







CDP要件定義で押さえるべき項目とは?チェックリストと進め方を解説

CDP(顧客データ基盤)を導入する際、多くの企業が「何を要件として定義すべきか」という壁に直面します。データソースの選定、ID統合のロジック、外部システムとの連携方式、法令遵守の要件など、検討すべき項目は多岐にわたり、定義漏れが発生すると後工程での手戻りや追加コストにつながります。
本記事では、CDP導入プロジェクトにおける要件定義の全体像を体系的に整理し、機能要件・データ要件・連携要件・非機能要件・運用要件の5つの観点から、具体的に定義すべき項目と実務的な進め方を解説します。
データソースの優先順位付け手法、ID統合(名寄せ)のルール設計、外部システムとのデータフロー設計、法令遵守とセキュリティ要件の定義方法について、実務で即座に活用できるチェックリストとステップを提示します。
【全体像】CDPの要件定義で網羅すべき項目
CDP導入時には、機能・データ・連携・非機能・運用の5つの大分類で要件を整理することで、プロジェクト全体の見通しを確保できます。この章では、各分類で定義すべき項目を体系的に示し、抜け漏れによる手戻りを防ぐための実務的な指針を解説します。
要件をゼロから洗い出すのは困難ですが、GENIEE CDPのような標準的な機能を備えたプラットフォームを基準に検討することで、定義漏れのリスクを大幅に低減できます。
【機能要件】CDPで実現すべき機能の定義
マーケティング施策を支えるセグメント抽出、プロファイル管理、分析の各機能について、ユースケースから逆算して必要な機能レベルを決定します。
1. セグメント抽出機能の定義項目
セグメント抽出では、条件指定の柔軟性や動的更新の頻度、件数予測の有無を具体化します。例えば、「過去30日以内に特定商品を閲覧したが購入していないユーザー」といった複合条件を、UIで直感的に設定できるか、あるいはSQLライクな記述が必要かを明確にします。
動的セグメントの更新頻度も重要です。リアルタイム施策に対応するならバッチ処理ではなくストリーミング処理が求められるため、システム側の処理能力と合わせて定義します。
2. プロファイル管理機能の定義項目
プロファイル管理では、保持すべき属性値と履歴データの種類、および更新ロジックを明確にします。顧客の基本属性(氏名、年齢、性別等)だけでなく、行動履歴(閲覧、購買、問い合わせ)や推定属性(興味関心、購買意欲スコア)をどの粒度で保持するかを定義します。
更新ロジックでは、複数データソースから同一顧客の情報が入力された際の優先順位(最新優先、信頼性優先等)や、欠損値の扱い(空白のまま保持、デフォルト値で補完等)を明文化します。
3. 分析機能の定義項目
分析機能では、ダッシュボードで可視化すべきKPIや、レポート出力の形式(CSV、PDF等)を定義します。リアルタイムでの集計が必要か、日次バッチで十分かも明確にします。
高度な分析を行う場合、RFM分析やコホート分析、LTV予測といった分析手法を標準機能として備えるか、外部BIツールと連携するかを検討します。
【データ収集要件】収集・統合・保持するデータの定義
収集対象となるデータソースの特定と、各データの粒度、品質管理ルールについて、法令遵守と業務効率のバランスを考慮したデータ保持ポリシーを策定します。
1. データソースの選定と優先順位
データソースはオンラインとオフラインの両面から、施策への寄与度が高いものを選定します。Webサイトの閲覧履歴、EC購買履歴、CRMの顧客情報、店舗POSデータ、コールセンター対応履歴など、候補を洗い出した上で、ビジネス価値と取得難易度のマトリクスで着手順位を決定します。
高価値かつ低難易度のデータから着手し、初期段階で成果を出すことがプロジェクト推進の鍵となります。
2. データクレンジング・正規化ルールの定義
データ品質を担保するため、欠損値処理や表記ゆれ対応などのクレンジングルールを明文化します。全角半角の統一、住所の分割(都道府県、市区町村、番地)、電話番号のハイフン有無の統一など、開発時の解釈のブレを未然に防ぐ細かなルールを定義します。
異常値が検知された際のアラート通知先と、データの修正・除外判断の責任者も明確にします。例えば、年齢が200歳といった明らかな異常値が入力された場合、自動で除外するか、手動レビューを挟むかを決めます。
【その他要件】連携要件・非機能要件・運用要件の定義ポイント
外部システムとの接続方式や、システムの安定稼働を支える非機能要件、導入後の保守体制について、実運用で重要となる項目を網羅します。
1. 連携要件の定義項目
連携要件ではMAやCRM等のシステム別に、APIかバッチかの連携方式と頻度を定義します。例えば、MAへのセグメント同期は日次バッチで十分か、リアルタイムAPIが必要かを施策の即時性要件に基づき判断します。
連携エラー時のリトライ回数や、異常を検知した際の担当者への通知フローも定義します。API制限(レート制限)への対応方法も明記します。
2. 非機能要件の定義項目
非機能要件ではセキュリティや可用性に加え、CMP連携などのコンプライアンス要件が重要性を増しています。データの暗号化(保管時、通信時)、アクセス制御(ロールベースアクセス制御)、監査ログの取得と保管期間を定義します。
可用性については、システムの稼働率目標(SLA)や、障害発生時の復旧時間目標(RTO)、データ損失許容時間(RPO)を明確にします。
3. 運用要件の定義項目
運用要件にはデータガバナンス体制を含め、誰がデータの正確性を担保するか役割を明確化します。データスチュワード(データ品質責任者)を設置し、定期的なデータ品質レビューの頻度と手順を定義します。
問い合わせ対応体制(ヘルプデスクの設置、エスカレーションフロー)や、定期メンテナンスの実施タイミングも明記します。
データ取得要件を決めるためのポイント

CDPの導入に当たっては、どのデータソースを・どのように統合するか?明確に定義しておくことが重要です。
この章では、ビジネス価値と取得難易度のマトリクスを用いたデータソースの優先順位付けと、3層構造(属性・履歴・指標)による項目定義の具体例を紹介します。
ポイント1. オフライン/オンラインと場合分けをしてデータソースを検討する
まずはWeb閲覧履歴などのオンラインデータと、店舗購買等のオフラインデータの特性を整理し、統合要否を検討していきましょう。
1. オンラインデータの特性と課題
オンラインデータはリアルタイム性が高い一方、匿名ユーザーの識別が大きな課題となります。Cookieベースのトラッキングでは、ブラウザやデバイスをまたいだ追跡が困難であり、ログイン前の行動データを個人に紐付けるには、会員登録やメールアドレス入力といったタイミングを活用する必要があります。
データソース選定では、ビジネス価値と取得難易度のマトリクスで着手順位を決定します。高価値かつ低難易度のデータから着手し、初期段階で成果を出すことが重要です。
2. オフラインデータの特性と課題
オフラインデータは実名情報と紐付きやすいものの、デジタル化や連携に工数がかかる傾向があります。店舗POSデータやコールセンター対応履歴は、既存システムからのデータ抽出やフォーマット変換が必要となり、リアルタイム連携が難しいケースも多くあります。
業界特性に応じて優先順位を調整します。例えば、店舗ビジネスが主体の小売業では、POSデータの統合が最優先となる一方、純粋なWebサービスではオフラインデータの優先度は低くなります。
ポイント2. 取得するデータの種類と粒度の検討を進める
統合対象とするデータソース(オンライン/オフライン)を決めたら、具体的なデータ取得項目(データの種類)も検討を進めます。
ここでは取得データを「顧客属性」「行動履歴」「派生指標」の3つに場合分けし、それぞれの特徴と具体的な記載項目例を紹介します。
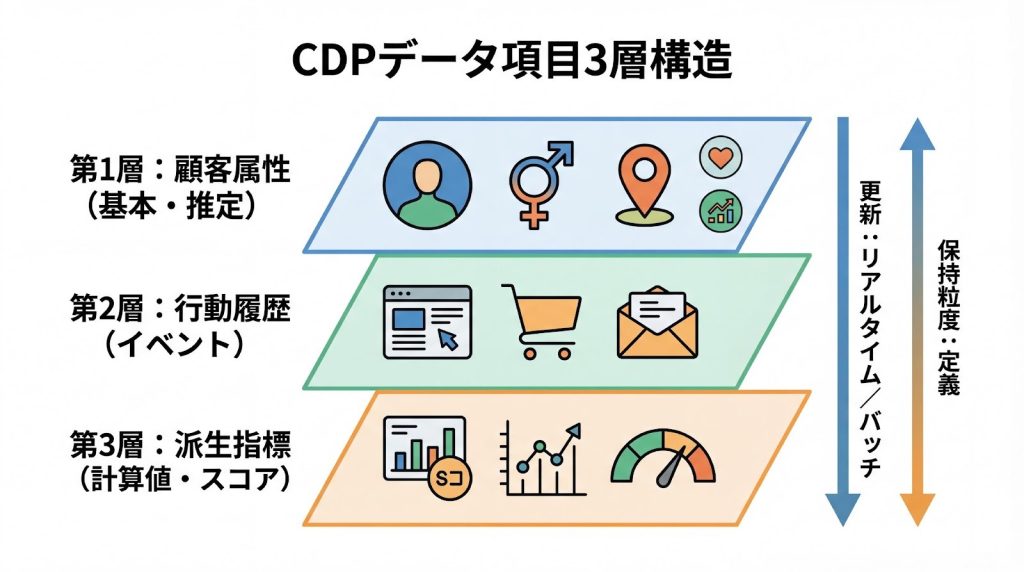
1. 顧客属性の定義
属性情報は不変的な基本属性(氏名、生年月日、性別、住所等)だけでなく、興味関心等の推定属性も定義対象に含めます。
推定属性は、閲覧履歴や購買履歴から機械学習で算出するスコア(例:ファッションへの関心度、価格感度)を指し、セグメント抽出やレコメンデーションの精度向上に寄与します。
2. 行動履歴
行動履歴は、Webページ閲覧、商品購入、メール開封、問い合わせといったイベントデータを指します。各イベントには、発生日時、対象商品ID、金額、チャネル(Web、店舗、アプリ等)といった属性を付与します。
3. 派生指標(RFM・LTV等)
RFMやLTV等の派生指標は、計算ロジックと更新タイミングをセットで定義することが重要です。例えば、RFM(最終購買日、購買頻度、購買金額)は日次バッチで更新するか、リアルタイムで再計算するかを明確にします。
なお、どのデータを分析に使うべきか迷う場合は、GENIEE CDPのAIによる自然言語分析サポートを活用するのも一つの手です。専門知識がなくても、チャット形式で必要なデータを探索・特定できるため、要件定義の負荷を軽減できます。
ポイント3. データ正規化・クレンジングルールも検討しておく
統合対象とするデータソースと項目を決めたら、表記ゆれの統一や欠損値の補完ロジックなど、実装前に決めておくべきデータ処理ルールを具体化します。
1. 表記ゆれと正規化ルール
全角半角の統一や住所の分割ルールを明文化し、開発時の解釈のブレを未然に防ぎます。例えば、電話番号はハイフンなしの半角数字に統一、住所は都道府県・市区町村・番地の3フィールドに分割、といった具体的なルールを定義します。
企業名や商品名の表記ゆれ(株式会社と(株)、スペースの有無等)も、マスターデータとの照合ルールを明確にします。
2. 異常値検知と対応フロー
異常値が検知された際のアラート通知先と、データの修正・除外判断の責任者を定義します。年齢が200歳、購買金額がマイナス、といった明らかな異常値は自動除外し、閾値ぎりぎりのケース(例:年齢120歳)は手動レビューを挟むなど、段階的な対応フローを設計します。
異常値の検知ロジック(統計的外れ値検出、ルールベース判定等)と、検知後の通知先(データスチュワード、システム管理者等)を明文化します。
ID統合(名寄せ)ロジック設計要件の検討の進め方
次に、分散した顧客データを一つに統合するための、決定論的・確率的マッチング手法の使い分けとキー項目の優先順位を解説します。この章では、統合精度を維持するための運用ルールと検証方法についても提示します。
【名寄せロジックの理解】決定論的マッチングと確率的マッチング
まずは、データ統合にあたっての名寄せロジックを理解しておきましょう。
ここでは、精度重視の決定論的手法と、統合率重視の確率的手法のメリット・デメリットを比較し、ビジネスモデルに応じた最適な選択基準を提案します。
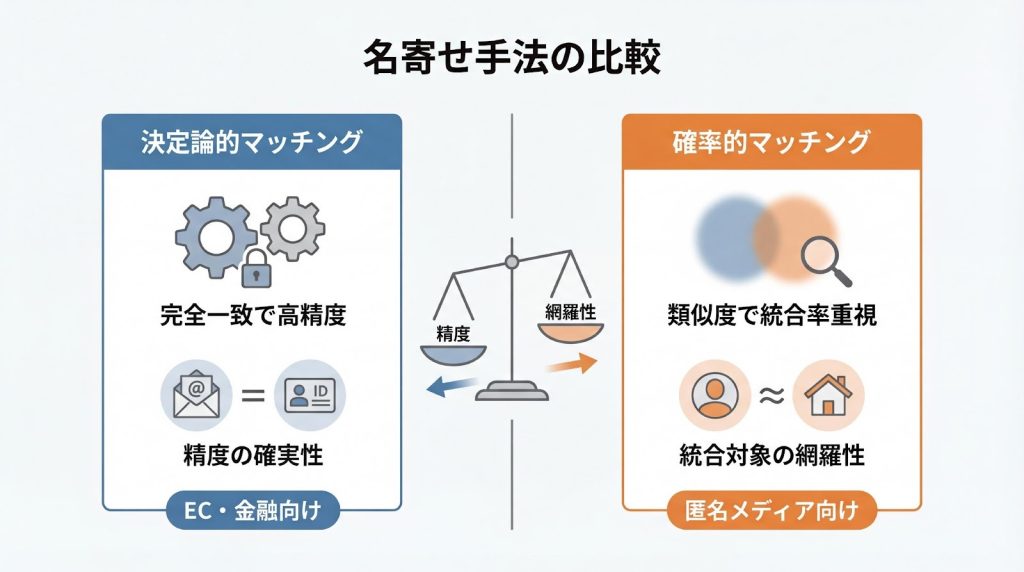
1. 決定論的マッチングの適用ケース
ID統合は、メールアドレス等の確実なキーを用いる決定論的手法を優先するのが一般的です。ECや金融等の会員制サービスでは、誤統合を防ぐため決定論的マッチングが推奨されます。会員IDやメールアドレスといった一意性の高い識別子を用いることで、異なる顧客を誤って統合するリスクを最小化できます。
決定論的マッチングでは、キー項目が完全一致した場合のみ統合を実行するため、精度は高い一方、キー項目が欠損している顧客は統合できず、統合率が低下する傾向があります。
2. 確率的マッチングの適用ケース
確率的マッチングは氏名や住所の類似度で統合し、統合率を高める補助手段として活用します。匿名ユーザーが多いメディアサイト等では、確率的手法を併用して顧客理解の解像度を上げます。
氏名、住所、電話番号などの複数項目の類似度スコアを算出し、閾値を超えた場合に統合候補として提示する仕組みが一般的です。誤統合のリスクがあるため、最終的には人間がレビューするフローを組み込むケースも多くあります。
【名寄せの優先順位付け】キー項目の優先順位付けと統合ルール定義
名寄せに使用する各項目の信頼性を評価し、統合ロジックをフローチャート化する手順を解説します。
1. キー項目の優先順位設定
キー項目の優先順位は、メールアドレス、会員ID、電話番号の順で設定するのが標準的です。メールアドレスは一意性が高いため最優先とし、補助としてCookie ID等を組み合わせます。
データソース間で情報が競合した際の優先順位(最新優先など)を要件定義で確定させます。例えば、CRMとWebサイトで顧客の住所が異なる場合、更新日時が新しい方を採用するか、信頼性の高いシステム(CRM)を優先するかを明確にします。
2. 業界特性に応じた柔軟なルール設計
業界特性に応じて、店舗POSの会員コードを最優先にする等の柔軟なルール設計が求められます。小売業では店舗会員番号、金融業では口座番号、通信業では契約者番号といった、業界固有の識別子を最優先キーとして設定するケースがあります。
複数のキー項目を組み合わせた複合キー(例:氏名+生年月日+電話番号の組み合わせ)を用いることで、単一キーでは統合できないケースにも対応できます。
【名寄せの検証】ID統合の精度検証と運用ルール
統合ルールの有効性を評価するための検証指標(適合率・再現率)と、誤統合が発生した際の修正プロセスを解説します。
1. 本番稼働前の精度検証
本番稼働前にサンプルデータで検証し、誤統合率が許容範囲内であることを確認します。統合ルールを実データに適用する前に、過去データのサンプル(例:1万件)を用いて、統合結果を人間がレビューし、誤統合の発生率を測定します。
適合率(統合した組の中で正しく統合できた割合)と再現率(統合すべき組の中で実際に統合できた割合)をKPIとして設定し、ビジネス要件に応じた閾値(例:適合率95%以上、再現率80%以上)を満たすまでルールを調整します。
2. 定期的な精度モニタリング体制
1プロファイルに異常な数の履歴が統合される等のパターンを検知し、ルールを見直します。本番稼働後も、統合結果を定期的にモニタリングし、異常なパターン(例:1人の顧客に1000件以上の購買履歴が紐付く)を検知した場合、統合ルールの見直しを実施します。
顧客からの問い合わせ(例:「購入していない商品のレコメンドが届く」)も、誤統合の兆候として捉え、該当ケースを調査・修正するプロセスを構築します。
システム連携要件とデータフロー設計の進め方
次に、CDPを中心に、MAやCRM、広告プラットフォーム、DWHとの双方向データ連携を設計します。この章では、リアルタイム性とコストのバランスを取るための判断基準と、具体的なデータフロー図の作成方法を解説します。
主要な連携先システムと連携方式の洗い出し&選定
SalesforceやGoogle広告等の主要システムとの標準的な連携パターンを紹介し、APIの制約やデータ量を考慮した現実的な連携方式の選定基準を提示します。
システム連携の設計と実装は工数が肥大化しがちですが、GENIEE CDPのように標準連携機能を豊富に備えたツールを選定することで、開発コストを抑えつつスピーディーな立ち上げが可能になります。
1. MA・広告連携の定義項目
連携方式は施策の即時性要件に基づき、リアルタイムAPIとバッチを適切に使い分けます。MA連携ではセグメント同期の頻度を、広告連携ではハッシュ化処理の有無を定義します。
例えば、Google広告へのオーディエンスリスト連携では、個人情報保護のため、メールアドレスを正規化(小文字化・前後の空白除去)した上でSHA-256によりハッシュ化してからアップロードする仕様を明記します。連携頻度は日次バッチで十分か、リアルタイム同期が必要かを施策の性質に応じて決定します。
2. DWH連携の最適化
大量データを扱うDWH連携では、差分更新やパーティション設計により負荷を最適化します。DWHは分析用、CRMは営業用、CDPは施策実行用と、各システムの役割分担を明確化します。
なお、CDPとDWHの連携は双方向で設計することが一般的です。DWHからCDPへのデータ取り込み(ELT)と、CDPの分析結果をDWHに書き戻す方向の両方を要件定義に含めてください。
全データを毎回転送するのではなく、前回連携以降の差分データのみを抽出・転送することで、ネットワーク負荷と処理時間を削減します。パーティション設計(日付や地域でデータを分割)により、必要な範囲のみをクエリできる構造を構築します。
データ連携頻度の検討|リアルタイム連携とバッチ連携の判断
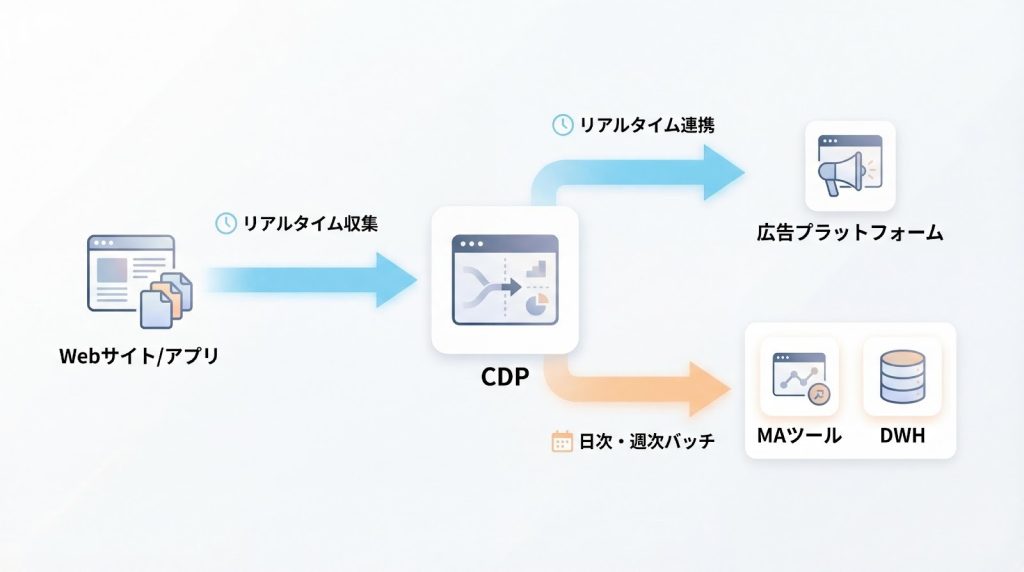
サイト離脱直後のフォロー等のリアルタイム性が求められるケースと、月次レポート等のバッチで十分なケースを切り分け、実装難易度とビジネス効果のトレードオフについて解説します。
1. リアルタイム連携が推奨されるケース
即時性が施策効果に直結するWeb接客やリタゲ広告配信には、リアルタイム連携を検討します。例えば、ECサイトでカート放棄が発生した直後に、リターゲティング広告を配信する施策では、数分以内にセグメントを更新し広告プラットフォームに連携する必要があります。
データフロー設計時には、各ステップでの加工処理(集計やフィルタリング)を明示します。リアルタイム連携では、メッセージングプラットフォーム(Apache Kafka等)とストリーム処理エンジン(Apache Flink等)を組み合わせて、イベント発生からAPI連携までの遅延を最小化する設計が求められます。
2. バッチ連携で十分なケース
属性の定期更新や集計指標の同期など、即時性が不要な項目はバッチ連携でコストを抑えます。顧客の年齢や住所といった静的な属性情報や、月次の購買集計値(月間購買金額、購買回数等)は、日次バッチで十分対応可能です。
バッチ連携では、夜間の低負荷時間帯に処理を実行することで、本番システムへの影響を最小化します。エラー発生時のリトライ処理や、失敗時の通知フローも要件定義で明確にします。
各システムの役割設計とデータフローの検討
データがどのように各システム間を流れるかを図式化し、重複投資を防ぐための役割定義を明確にします。
1. システム間の役割分担
CDPは「施策のためのデータ統合」に特化させ、重い計算処理はDWHで行う等の切り分けをします。DWHは大量データの集計・分析に最適化されており、複雑なSQLや機械学習モデルの実行に向いています。一方、CDPはセグメント抽出や外部システム連携に特化し、リアルタイム性を重視した設計とします。
CRMは営業担当者が顧客情報を参照・更新する用途に特化し、マーケティング施策の実行基盤としてはCDPを活用するといった役割分担を明確にします。
2. エラーハンドリングと通知フロー
連携エラー時のリトライ回数や、異常を検知した際の担当者への通知フローを定義します。API連携が失敗した場合、自動リトライを何回実行するか、リトライ間隔はどの程度空けるか、最終的に失敗した場合は誰に通知するかを明文化します。
データ連携の監視ダッシュボードを構築し、連携件数や処理時間、エラー発生状況をリアルタイムで可視化することで、異常の早期発見と対応を可能にします。
法令遵守とセキュリティ要件の定義
最後に、改正個人情報保護法への対応やCMPとの連携、アクセス制御といった、コンプライアンス維持に不可欠な要件を整理します。この章では、法務・情報セキュリティ部門との合意形成の進め方も提示します。
改正個人情報保護法への対応要件
2022年施行の改正法における「利用目的の特定」「第三者提供の記録義務」等の主要ポイントをCDP実務に落とし込み、開示請求へのデジタル対応など、システム側で考慮すべき要件を解説します。
なお、2026年現在、個人情報保護委員会は次期改正に向けた制度改正方針を公表しており、課徴金制度の導入や罰則強化等が検討されています。要件定義時には最新の法令動向も確認してください。
1. 第三者提供の記録義務
外部ツールへのデータ提供時には、提供先や項目、日時の記録を保管する仕組みが必要です。CDPから広告プラットフォームやMA等の外部システムにデータを連携する際、提供先システム名、提供した個人データの項目、提供日時、提供件数を記録し、一定期間保管する機能を実装します。
記録の保管期間は、法令で定められた期間(原則として3年間)を遵守し、監査や開示請求に備えて検索可能な形式で保管します。
2. 開示請求へのデジタル対応
顧客からのデータ開示・削除請求に対し、迅速かつデジタル形式で対応できるフローを構築します。顧客が自身のデータの開示を請求した場合、CDPに保管されている全データ(属性、履歴、派生指標)を抽出し、CSV等の機械可読形式で提供できる機能を実装します。
削除請求(消去請求)に対しては、該当顧客のデータを物理削除するか、論理削除(削除フラグを立てて非表示化)するかを要件定義で決定します。削除後も法令で保管が義務付けられているデータ(例:税務上の取引記録)は除外対象とするルールも明記します。
同意管理(CMP連携)とデータ保持期間の定義
Cookie同意バナー等で得たユーザーの意思を、どのようにCDPのデータ収集・活用に反映させるかを設計し、GDPRやCCPAを意識したグローバル基準のデータガバナンスについても触れます。
1. CMP連携によるデータ取得制御
CMP(同意管理プラットフォーム)と連携し、顧客の同意状態に応じたデータ取得制御を設計します。ユーザーがCookie同意バナーで「マーケティング目的のCookie」を拒否した場合、CDPへの行動データ送信を停止する仕組みを実装します。
同意が撤回された際、対象ユーザーのデータを速やかにパージまたは匿名化する機能を備えます。CMPから同意撤回の通知を受け取り、該当ユーザーのCookie IDやメールアドレスに紐付くデータを自動削除するフローを構築します。
2. データ保持期間の定義
法令要件と業務上の必要性を両立させた、適切なデータ保持期間と削除ルールを策定します。税務上の保管義務(7年等)とマーケティング上の活用期間を整理し、自動削除ロジックを組みます。
例えば、購買履歴は税務上7年間保管が必要だが、マーケティング施策では直近2年のデータのみ参照する、といった使い分けを定義します。保持期間を超過したデータは自動的にアーカイブまたは削除されるバッチ処理を実装します。
アクセス制御とセキュリティ要件の定義
データの暗号化、監査ログの取得、脆弱性診断の実施頻度など、企業のセキュリティポリシーに準拠したシステム要件を定義し、内部不正や情報漏えいを防ぐための管理体制を提示します。
1. ロールベースアクセス制御(RBAC)
ロールベースアクセス制御(RBAC)を導入し、担当者の役割に応じた最小限の権限を付与します。管理者、マーケター、閲覧者等のロール別に、参照可能なデータ範囲や操作権限を厳格に定義します。
例えば、マーケターはセグメント作成と外部連携の権限を持つが、個人情報の詳細閲覧は不可、管理者は全データへのアクセスと設定変更が可能、閲覧者はレポートの参照のみ可能、といった役割分担を明確にします。
2. 監査ログと脆弱性診断
「いつ・誰が・どのデータにアクセスしたか」を追跡できる監査ログを一定期間以上保管します。ログには、アクセス日時、ユーザーID、アクセスしたデータの種類、実行した操作(参照、更新、削除等)を記録し、不正アクセスや情報漏えいの調査に備えます。
脆弱性診断は定期的に実施し、セキュリティリスクを早期に発見・修正します。年次または半期ごとに外部のセキュリティベンダーによる診断を実施し、発見された脆弱性は優先度に応じて対応計画を策定します。
CDP導入における要件定義の進め方とポイントまとめ

本記事で解説した要件定義の重要ポイントを総括し、実務で即座に活用できる鉄則を提示します。
ビジネス要件から逆算してシステム要件を具体化することが、プロジェクト成功の鉄則です。「どのような施策を実現したいか」を起点に、必要なデータ、機能、連携先を逆算して定義することで、過剰投資や機能不足を防ぎます。
まずはチェックリストを活用して自社の現状を棚卸しし、優先順位の高い要件から詳細化に着手してください。全ての要件を一度に定義しようとせず、ビジネス価値の高い領域(例:コアな顧客セグメントのデータ統合)から段階的に進めることで、早期に成果を出しながらプロジェクトを推進できます。
要件定義から実装、運用までを一貫して成功させるには、ツールの選定も重要です。GENIEE CDPなら、豊富な導入実績に基づくノウハウと、AI活用(AX)を見据えた拡張性のあるデータ基盤で、貴社のマーケティングDXを強力に支援します。
次世代CDPの詳細や問い合わせはこちら
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。













