ETLツールとは?選び方の6つの比較軸と主要5製品を紹介

各システムに散在するデータを集計・分析するために、手作業やExcelでの転記、個別のスクリプトに依存している企業は少なくありません。しかし、こうした運用は膨大な工数を要するだけでなく、計算ミスやデータ不整合を招き、分析の正確性を損なうリスクがあります。
こうした課題を解決するのが、データの抽出・変換・格納を自動化するETLツールです。SaaSやデータベースなど多様なソースからデータを収集し、統一された形式に変換してデータウェアハウスやCDPへ格納することで、分析基盤の構築を効率化します。
本記事では、ETLツールの基本的な仕組みと導入メリットを整理したうえで、自社に最適なツールを選定するための比較軸、主要製品の特徴、実際の導入事例、そして運用時の注意点までを詳しく解説します。
ETLツールとは?データ統合の課題を解決する仕組み

ETLツールは、Extract(抽出)・Transform(変換)・Load(格納)の3つの工程を通じて、散在するデータを分析可能な形に統合する役割を担います。
この章では、ETLの基本定義と各工程の具体的内容、現場で発生しがちな課題への対応、そしてEAIやBIツールとの違いを順に見ていきます。
ETLの3つの工程(Extract/Transform/Load)
ETLは、データ統合の基幹となる3つの工程で構成されます。まずExtract(抽出)では、SaaSやデータベース、ファイルサーバーなど多様なソースから必要なデータを収集します。次にTransform(変換)では、重複排除や形式統一、データ型の変換を行い、分析に適したデータ品質を確保します。
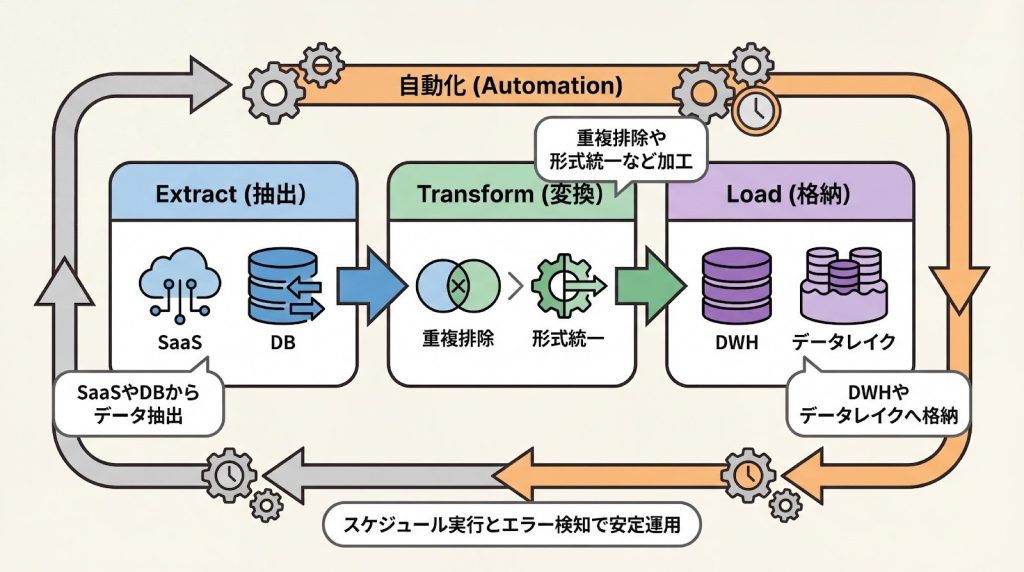
最後にLoad(格納)では、変換済みのデータをデータウェアハウス(DWH)やデータレイクに格納し、BIツールやAIによる分析に利用できる状態にします。
この3工程を手作業で実施すると、データ量の増加やAPI仕様の変更に伴う修正が頻発し、運用負荷が増大します。ETLツールは、これらの工程を自動化し、スケジュール実行やエラー検知、リトライ処理を組み込むことで、安定したデータ連携基盤を提供します。
ETLツールが解決する4つの課題
データ統合・活用に関する現場では、データの散在、加工ミス、属人化、運用負荷という4つの課題が頻繁に発生します。
ETLツールは、各データソースとの自動連携によってデータ統合業務の工数を削減し、ヒューマンエラーによるデータ不整合を防止します。また、GUI操作により開発を標準化し、特定の担当者に依存しないメンテナンス体制を実現します。
さらに、API変更への対応やデータ量増加に伴うスケーリングも、ツール側のアップデートや設定変更で柔軟に対処できるため、本来の分析業務に集中できる環境を整えることができます。
EAI・BIツールとの違いと使い分け
EAI(Enterprise Application Integration)はシステム間のリアルタイム連携を目的とし、受注データを即座に在庫管理システムに反映するような用途に適しています。
一方、ETLは分析用のバッチ処理を前提とし、定期的にデータを抽出・変換してDWHに蓄積します。BIツールは、DWHに格納されたデータを可視化し、ダッシュボードやレポートを生成する役割を担います。
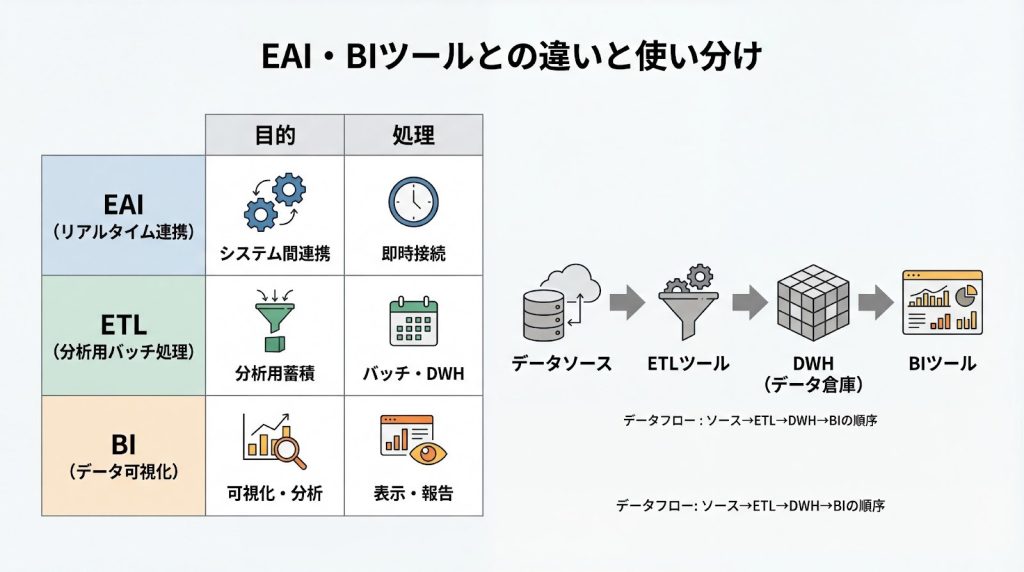
マーケティング活用が主目的であれば、ETL機能を内包するGENIEE CDPのようなプラットフォームの活用が効率的です。
CDPは顧客データの統合と活用を一体化し、セグメント作成やキャンペーン配信までをワンストップで実現できるため、目的に応じて適切なシステムをご検討ください。
ETLツールの選び方|4つの比較軸と優先順位の決め方
自社に最適なツールを選定するには、接続先コネクタの対応範囲、操作性とノーコード対応レベル、提供形態とセキュリティ要件、料金体系とコストパフォーマンスの4つの軸を中心に評価します。この章では、各軸の具体的な確認ポイントと、優先順位の決め方を順に解説します。
1. 接続先コネクタの対応範囲を確認する
自社が利用する主要なSaaSやデータベースとの標準コネクタが用意されているかを確認することが、選定の第一歩です。コネクタ数だけでなく、自社の基幹システムや広告媒体との連携精度を個別に検証する必要があります。
例えば、SalesforceやkintoneなどのSaaS、BigQueryやSnowflakeなどのDWHへの対応状況を、優先順位をつけてリストアップし、トライアル環境で実際にデータ取得を試すことで、仕様の変更や制限に対応できるかを確認します。
2. 操作性とノーコード対応レベルを評価する
ドラッグ&ドロップでのジョブ作成やスケジュール設定の容易さは、非エンジニアが運用する場合に重要な評価軸となります。現場担当者が自ら設定変更できるインターフェースは、DX推進のスピードを左右します。
一方で、複雑なデータ加工が必要な場合は、SQLやPythonによるカスタマイズ機能の有無も確認し、学習コストと柔軟性のバランスを検討します。
3. 提供形態とセキュリティ要件を整理する
クラウド型はスケーラビリティに優れ、初期投資を抑えられますが、社内のセキュリティポリシーとの整合性確認が必須です。
オンプレミス型は、データを社内に保持できるため、金融や医療など規制の厳しい業界に適しています。監査ログやアクセス制御、データ暗号化の機能を確認し、情報システム部門やセキュリティ担当者と連携して要件を整理します。
4. 料金体系とコストパフォーマンスを比較する
固定費型と従量課金型のメリット・デメリットを整理し、スモールスタートから大規模運用へのコスト推移を考察します。初期費用に加え、データ転送量やジョブ実行数による従量課金の有無を将来の拡張性含め試算します。
転送量課金の場合、データ量の急増により予算を超過するリスクがあるため、上限設定やアラート機能の有無を確認し、コスト管理の仕組みを事前に構築します。
主要なETLツール5選!機能や特徴を紹介

市場で評価の高い主要5製品の特徴を横断比較します。各ツールには国産・海外製、クラウド特化・汎用型など異なる強みがあり、エンジニアリソースが不足している組織では、標準連携やAIサポートが充実したツールの優先度が高くなります。
この章では、trocco、ASTERIA Warp、DataSpider Servista、AWS Glue、Talend Data Fabricの5製品を順に見ていきます。
trocco|日本発のクラウド型ETL、ノーコードで非エンジニアも利用可能
troccoは、日本企業のSaaS利用環境に最適化されたクラウド型ETLツールです。GUIベースの直感的なインターフェースを備え、ETL/ELT・データマート生成・ジョブ管理・データガバナンスなどデータ基盤構築に必要な機能を一元的にカバーします。
導入実績1,000社以上を誇り、スケジュール実行やエラー通知、リトライ処理を標準で提供します。
日本のSaaSや広告媒体との連携に強みを持ち、スケジュール実行やエラー通知、リトライ処理を標準で提供します。
ASTERIA Warp|国内シェアNo.1、19年連続の実績と信頼性
ASTERIA Warpは、長年の実績を誇る国内シェアトップクラスのデータ連携ツールです。ノーコードで高度な連携処理を実現し、オンプレミス・クラウド両対応の柔軟性を持ちます。
金融機関や製造業など、セキュリティ要件の厳しい業界での導入実績が豊富で、安定性と信頼性が評価されています。
DataSpider Servista|ドラッグ&ドロップで大規模データ処理にも対応
DataSpider Servistaは、GUIベースながら、複雑なデータ変換や大規模な処理を高速に実行できる国産ETLツールです。
多様なアダプタを用いて既存システムとノンプログラミングで連携でき、オンプレミス環境での運用を前提とした企業に適しています。
AWS Glue|サーバーレスで従量課金、AWS環境に最適
AWS Glueは、AWSエコシステム内でのデータ統合に特化したサーバーレスなデータ統合サービスです。インフラ管理不要でスケール可能であり、S3やRedshift、RDSなどのAWSサービスとのネイティブ連携が強みです。
従量課金のため、データ量や処理頻度に応じたコスト最適化が可能です。
Talend Data Fabric|オープンソース版あり、データ品質・ガバナンス統合
Qlik Talend Cloud(旧Talend Data Fabric) は、2023年にQlikがTalendを買収・統合したデータ統合プラットフォームです。
1,000以上のコネクタとコンポーネントを備え、データクレンジングや品質管理、ガバナンス機能を統合的に提供します。グローバル企業での導入実績が豊富で、オンプレミスからクラウドまで多様な環境に対応します。
▼マーケティング施策への即時反映を重視する場合
汎用的なETLツールは強力ですが、マーケティング活用にはDWH構築やBI連携など多くの工程が必要です。
エンジニアリソースが不足している場合や、データ統合からAI分析、施策実行までを最短で実現したい場合は、ETL機能を内包したGENIEE CDPの導入が推奨されます。自社ツール群との標準連携やAI分析サポートにより、運用負荷を大幅に軽減できます。
ETLツール導入時の注意点と運用のポイント
ETLツールの導入に失敗しないためには、どのようなポイントに注視するべきでしょうか。
この章では、データソースのAPI仕様変更への対応策、エラー検知とアラート設定のベストプラクティス、データ量増加に伴うパフォーマンス対策、そして発展的な活用としてReverse ETLとモダンデータスタックとの連携を順に見ていきます。
1. データソースのAPI仕様変更への対応策を講じる
頻繁に発生するSaaSのAPI更新に対し、コネクタの自動アップデート機能やベンダーサポートの活用が重要です。
コネクタの自動更新をツールベンダーが保証しているか、事前に契約内容を確認します。また、API変更の通知を受け取る仕組みを構築し、影響範囲を迅速に把握できる体制を整えます。
2. エラー検知とアラート設定について検討しておく
Slack連携等のリアルタイム通知や、リトライ設定による自動復旧ロジックの組み込みが、安定運用の鍵となります。
エラーの種類に応じた対応フローを整備し、システム停止時間を最小化する体制を作ります。ジョブ失敗時の即座の通知と、リカバリ手順のドキュメント化を導入初期から徹底します。
3. データ量増加に伴うパフォーマンス対策を講じる
差分更新の活用や処理の並列化など、データ量増加に合わせたチューニング手法を提示します。全件処理ではなく増分更新を活用することで、DWHへの負荷とコストを大幅に抑制できます。
また、処理の並列化やパーティション分割により、大規模データでも高速に処理できる設計を導入初期から検討します。
発展的な活用|Reverse ETLとモダンデータスタックとの連携
データ統合・蓄積後、それらを施策に活用するためには、例えばデータウェアハウスから各業務システムへデータを書き戻すといった設計も必要となります。
とりわけ近年においては、データ統合の先にある「AX(AI Transformation:AIを活用した業務・ビジネスモデルの変革)」を見据えた基盤選定が、将来の競争力を左右するでしょう。
そこで選択肢にあがるのが、Reverse ETLという考え方です。これはDWHに蓄積された分析結果をSalesforceやマーケティングツールに書き戻し、施策の自動化を実現します。GENIEE CDPは最初から活用基盤として設計されており、データ統合するだけでなく、施策実行までカバーできるように作られています。
ETLツールの選び方と導入のポイントまとめ
ETLツールは、散在するデータを統合し、分析基盤を効率化する役割を担います。自社の課題と連携先の優先順位を明確にし、まずはスモールスタートで導入効果を検証することが重要です。
導入時には、接続先コネクタの対応範囲、操作性とノーコード対応レベル、提供形態とセキュリティ要件、料金体系とコストパフォーマンスの4つの軸で評価し、トライアル環境で実際にデータ取得を試すことで、自社に最適なツールを選定していきましょう。
マーケティング成果を最短で出したい場合は、ETL機能を内包するGENIEE CDPの検討も有効です。データ統合の先にあるAIによる分析や考察を見据えた基盤選定が、将来の競争力を左右します。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。