない理由」ではなく、「設計で対処すべき課題」として捉えることが重要です。
ハルシネーション対策には品質担保ワークフローの組み込みが、情報漏洩リスクには3層の対処法が有効です。
ハルシネーション対策と品質担保ワークフロー
LLMが誤った名寄せ結果を返す典型的なパターンは、大きく2つあります。ひとつは「三菱商事」と「三菱電機」のように、グループ名が共通する別企業を同一と判断するケース。もうひとつは、実在しない企業名を既存の企業に紐付けてしまうケースです。いずれも、LLMが文字列の表面的な類似性に引きずられて判断を誤る場合に発生します。
これらのリスクを管理するために有効なのが、信頼度スコアによる振り分けワークフローです。プロンプトで確信度スコア(0〜1)を出力させ、スコアに応じて処理を3段階に分けます。
| 信頼度スコア | 処理区分 | 対応 |
| 0.85以上 | 自動処理 | LLMの判断をそのまま適用 |
| 0.60〜0.84 | 要確認 | 担当者が結果を確認してから適用 |
| 0.60未満 | 手動処理 | 担当者が手動で判断・修正 |
閾値の設定はデータの特性によって調整が必要です。誤同定のコストが高い(顧客データの誤統合が重大な問題につながる)場合は、自動処理の閾値を0.90以上に引き上げることを検討してください。Human-in-the-loopを組み込むことで、LLMの判断を完全に信頼するのではなく、人間の確認が必要なケースを適切に抽出できます。
情報漏洩リスクの3層対処法
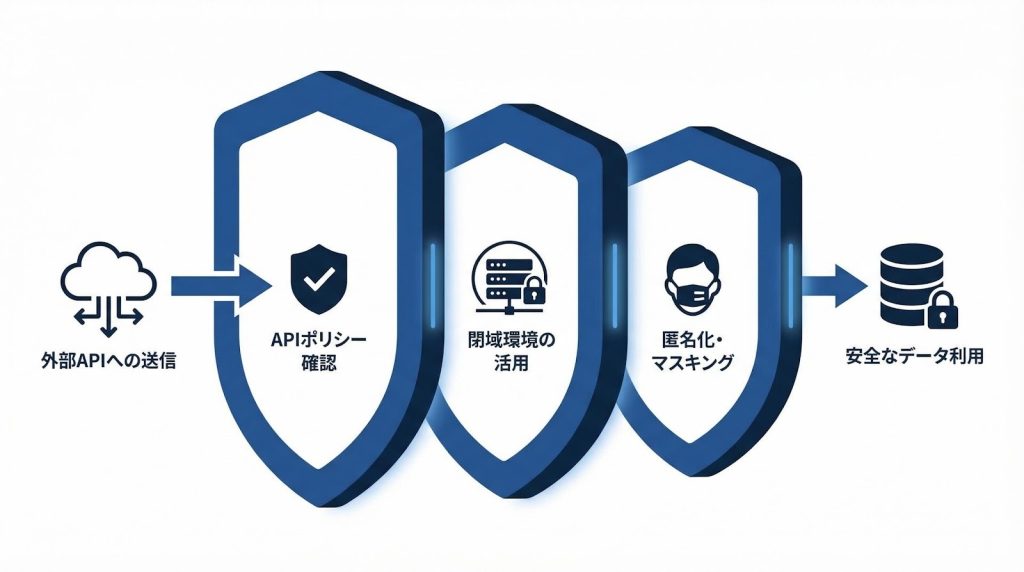
顧客データや企業情報を外部のAPIに送信することには、情報漏洩リスクが伴います。このリスクへの対処は、以下の3層で考えることが実用的です。
第1層:API利用ポリシーの確認
生成AIサービスに個人データを含むプロンプトを入力する際は、サービス提供者がその個人データを機械学習に利用しないことを事前に確認する必要があります。OpenAI APIは、2023年3月以降、ユーザーが明示的に許可しない限り、API経由で送信されたデータをモデルの学習・改善に使用しないポリシーを採用しています(ただし、不正利用監視目的で30日間データが保持されます)。なお、ChatGPT Web版(無料・Plusプラン)はこのポリシーの対象外であるため、業務利用ではAPI経由またはEnterprise/Teamプランを使用してください。但し本記事執筆時点の情報となり、利用規約は定期的に確認することを推奨します
また、個人情報取扱事業者が生成AIサービスに個人データを入力する行為は、個人情報保護法上の『第三者提供』に該当する可能性があります。特に、AIサービス提供者が入力データを機械学習等に利用する場合は、本人同意なしに個人データを提供したことになりかねません。API経由で学習に使用されない設定であっても、委託先監督義務(法25条)や外国にある第三者への提供規制(法28条)の観点から法的検討が必要です。
なお、2026年2月に日本ディープラーニング協会(JDLA)は、技術的条件や契約条件によっては個人データ入力を一律禁止する必要はないとの見解を示しています。第2層:閉域環境の活用
Azure OpenAI ServiceやAmazon Bedrockを使ったプライベート環境での処理は、外部APIへのデータ送信リスクを回避する有効な手段です。
これらのサービスでは、入力データがモデルの学習に使用されないことが契約上保証されており、企業のセキュリティポリシーに適合しやすい環境を構築できます。セキュリティ要件が厳しい業種(金融・医療・官公庁など)では、この選択肢を優先的に検討することをお勧めします。
第3層:入力前の匿名化・マスキング
個人名・住所・電話番号・メールアドレスなどの個人情報を仮IDに置換してからAPIに渡す匿名化・マスキング処理により、個人情報保護法上のリスクを低減できます。名寄せの判断に必要な情報(企業名・商品名など)のみをAPIに渡し、個人を特定できる情報は送信しない設計が基本です。
例えば、「山田太郎、東京都渋谷区、03-XXXX-XXXX」という顧客データを名寄せする場合、「ID_001、東京都渋谷区、エリアコード03」のように置換してからAPIに渡し、名寄せ結果をIDで管理する方法が考えられます。
既存ツールと自作APIとの使い分け判断
既存ツールと自作APIのどちらを選ぶかは、3つの軸で判断できます。
| 判断軸 | 既存ツールが向いているケース | 自作APIが向いているケース |
| カスタマイズ要件 | 標準的な名寄せ要件・専門エンジニア不在 | 独自の名寄せロジックが必要・既存システムへの深い統合 |
| データ量・処理規模 | 中小規模・早期導入を優先 | 大規模バッチ処理・コスト最適化が必要 |
| セキュリティ要件 | クラウドサービスの利用が許容される環境 | 閉域環境が必須(Azure OpenAI・Amazon Bedrock等) |
専門エンジニアが社内にいない場合や、早期に導入して効果を確認したい場合は、既存ツールの活用が合理的です。
一方、業種特有の名寄せロジック(医療機関名の略称体系、金融機関コードとの照合など)が必要な場合や、既存の基幹システムとの深い統合が求められる場合は、自作APIの方が柔軟に対応できます。
名寄せ後のデータ活用まで視野に入れる場合、ID名寄せ・統合機能を標準搭載したCDPという選択肢もあります。GENIEE CDPのようなサービスは、ノーコードデータ連携・テンプレートダッシュボード・AIによる分析支援を一体で提供しており、名寄せ処理だけでなく、統合後のデータを分析・施策立案に活用するまでの一連のフローを一つの基盤で管理できます。
「顧客データの分析の仕方がわからない」「社内に専門家がいない」といった課題を抱える企業にとっては、自作APIで個別に構築するよりも導入・運用の負荷を抑えられる場合があります。
生成AIによる名寄せ導入の判断まとめ

この記事では、ルールベース名寄せが抱える構造的な限界から始め、LLMを活用したハイブリッド手法の設計、プロンプトとコードを含む実装手順、精度担保とセキュリティ対策、そして既存ツールと自作APIの使い分けまでを整理しました。
まず試せる最小構成は、手元の小規模データ(数百件程度の候補ペア)でプロンプトを検証することです。Temperature=0・JSON出力・Few-shot例示の3点を組み込んだプロンプトを作り、成功例と失敗例を分析してプロンプトを調整するサイクルを数回回すことで、自社データへの適合度と運用コストの見通しが立ちます。
その結果を踏まえて、自作APIの本格実装か既存ツール・CDPの活用かを判断するアプローチが現実的です。名寄せ後の分析・施策立案まで一貫して対応したい場合は、GENIEE CDPのようなID名寄せ・統合機能を標準搭載したCDPも、導入・運用コストを抑えながらデータ基盤を整える選択肢のひとつとして検討してみてください。
関連記事
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。













