







名寄せロジックとは?キー設計・アルゴリズムの種類・実装手順を解説

MAやCRMに蓄積された顧客データを見ると、同じ企業が「株式会社〇〇」と「(株)〇〇」で別々に登録されていたり、同一人物のリードが複数のシステムに散在していたりすることがあります。
名寄せの必要性は感じていても、「どの項目をキーにすればいいのか」「判定ルールをどう設計するのか」という具体的な手順が見えず、作業が止まっているケースは少なくありません。
名寄せロジックは、マッチングキーの選定・判定ルールの設計・アルゴリズムの選択という3つの要素で構成されます。この3つを順番に整理することで、表記ゆれや重複の問題に対して体系的に対処できるようになります。
本記事では、名寄せロジックの基本構造から、企業・個人・ECデータ別のキー設計、アルゴリズムの選び方、Excelや専用ツールを使った実装手順、そして運用でよく起きる失敗とその回避策まで、実務に直結する内容を順に整理しています。自社のデータ状況に合った判断ができるよう、まずはキー設計の考え方から確認してみてください。
名寄せロジックとは:キー・判定ルール・アルゴリズムの3要素
名寄せロジックとは、複数のデータソースから同一のエンティティ(企業・人物・商品など)を特定し、統合するための判定体系です。
「名寄せをする」という作業は一見シンプルに見えますが、実際には①何をキーにして照合するか、②どの条件で「同一」と見なすか、③その判定をどの計算方式で実行するか、という3つの設計が揃って初めて機能します。
ロジックの設計が不十分な場合、主に3種類の問題が発生します。
- 異なるエンティティを同一と判定してしまう誤統合
- 同一エンティティを別物と判定してしまう未統合
- そして重複レコードがそのまま残存する
これらはいずれも、キー・判定ルール・アルゴリズムのどこかに設計上の穴があることで起きます。
マッチングキー:同一判定の起点となる項目
マッチングキーとは、異なるデータソース間で同一エンティティを特定するための照合項目です。キーには大きく2種類あります。
一つは一意キーで、法人番号やメールアドレスのように、それ単体で同一性を判定できる項目です。一意キーが取得できている場合は、照合の精度が高く、設計もシンプルになります。
もう一つは複合キーで、企業名・住所・電話番号のように複数の項目を組み合わせて同一性を補完する方式です。一意キーが存在しない、または取得できないデータに対して使います。
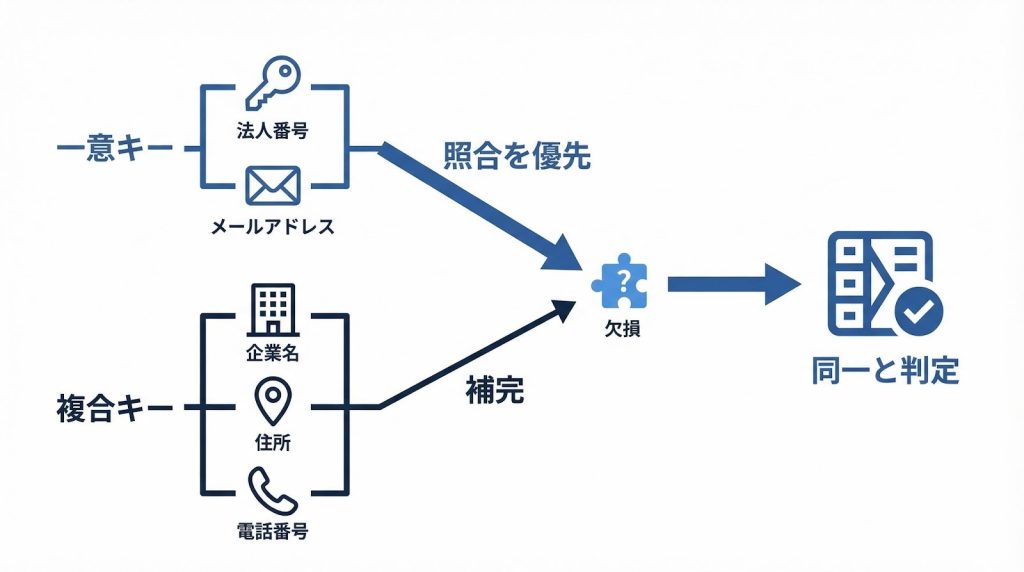
実務では、「一意キーがあればそれを優先し、なければ複合キーで補う」という優先順位を事前に設計しておくことが、キー設計の基本的な考え方になります。法人番号が登録されていない取引先や、メールアドレスが未取得のリードも多く存在するため、この優先順位を最初に決めておくことが後工程の安定につながります。
判定ルール:一致・不一致の条件定義
判定ルールとは、キー同士の比較結果をどの条件で「同一」と見なすかを定義するものです。キーが決まっても、「どこまで一致すれば同じとするか」が決まっていなければ、判定は機能しません。
判定ルールは主に3つのパターンに分かれます。
- 完全一致:文字列が完全に同じ場合のみ同一と判定する方式で、精度は高いものの、表記ゆれに弱い欠点があります。
- 部分一致:一方の文字列がもう一方に含まれていれば同一と見なす方式で、柔軟性が上がる反面、誤統合のリスクも高まります。
- スコア閾値判定:類似度をスコア化し、一定の閾値を超えた場合に同一と判定する方式で、表記ゆれへの対応力と精度のバランスを取りやすいのが特徴です。
どのパターンを選ぶかは、対象データの性質によって変わります。
法人番号のような一意コードには完全一致が適しており、企業名のような自由入力フィールドにはスコア閾値判定が向いています。データの性質ごとにルールを使い分けることが、判定精度を高める鍵です。
アルゴリズム:判定を実行する計算方式
アルゴリズムとは、判定ルールを実際に計算・実行する方式のことです。同じ「スコア閾値判定」というルールでも、どのアルゴリズムで類似度を計算するかによって、精度や処理速度、運用コストが大きく変わります。
名寄せで使われるアルゴリズムは大きく3種類に分類できます。条件を人手で定義するルールベース型、文字列の類似度をスコア化する類似度マッチング型、そして学習データからモデルを構築するAI・機械学習型です。
それぞれの仕組みと適したデータ状況については、後続の章で詳しく整理します。
マッチングキーの設計方法:何をキーにすれば同一判定できるか
名寄せロジックの精度は、キー設計の段階でほぼ決まります。どれだけ高度なアルゴリズムを使っても、照合の起点となるキーが適切でなければ、誤統合や未統合は避けられません。
キーを選ぶ際の基本的な評価軸は、一意性(その項目だけで個体を特定できるか)、取得可能性(実際のデータに存在するか)、安定性(時間が経っても変わらないか)の3つです。この3軸をすべて満たす項目を第一キーに選ぶのが原則ですが、現実のデータでそれが難しい場合は、複合キーで補完する設計が必要になります。
また、キー設計と切り離せないのが表記ゆれの問題です。「株式会社」と「(株)」、「3丁目1番地」と「3-1」のような表記の違いは、クレンジングなしではキーの一致率を大幅に下げます。マッチングを実行する前に、キー項目を正規化しておくことが前提条件となります。
以下では、企業データ・個人データ・ECデータの3つのケース別に、推奨キーと複合キーの組み合わせ方を整理します。
企業データの場合:法人番号と複合キーの使い分け
企業データの名寄せで最も信頼性が高いキーは、法人番号です。法人番号は国税庁長官が法人等(設立登記法人・国の機関・地方公共団体など)に対して1つ指定する13桁の識別番号であり、企業名や所在地が変更されても番号自体は変わりません。
一意性・安定性の両面で優れており、法人番号が取得できている場合は、これを第一キーとして使うのが最も確実な設計です。
ただし、法人番号が登録されていない取引先や、古いデータには番号が存在しないケースもあります。その場合は、企業名・所在地・電話番号を組み合わせた複合キーを使います。複合キーを設計する際は、どの項目が欠損していても残りの項目で補完できるよう、優先順位をあらかじめ決めておくことが重要です。
SFAを使った営業管理の文脈では、法人番号をキーにすることで、同一企業への重複アプローチ(営業バッティング)を防ぐ効果もあります。担当者が異なるシステムや部門で同じ企業を別レコードとして登録してしまうケースは多く、法人番号による統合はその根本的な解決策になります。
個人データの場合:メールアドレス・電話番号を第一キーにする理由
個人データの名寄せでは、メールアドレスと電話番号が第一キーとして適しています。これらは変更頻度が比較的低く、一人の個人に対して一意に割り当てられる性質があるためです。MAやCRMでリードを管理する場合、メールアドレスを主キーとして設計しているシステムが多いのも、この理由からです。
一方、氏名と生年月日の組み合わせは補助キーとして扱うのが適切です。同姓同名のリスクがある上に、生年月日が未登録のレコードも少なくありません。氏名だけで同一判定をしようとすると、誤統合の発生率が高くなります。
実務的な設計としては、「メールアドレスが一致すれば同一人物」を第一ルールとし、メールアドレスが欠損している場合は電話番号で補完、それも欠損している場合は氏名+生年月日を補助的に使う、という優先順位が一般的です。MAでのリード管理においては、フォーム入力時にメールアドレスを必須項目にすることで、第一キーの取得率を高める運用上の工夫も有効です。
ECサイト・商品データの場合:JANコード・型番・会員IDの活用
ECサイトの商品データを名寄せする場合、JANコードが最優先のキーになりますJANコードは国際標準の商品識別コード体系であるGTINの一形式(GTIN-13)であり、日本国内での呼称です。メーカーや流通システムをまたいで商品を一意に特定できます。
異なるシステム間で商品データを統合・横断分析する際に、JANコードが存在すれば照合の精度は大幅に高まります。JANコードが存在しない場合は、型番や商品名+メーカー名の複合キーで補完します。
会員データの統合では、実店舗とECサイトで会員IDが別々に管理されているケースが多く見られます。この場合、メールアドレスや電話番号を共通キーとして横断的に名寄せし、統合後の統一IDを各システムに書き戻す設計が有効です。これにより、実店舗での購買履歴とECでの行動データを同一顧客として分析できるようになり、クロスチャネルでの施策精度が向上します。
システム間でキーが異なる場合は、統合後のIDマッピングテーブルを別途管理しておくと、将来的なシステム変更や追加連携にも対応しやすくなります。
名寄せアルゴリズムの種類と選び方:ルールベース・類似度マッチング・AI型
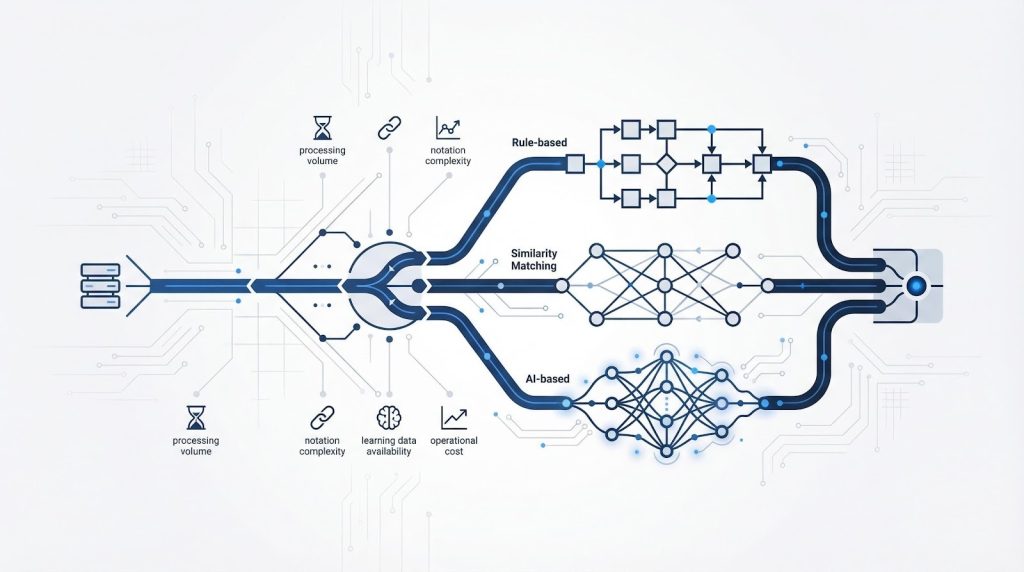
キーと判定ルールが決まったら、次はそれを実行するアルゴリズムを選びます。アルゴリズムの選択を誤ると、設計したルールが実データで機能しなかったり、運用コストが想定以上に膨らんだりします。
選択の判断軸は主に4つです。
- 処理するデータの量
- 表記ゆれの複雑さ
- 学習データを準備できるかどうか
- 継続的な運用にかけられるコスト
この4軸が交差する点に、自社のデータ状況に合った方式があります。以下の比較表を参考に、各アルゴリズムの特徴を確認してください。
| 方式 | 仕組み | 適したデータ状況 | 主な実装手段 | 運用コスト |
| ルールベース型 | 条件を人手で定義して判定 | 少量・表記パターンが限定的 | Excel・CRM標準機能 | 低〜中(ルール増加で上昇) |
| 類似度マッチング型 | 文字列の類似度をスコア化して閾値判定 | 表記ゆれが多くルールで網羅しきれない | Pythonライブラリ・専用ツール | 中(閾値チューニングが必要) |
| AI・機械学習型 | 学習データからモデルを構築して自動判定 | 大量・複雑な表記ゆれ・学習データあり | 専用ツール・CDP | 高(学習データ準備コストあり) |
ルールベース型:条件を人手で定義する方式
ルールベース型は、「企業名が完全一致かつ電話番号の上7桁が一致する場合は同一とする」のように、判定条件を人手で明文化して実行する方式です。条件がコードやドキュメントとして可視化されるため、なぜその判定になったかを後から追跡しやすく、透明性が高いのが特徴です。
適しているのは、データ量が少なく、表記パターンがある程度限定されている場合です。たとえば、社内の特定部門が管理する数千件規模の顧客リストや、入力ルールが統一されているシステムのデータなどが該当します。
一方で、想定外の表記ゆれには対応できません。「㈱」や「有限会社」の略称、住所の丁目・番地の書き方のバリエーションなど、ルールに定義されていないパターンが出てくるたびに、条件を追加する必要があります。ルールが増えるほど管理コストが上昇し、矛盾するルールが生まれるリスクも高まります。データ量が増えたり、入力元が多様化したりした段階で、他の方式への移行を検討するタイミングになります。
類似度マッチング型:スコアで同一性を判定する方式
類似度マッチング型は、文字列同士の「どれだけ似ているか」をスコアとして計算し、設定した閾値を超えた場合に同一と判定する方式です。ルールベース型では網羅しきれない表記ゆれに対応できるのが最大の利点です。
代表的な計算手法として、レーベンシュタイン距離(一方の文字列をもう一方に変換するために必要な「挿入・削除・置換」の最小操作回数で類似度を表す手法)、Jaccard係数(2つの集合の和集合に占める共通要素(積集合)の割合)、N-gram(文字列をN文字の連続部分列として列挙し、その集合の一致度で類似度を計算する方法)などがあります。
たとえば「株式会社山田商事」と「(株)山田商事」のような表記ゆれは、完全一致では検出できませんが、N-gramやレーベンシュタイン距離を使えば高いスコアが得られます。この方式で精度を左右するのは、閾値の設定です。閾値を高くすると誤統合(false positive)は減りますが、同一エンティティを見逃す未統合(false negative)が増えます。
逆に閾値を低くすると未統合は減りますが、誤統合が増えます。この関係は適合率(Precision:正と判定した中で実際に正である割合)と再現率(Recall:実際に正であるものを正と判定できた割合)のトレードオフとして知られており、実データを使ったチューニングで調整する必要があります。この作業を省略すると期待した精度が出ません。
AI・機械学習型:学習データから判定モデルを構築する方式
AI・機械学習型は、「同一である」「同一でない」というラベルを付けた学習データをもとに判定モデルを構築し、新しいデータに対して自動的に同一性を判定する方式です。ルールベース型や類似度マッチング型では対応しきれない、大量かつ複雑な表記ゆれのパターンに対処できます。
適しているのは、データ量が多く、表記ゆれのパターンが多様で、かつ正解ラベル付きの学習データを準備できる環境です。学習データの質と量が精度を直接左右するため、「とりあえずAI型を使えば精度が上がる」という考え方は危険です。学習データの準備と品質管理が、導入の主なハードルになります。
GENIEE CDPのような高度な分析基盤を持つCDPは、AI型の名寄せアルゴリズムを実装しており、学習データ準備のハードルをプリセット機能で軽減している場合があります。自社でゼロからモデルを構築するのが難しい場合は、こうしたツールの活用も選択肢の一つです。
名寄せロジックの実装手順:データ調査からマッチング・統合までの4ステップ
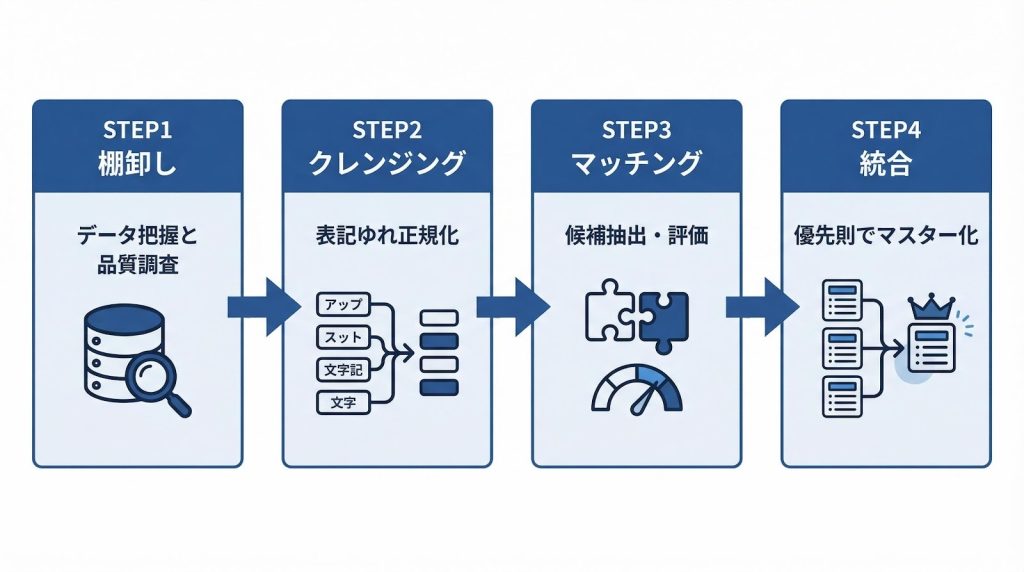
名寄せロジックの設計が固まったら、実際のデータへの適用に移ります。実装は大きく4つのステップで進みます。対象データの棚卸しと品質調査、データクレンジング、マッチングキーによる候補ペア抽出とスコアリング、そして統合ルールに基づくマスターレコードの作成です。
実装手段の選択は、データ量・更新頻度・技術リソースの3軸で判断します。少量かつ更新頻度が低いデータはExcelで対応でき、中規模のデータはCRM/SFAの標準機能が使えます。大量データや複数システムにまたがる統合が必要な場合は、専用ツールの導入を検討します。
ステップ1:対象データの棚卸しと品質調査
最初のステップは、どのシステムにどのようなデータが存在するかを把握することです。SFA・MA・CRM・名刺管理ツールなど、顧客データが存在するすべてのシステムを洗い出し、各システムのデータ項目・件数・重複率・欠損率を一覧化します。
品質調査で特に確認すべきは、キー候補項目の取得可能性と品質です。法人番号やメールアドレスが何割のレコードに存在するか、企業名や住所にどのような表記ゆれのパターンがあるかを事前に把握しておくことで、キー設計とクレンジング計画の精度が上がります。
棚卸しの結果として、「このシステムには法人番号が存在しないため複合キーを使う」「メールアドレスの欠損率が高いため電話番号を補助キーにする」といった判断が具体的にできるようになります。この段階を省略して実装に進むと、後工程で設計の見直しが必要になるケースが多いため、丁寧に進めることが重要です。
ステップ2:データクレンジング(キー項目の前処理)
クレンジングはマッチング精度を直接左右する前処理工程です。どれだけ精巧な判定ルールを設計しても、キー項目に表記ゆれや不要な文字が残っていれば、一致率は大幅に下がります。
キー項目に対して実施すべき処理は主に4つです。全角・半角の統一、空白の除去、法人格表記の統一(「株式会社」「(株)」「㈱」を同一表記に揃える)、そして住所の正規化(丁目・番地・号の表記統一)です。これらをマッチング実行前に必ず適用します。
Excelでクレンジングを実装する場合、次の関数の組み合わせが実用的です。
- JIS関数:半角文字を全角に変換(またはASC関数で全角を半角に統一)
- TRIM関数:文字列の前後および連続する空白を除去
- CLEAN関数:印刷できない制御文字を除去
- SUBSTITUTE関数:「(株)」を「株式会社」に置換するなど、特定の文字列を一括変換
これらを組み合わせた数式をクレンジング用の列に適用し、元データは保持したまま正規化済みの値をキー列として使うのが、後から修正しやすい設計です。クレンジングの処理内容と適用範囲はドキュメントとして残しておくと、別担当者が引き継ぐ際にも役立ちます。
ステップ3:マッチングキーによる候補ペア抽出とスコアリング
クレンジング済みのデータにキーを適用して、同一候補のペアを抽出します。実装手段によって操作方法が異なるため、自社のデータ量と技術リソースに合わせて選択してください。
Excel での実装
少量データの場合、Excelの関数を組み合わせることで重複検出と候補ペア抽出を実装できます。COUNTIF関数でキー項目の出現回数を数えて重複候補を特定し、VLOOKUPまたはINDEX-MATCH関数で別シートや別列のデータと突合します。
複合キーを使う場合はCONCATENATE関数(または&演算子)で複数項目を結合した照合キーを生成し、条件付き書式で重複箇所を色分けして可視化すると確認作業が効率化されます。
CRM/SFA 標準機能での実装
Salesforceの場合、「重複ルール」と「一致ルール」を組み合わせることで、レコード登録時に重複候補を自動検出できます。一致ルールで照合するフィールドと一致条件(完全一致・部分一致など)を定義し、重複ルールでその結果に対してアラートを出すか自動ブロックするかを設定します。
ただし、この機能はルールベースおよびあいまい一致(ファジーマッチ)の判定に対応していますが、機械学習モデルを用いたAI型の判定には対応していません。複雑な表記ゆれが多いデータには限界があります。複雑な表記ゆれが多いデータには限界があります。
専用ツールでの実装
複数システムにまたがるデータを統合する場合や、リアルタイムでの名寄せが必要な場合は、専用ツールの活用が現実的です。GENIEE CDPはノーコードで複数システムのデータを連携し、ID名寄せ機能によって手動やCRM標準機能では対応が難しい、複数システムにまたがるデータのリアルタイム統合を実現します。SFA・MA・ECシステムなど異なるプラットフォームのデータを一元管理したい場合に有効な選択肢です。
顧客データが複数のシステムに分散していて集約に手間がかかっているケースや、社内に分析専門家がおらずデータ活用の進め方に迷っているケースでは、導入支援チームによる要件定義と運用支援チームによる伴走サポートが整っている点も、選定時の判断材料になります。
ステップ4:統合ルールに基づくマスターレコードの作成
マッチングで同一と判定されたペアを、どのルールで1件に統合するかを決めます。統合ルールを事前に決めておかないと、担当者によって判断が変わり、データの一貫性が失われます。
統合ルールの代表的なパターンは3つです。最新日付優先は更新日時が新しいレコードの値を採用する方式で、最新情報を維持したい項目(電話番号・住所など)に適しています。入力元優先は特定のシステム(例:SFAのデータを正とする)の値を優先する方式で、信頼性の高いシステムが明確な場合に使います。項目別優先は項目ごとに異なるルールを設定する方式で、「企業名はSFA優先、電話番号はCRM優先」のように細かく制御できます。
スコアが閾値付近の候補ペアは、自動統合せずに人手レビューを挟むことを推奨します。閾値ぎりぎりの判定は誤統合のリスクが高く、特に個人データの場合は別人の情報が混入する可能性があります。レビュー対象の件数が多い場合は、スコアの高い順に自動統合し、閾値付近のみ人手確認するという段階的な設計が現実的です。
統合後のマスターレコードをSFAやMAにインポートする際は、既存レコードとの紐付けキーを明確にし、重複フラグや統合履歴を別フィールドで管理しておくと、後から統合の経緯を追跡できます。
名寄せロジック設計でよくある失敗と回避策

名寄せの実装経験がある担当者でも、同じ失敗パターンに繰り返し陥ることがあります。問題の多くは設計段階での見落としに起因しており、事前に把握しておくことで対策が取れます。
ここでは代表的な4つの失敗パターンを、発生原因・影響・回避策のセットで整理します。
失敗1:クレンジング不足のままマッチングを実行し精度が出ない
名寄せの精度が出ない原因として最も多いのが、クレンジング不足です。「マッチングを実行したが重複が検出されない」という状況の多くは、キー項目に表記ゆれや余分な文字が残っているために、同一データが別物として扱われています。
マッチング実行前に、次の4項目をチェックリストとして確認してください。
- 全角・半角の統一(特に数字・カタカナ・英字)
- 空白の除去(前後の空白・文字間の連続空白)
- 法人格表記の統一(「株式会社」「(株)」「㈱」「KK」を同一表記に揃える)
- 住所形式の統一(「丁目・番地・号」と「-」の混在を解消する)
これらの処理をキー項目に対して適用してからマッチングを実行することで、クレンジング不足による精度低下の大半は防げます。クレンジングの処理内容と適用範囲は、ドキュメントとして残しておくと、後から別担当者が引き継ぐ際にも役立ちます。
失敗2:キー設定が甘く誤統合(false positive)が発生する
誤統合とは、本来は異なるエンティティを同一と判定してしまうことです。たとえば、同じビルに入居する別会社が「企業名の一部+住所」の複合キーで同一と判定されたり、類似した名前の別人が氏名だけで統合されたりするケースが該当します。
発生原因は主に2つです。キーの一意性が低い(その項目の組み合わせだけでは個体を特定しきれない)か、類似度マッチングの閾値が低すぎるかのどちらかです。
回避策として有効なのは、複合キーの項目数を増やして一意性を高めること、閾値を段階的に上げながら誤統合率を確認するチューニング、そして閾値付近の候補ペアへの人手レビューの3点です。特に、初めて名寄せを実施する場合は、閾値を高めに設定して誤統合を抑えつつ、未統合の候補を人手で確認するアプローチが安全です。慣れてきたら閾値を調整して自動化の範囲を広げていくのが現実的な進め方です。
失敗3:個人情報の誤統合によるプライバシーリスク
個人データの名寄せで誤統合が発生すると、別人の情報が同一プロファイルに混入します。これは単なるデータ品質の問題にとどまらず、不正確なプロファイリングに基づいたコミュニケーションや、個人情報の取り扱いに関するリスクにつながります。
名寄せによって当初の利用目的の範囲を超える形で個人情報を統合する場合は、個人情報保護の観点から慎重な対応が必要です。統合の目的・範囲・対象データを事前に整理し、必要に応じて社内の法務・コンプライアンス担当と確認を取ることを推奨します。
運用面での回避策として、統合前の人手レビュープロセスを設計することと、統合ログを保持することが重要です。統合ログがあれば、誤統合が発覚した際に「いつ・どのデータが・どのルールで統合されたか」を追跡でき、是正作業を迅速に進められます。個人データを扱う名寄せでは、自動化の範囲を広げる前に、レビューと記録の仕組みを先に整えることが優先事項です。
失敗4:一度きりの名寄せで終わり新規データの重複が再発する
名寄せを単発の作業として実施した場合、その後に新規データが追加されるたびに重複が再発します。「先月名寄せをしたのに、また重複が増えている」という状況は、継続的な運用設計がないことが原因です。
根本的な解決策は、名寄せを継続的なプロセスとして設計することです。具体的には、新規レコードが追加された際に自動でマッチングチェックを実行する仕組みと、定期的(月次・週次など)に全件を再マッチングするバッチ処理の2つを組み合わせます。どちらか一方だけでは、漏れが生じやすくなります。
もう一つ有効なのが、データ登録時の入力ルールを標準化することです。「企業名は正式名称で入力する」「住所は都道府県から記載する」といったルールを登録フォームや運用マニュアルに明記することで、そもそも表記ゆれが発生しにくい環境を作れます。名寄せの運用コストを長期的に下げるには、重複を検出・統合する仕組みと、重複を発生させない入力設計の両方が必要です。
まとめ

この記事では、名寄せロジックを構成するキー・判定ルール・アルゴリズムの3要素から始まり、データ種別ごとのキー設計、アルゴリズムの選び方、4ステップの実装手順、そして運用でよく起きる失敗パターンまでを整理しました。
自社のデータ状況に合った名寄せロジックを選ぶ際の判断軸は、データ量・表記ゆれの複雑さ・更新頻度の3つです。この3軸を組み合わせると、おおよその方向性が見えてきます。
| データ量 | 表記ゆれの複雑さ | 更新頻度 | 推奨する実装手段とアルゴリズム |
| 少量 | 単純 | 低 | Excel + ルールベース型 |
| 中規模 | 中程度 | 中 | CRM標準機能 + 類似度マッチング型 |
| 大量 | 複雑・多様 | 高 | 専用ツール + AI型 |
「大量・複雑・高頻度」に該当する環境では、GENIEE CDPのような専用の統合基盤が選択肢になります。名寄せの継続運用だけでなく、統合後の分析やMA連携までシームレスに対応できる点が、専用ツールを選ぶ主な理由です。
顧客データの集約から分析・施策実行までを一貫して支援する導入・運用サポート体制も整っており、ロジック設計に不安がある場合でも要件定義から伴走してもらえます。
どの手段を選ぶにしても、最初のアクションは対象データの棚卸しです。どのシステムに何件のデータがあり、キー候補項目がどの程度の品質で存在するかを把握することが、キー設計とアルゴリズム選択の前提になります。まずは自社のデータ状況を一覧化するところから始めてみてください。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。













