データレイクとデータウェアハウスの違いとは?選び方と使い分けを解説

データレイクとデータウェアハウス(DWH)は、いずれも企業のデータ活用基盤として広く利用されていますが、それぞれが果たす役割や得意とする領域は大きく異なります。データの「形式」や「構造化の度合い」、さらには「分析の目的」によって、どちらを選ぶべきか、あるいは両者をどう組み合わせるべきかの判断が求められます。
本記事では、データレイクとDWHの定義と役割の違いを整理したうえで、構造化データと非構造化データによる選択基準、スキーマ適用タイミングの違い、データフロー全体像、利用目的別の使い分け、そして最新のデータレイクハウスのトレンドまでを体系的に解説します。
データレイクは生データの蓄積、DWHは分析用データの管理に適しており、目的とデータ形式に応じた使い分けや統合(レイクハウス)が重要です。
顧客データ活用に特化して迅速に成果を出したい場合は、これらを包含したGENIEE CDPのような統合基盤の導入も有力な選択肢となります。この機会にぜひCDPもご検討ください。
CDPツール比較15選!おすすめランキング・機能・選び方を徹底解説
データレイクとデータウェアハウス(DWH)の定義と役割の違い
データレイク、DWH、データマートは、いずれも企業のデータ活用基盤を構成する重要な要素ですが、それぞれが担う役割は明確に異なります。この章では、各用語の定義を整理し、生データの保管から分析用加工、部門別最適化までの全体像を把握していきます。
データレイクとは:あらゆるデータを生の形式で保管する貯蔵庫
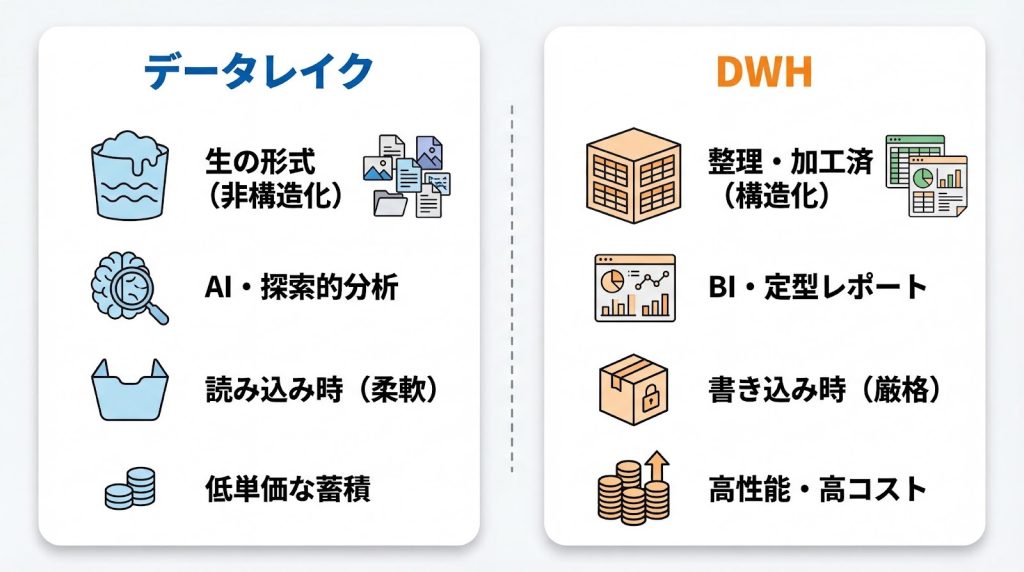
データレイクは、多様な生データを元の形式(Raw Data)のまま保存する柔軟な保管領域です。構造化データだけでなく、画像、音声、ログファイル、JSON形式のデータなど、あらゆる種類のデータを変換せずに蓄積できる点が最大の特徴となります。
主要なクラウドプラットフォームでは、Amazon S3、Azure Data Lake Storage、Google Cloud Storageといったオブジェクトストレージがデータレイクの実装基盤として広く活用されています。これらのストレージは低コストで大容量のデータを保持でき、将来的な用途が未定のデータであっても、とりあえず蓄積しておくことが可能です。
用途が未定のデータも非構造化データのまま蓄積でき、将来的なAI解析や探索的分析に備えることが可能です。データの形式やスキーマを事前に定義する必要がないため、新しいデータソースの追加や分析要件の変化にも迅速に対応できます。
データウェアハウス(DWH)とは:分析目的に最適化されたデータ保管庫
データウェアハウス(DWH)は、ビジネス分析を主眼に置き、事前に定義されたスキーマに基づいて構造化データを管理する保管庫です。データレイクとは対照的に、データを格納する前に整理・加工し、分析に適した形式に変換してから保存します。
事前に定義されたスキーマに基づき構造化データを管理するため、定型的なBIレポート作成や集計を高速に行えます。売上データ、顧客情報、在庫データといった定型的なビジネスデータを、一貫性のある形式で保持することで、誰が分析しても同じ結果が得られる「信頼できる唯一の情報源(Single Source of Truth, SSOT)」としての役割を果たします。
列指向データベースやインメモリ処理といった高速クエリを実現するアーキテクチャが採用されており、大量のデータに対する集計や複雑な結合処理を短時間で実行できます。BIツールとの連携が容易で、ダッシュボードやレポートの作成を効率的に行える点も大きな利点です。
データマートとの関係:データレイク→DWH→データマートの階層構造
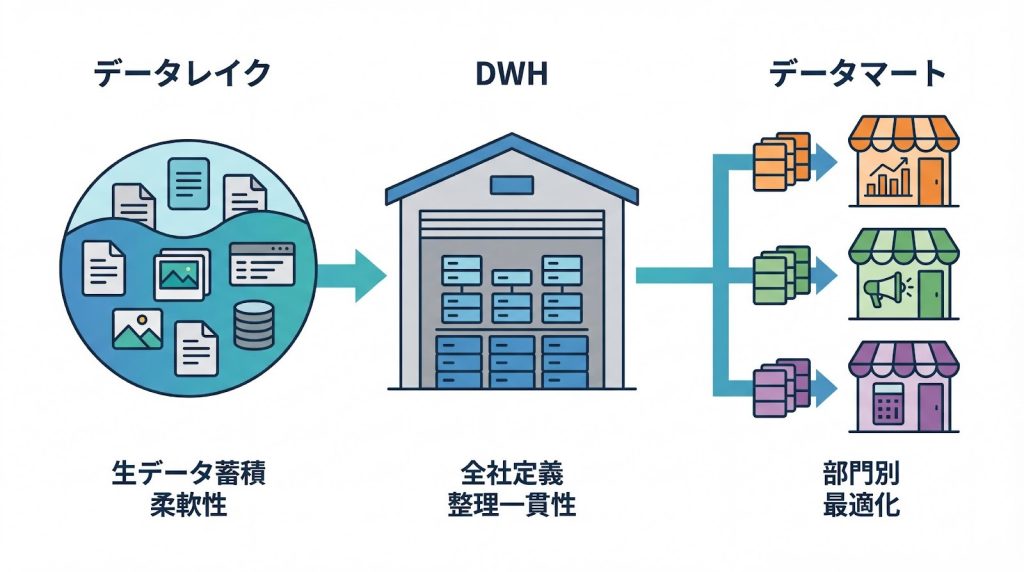
データマートは、DWHからさらに特定部門や特定の分析目的に向けて切り出された、より専門化されたデータ保管領域です。営業部門向けの売上分析マート、マーケティング部門向けの顧客行動分析マートといった形で、各部門が必要とするデータのみを集約し、使いやすい形式で提供します。
データレイクで柔軟性を、DWHで全社的な一貫性を、データマートで部門ごとの使い勝手を担保する役割分担が重要です。データレイクには生データを幅広く蓄積し、DWHで全社共通の指標や定義に基づいて整理し、データマートで各部門の業務に最適化した形でデータを提供する、という階層的な流れを設計することで、柔軟性と一貫性を両立させることができます。
この階層構造により、データサイエンティストは生データに直接アクセスして探索的分析を行い、ビジネスアナリストはDWHやデータマートの整理されたデータを用いて定型レポートを作成する、といった役割分担が実現します。
なお、特に顧客データの活用においては、これらの機能を統合したCDP(カスタマーデータプラットフォーム)という選択肢も有効です。GENIEE CDPのように、データの収集・統合から分析・施策実行までを一気通貫で行える基盤を活用することで、複雑な階層構造を意識することなく、スムーズにデータをビジネス価値へ変換できます。
データレイク vs データウェアハウスの選定基準
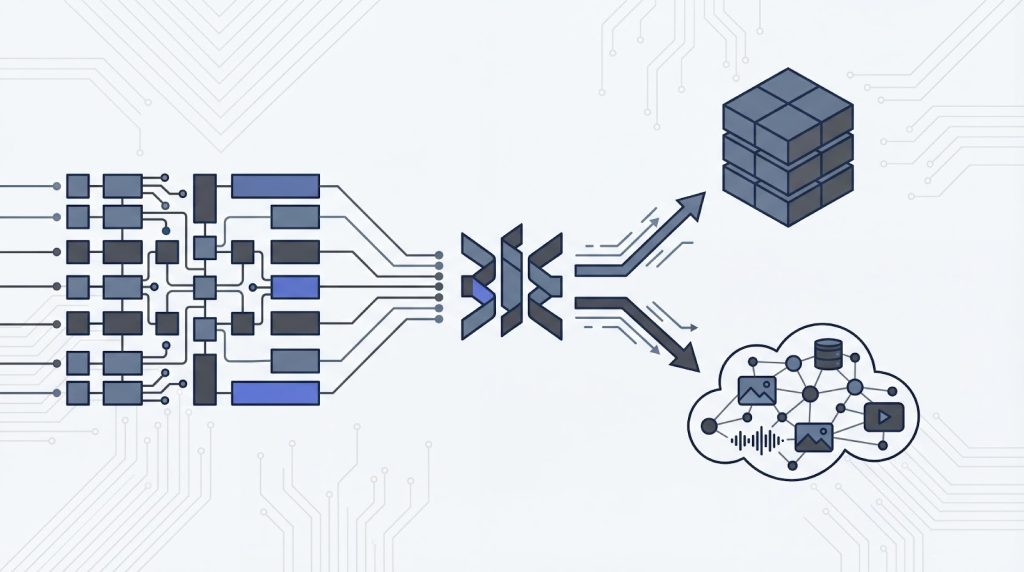
データの「形式」を主軸に、データレイクとDWHのどちらを選択すべきかの判断基準を整理します。
この章では、構造化データと非構造化データの違い、それぞれの基盤が適している理由、そしてコスト面やストレージの特性比較を行います。
構造化データと非構造化データの違い
データの性質(定型か非定型か)を正しく分類することが、適切な基盤設計の第一歩となります。自社が扱うデータの大半が定型的な業務データであればDWH中心の設計が、多様な形式のデータを蓄積する必要があればデータレイク中心の設計が適しています。
構造化データとは、RDB(リレーショナルデータベース)のように、行と列で明確に定義されたテーブル形式のデータを指します。顧客ID、氏名、購入日、金額といった項目が固定され、各レコードが同じ構造を持つため、集計や検索が容易です。
一方、非構造化データは、画像、音声、動画、テキストファイル、ログファイルなど、定型的な構造を持たないデータです。これらは形式が多様で、そのままでは集計や検索が難しいものの、AI解析やテキストマイニングといった高度な分析により、新たな価値を引き出せる可能性を秘めています。
データレイクが非構造化データに適している理由
データレイクは、スキーマレス設計により、非構造化データの保管に大きな利点を持ちます。画像や音声などの大容量データを変換コストをかけずに保管でき、後から必要な情報を抽出する柔軟性に優れます。
例えば、カスタマーサポートの通話音声データをそのまま蓄積しておき、後からAIによる感情分析や頻出キーワード抽出を行う、といった活用が可能です。データを格納する時点では用途が明確でなくても、将来的な分析ニーズに備えて保管しておくことができます。
また、オブジェクトストレージは低コストで大容量のデータを保持できるため、非構造化データの長期保管に適しています。データの増加に応じてストレージを柔軟に拡張でき、運用負荷も低く抑えられます。
DWHが構造化データに適している理由
DWHは、スキーマ定義によるデータ品質の担保と、BI分析におけるパフォーマンス上の優位性を持ちます。売上や顧客情報など、一貫性と正確性が求められる定型データの高速集計・分析においてDWHは不可欠です。
事前にスキーマを定義することで、データの整合性チェックや重複排除が自動化され、データ品質が保証されます。これにより、エンドユーザーは安心してデータを分析に利用でき、誤った判断を下すリスクが低減されます。
列指向ストレージやインメモリ処理といった技術により、大量のレコードに対する集計や複雑な結合処理を短時間で実行できます。BIツールとの連携も容易で、ダッシュボードやレポートの作成を効率的に行えます。
コストとストレージの柔軟性による選択
クラウドベンダーが提供するオブジェクトストレージとDWH専用ストレージは、コスト構造が大きく異なります。大量の生データ蓄積には低単価なオブジェクトストレージ、高頻度な分析には高性能なDWHストレージを使い分けるのが経済的です。
オブジェクトストレージは、データの保管コストが非常に低く、長期間のデータ保持に適しています。一方、DWH専用ストレージは、高速なクエリ処理を実現するために最適化されており、頻繁にアクセスされるデータの保管に向いています。
データのアクセス頻度やライフサイクルに応じて、ストレージ階層を使い分けることで、コストを最適化しながら必要なパフォーマンスを確保できます。例えば、直近1年分のデータはDWHに保持し、それ以前のデータはデータレイクにアーカイブする、といった運用が一般的です。
スキーマ適用タイミングから見るデータレイクとDWHの違い
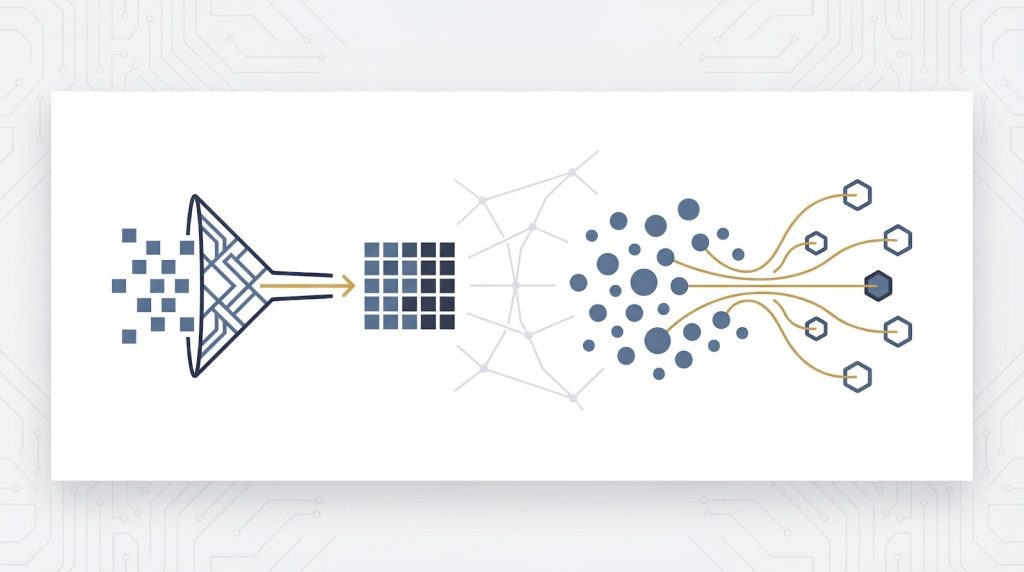
書き込み時に定義するSchema-on-Write(DWH)と、読み込み時に解釈するSchema-on-Read(データレイク)の技術的な違いと実務への影響を詳述します。
この章では、それぞれのアプローチのメリット・デメリット、開発工数・データ品質・柔軟性のトレードオフ、そしてETLとELTの処理フローの違いを整理します。
Schema-on-Write(DWH):データ書き込み時にスキーマを定義
Schema-on-Writeは、データをDWHに格納する前に、あらかじめスキーマ(データ構造)を定義し、そのスキーマに従ってデータを変換・検証してから保存するアプローチです。データの整合性が保証されるため、エンドユーザーが安心して分析に利用できる環境を構築しやすい特徴があります。
書き込み時にスキーマを定義することで、データ型の不一致や欠損値、重複レコードといった問題を事前に検出し、修正できます。これにより、分析時にデータ品質の問題に悩まされるリスクが低減されます。
一方で、スキーマの設計には時間と労力がかかり、ビジネス要件の変化に応じてスキーマを変更する際には、既存データの再処理やETLパイプラインの修正が必要となります。初期の設計工数が大きく、変更コストも高い点がデメリットです。
Schema-on-Read(データレイク):データ読み込み時にスキーマを解釈
Schema-on-Readは、データをそのままの形式でデータレイクに保存し、分析時にスキーマを解釈するアプローチです。事前の定義が不要なため迅速にデータ蓄積を開始でき、変化の激しい分析要件にも柔軟に対応可能です。
データを格納する時点ではスキーマを定義する必要がないため、新しいデータソースの追加や、試行的なデータ収集を素早く開始できます。分析要件が変わった場合でも、既存のデータを再処理することなく、新しいスキーマで読み込み直すことができます。
一方で、データの整合性や品質の担保は分析者の責任となり、分析時にデータのクレンジングや変換処理が必要となります。また、同じデータに対して異なるスキーマで解釈されるリスクがあり、分析結果の一貫性を保つための管理が課題となります。
実務への影響:開発工数・データ品質・柔軟性の比較
Schema-on-WriteとSchema-on-Readは、開発工数、データ品質、柔軟性の観点で異なるトレードオフを持ちます。プロジェクトのフェーズや目的(定型分析か探索的分析か)に応じた使い分けが重要です。
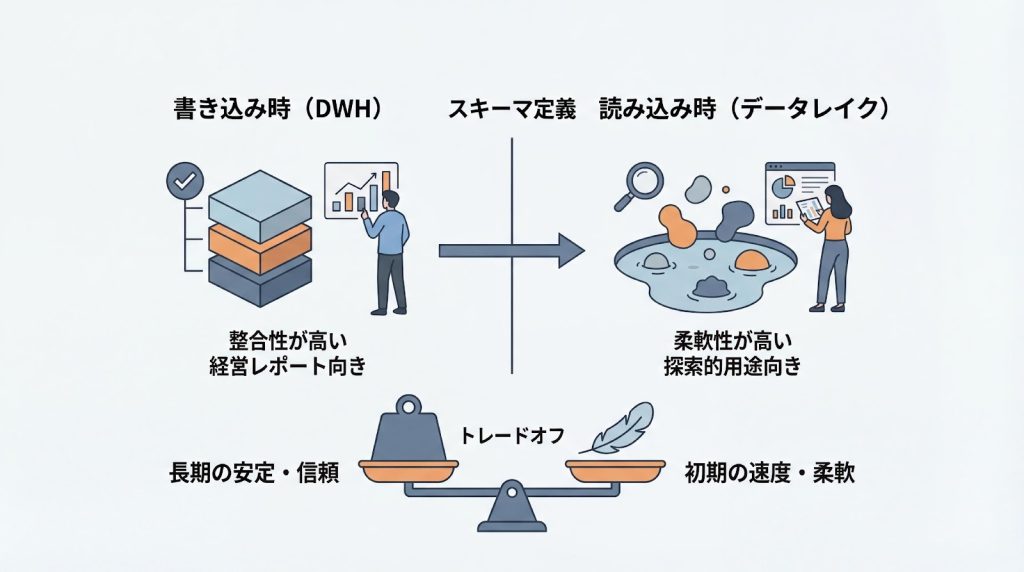
初期スピード重視ならSchema-on-Read、長期的な運用安定性と品質重視ならSchema-on-Writeが適しています。例えば、新規事業の立ち上げ期で分析要件が頻繁に変わる場合はSchema-on-Readが有利ですが、既存の定型レポートを安定的に提供する必要がある場合はSchema-on-Writeが適しています。
実際には、両者を組み合わせたハイブリッドアプローチも有効です。データレイクに生データを蓄積しつつ、頻用する分析セットのみをDWHに自動同期させることで、柔軟性と品質の両立を図ることができます。
データフローとアーキテクチャの全体像(データレイク→DWH→データマート)

データが各層を流れるプロセスと、運用上の最大の障壁である「データスワンプ化」を防ぐためのガバナンス設計について解説します。この章では、一般的なデータフロー、各フェーズでのデータ保持形式、ガバナンスの重要性、そしてクラウドプラットフォーム別の実装例を紹介します。
データレイク→DWH→データマートの一般的なデータフロー
ソースから収集、蓄積、整理、最適化へと至る標準的なパイプラインは、以下のような流れで構成されます。各層でデータの「鮮度」と「純度」を管理し、目的に応じた適切なデータを提供できる流れを設計します。
まず、各種データソース(業務システム、Webサイト、IoTデバイスなど)からデータを抽出し、データレイクに生の形式で保存します。この段階では、データの変換や加工は行わず、そのままの形式で蓄積します。
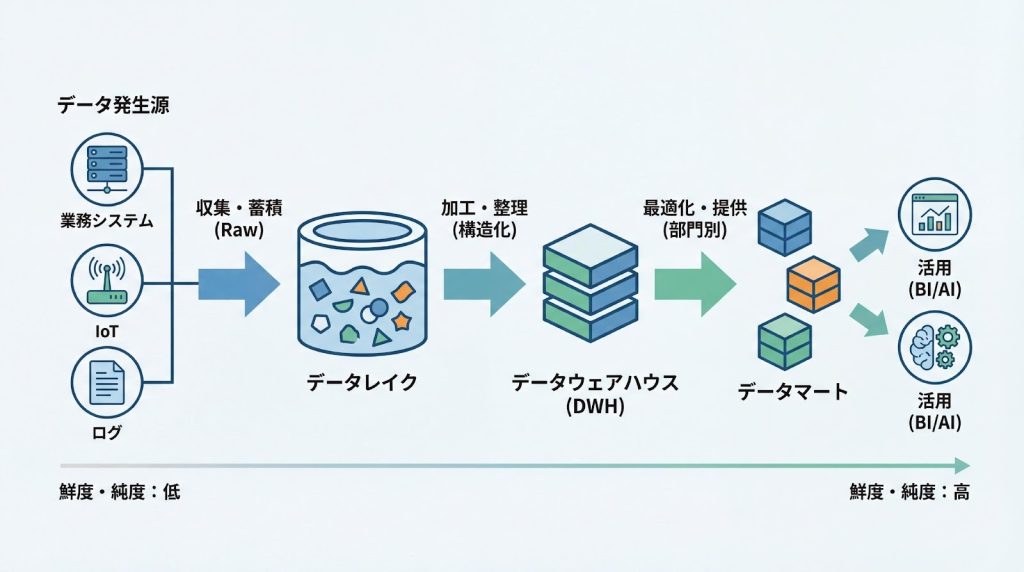
次に、データレイクから必要なデータを抽出し、クレンジング、変換、統合といった処理を経て、DWHに格納します。DWHでは、全社共通の定義に基づいてデータを整理し、一貫性のある形式で保持します。
最後に、DWHから特定部門や特定の分析目的に向けて必要なデータを切り出し、データマートに格納します。データマートでは、各部門が使いやすい形式でデータを提供し、迅速な分析を可能にします。
各フェーズでのデータ保持形式と処理
データの状態変化に応じて、Raw(生)、Curated(整理済み)、Aggregated(集計済み)といった保持形式を使い分けます。Apache Parquet(列指向)やAvro(行指向)などのオープンフォーマットを用途に応じて活用することで、ストレージ効率とクエリ性能を両立させます。
Rawデータは、データレイクに保存される生の形式のデータです。JSON、CSV、ログファイル、画像、音声など、多様な形式のデータがそのまま保持されます。
Curatedデータは、Rawデータをクレンジング・変換し、分析に適した形式に整理したデータです。不要なカラムの削除、データ型の統一、欠損値の補完などが行われ、DWHに格納されます。
Aggregatedデータは、Curatedデータをさらに集計・要約したデータです。日次売上、月次顧客数、地域別集計といった形で事前に集計され、データマートに格納されます。これにより、レポート作成時の処理負荷を軽減できます。
データガバナンスとスワンプ化回避策
データレイクが「泥沼(スワンプ)」化するのを防ぐためには、メタデータ管理やアクセス制御が不可欠です。「誰が、いつ、何の目的で」入れたデータかをカタログ化し、常に検索可能な状態を維持することが重要です。
メタデータ管理では、各データセットの作成者、作成日時、更新履歴、データソース、スキーマ情報、利用目的などを記録します。これにより、データの来歴を追跡でき、信頼性を担保できます。
アクセス制御では、データの機密性に応じて適切な権限を設定し、不正なアクセスやデータ漏洩を防ぎます。また、データの利用状況をモニタリングし、不要なデータは定期的に削除することで、ストレージコストを最適化できます。
こうした厳密なガバナンス設計とパイプライン構築には、相応のエンジニアリング工数が必要です。もし構築リソースが不足している場合は、GENIEE CDPのような統合プラットフォームの活用が推奨されます。データ収集から統合・カタログ化までのプロセスが自動化されており、スワンプ化のリスクを最小限に抑えながら、安全なデータ活用環境を即座に構築できます。
データレイクハウスについて

データレイクハウスは、データレイクの柔軟性とDWHのデータ管理機能を統合した新しいアーキテクチャです。
この章では、データレイクハウスの定義、導入時の検討ポイント、そして実際の導入事例を取り上げます。
データレイクハウスとは:データレイクとDWHの利点を統合
従来、データレイクとDWHは別々のシステムとして運用され、データの重複や管理コストの増大が課題となっていました。データレイクハウスは、単一の基盤でBIとAIの両方のニーズを満たすことで、これらの課題を解決します。
ACID(Atomicity・Consistency・Isolation・Durability:原子性・一貫性・独立性・永続性)トランザクションのサポートにより、データの一貫性と信頼性が保証され、DWHと同等のデータ品質を実現できます。また、スキーマ管理機能により、データの構造を柔軟に変更しながらも、過去のデータとの互換性を維持できます。
データレイクハウスのメリットと導入時の検討ポイント
単一のデータソースで全ユースケースをカバーできるメリットは大きいですが、既存資産からの移行は段階的に行うべきです。一元管理によるコスト削減効果と、一方で必要となる高度なエンジニアリングスキルや移行コストについて検討が必要です。
データレイクハウスの導入により、データの重複を排除し、管理コストを抑えながら、BIとAIの両方のニーズを満たすことができます。また、データのサイロ化を防ぎ、組織全体でのデータ活用を促進できます。
一方で、データレイクハウスの構築には、Apache Iceberg・Delta Lake・Apache Hudiといったオープンテーブルフォーマットへの理解が必要です。2026年時点では、マルチエンジン対応に優れたApache Icebergが特に注目されており、SnowflakeやDatabricksなど主要プラットフォームが対応を強化しています。
また、データをBronze(生データ)→Silver(整理済み)→Gold(集計済み)の3層で管理する「メダリオンアーキテクチャ」が標準的な設計パターンとして広く採用されています。また、既存のデータレイクやDWHからの移行には、データの再処理やパイプラインの再構築が伴うため、段階的な移行計画を立てることが重要です。
データレイクハウス導入事例
大規模なデータ基盤の刷新により、処理速度の向上やビジネス価値の創出に臨まれた各社様の事例について紹介します。
株式会社リクルート
株式会社NTTデータグループ様による株式会社リクルート様の事例では、「ゼクシィnet」や「じゃらんnet」などのWebサイトのアクセス数増加に伴い、ログデータが肥大化し、既存の分析基盤ではバッチ処理に時間がかかりすぎる問題が発生していました。
同社は、大規模分散処理基盤であるHadoopを導入し、大量のログデータを高速に処理する分析基盤を構築しました。その後、データ量の変動に柔軟に対応しコストを最適化するため、HadoopクラスタをGoogle Cloud Platform(GCP)のBigQueryへ全面移行しました。
Hadoop導入により、バッチ処理時間を大幅に高速化することに成功しました。Google Cloudへの移行により、データ量の増減に柔軟に対応できるスケーラブルなアーキテクチャを獲得し、コスト削減とアジリティ向上を実現しました。
参照元:https://oss.nttdata.com/case3_recruit.html
ネスレ日本株式会社
株式会社データ・アプリケーション様によるネスレ日本株式会社様の事例では、複数の事業部門にデータがサイロ化(分断)しており、一貫性のあるデータ活用や部門間の連携が困難でした。また、従来のオンプレミスシステムでは、増え続けるデータに対応しきれず、分析や意思決定の迅速性を欠いていました。
同社は、Microsoft Azureを基盤とした中央集権的なデータレイクを構築しました。散在していたオンプレミスのシステムからデータを集約し、冗長性を排除してデータの一貫性を確保しました。
データの一元管理により、部門横断でのコラボレーションが促進されました。
参照元:https://www.dal.co.jp/casestudies/42nestle/
データレイクとデータウェアハウスの違いまとめ

データレイクとデータウェアハウス(DWH)は、それぞれ異なる役割を持ち、データの形式、構造化の度合い、分析の目的に応じて使い分けることが重要です。
データレイクは、多様な生データを柔軟に保管し、将来的なAI解析や探索的分析に備える基盤として機能します。一方、DWHは、事前に定義されたスキーマに基づいて構造化データを管理し、定型的なBI分析や高速集計を実現します。
自社のデータ活用戦略に最適な基盤を選択し、段階的に構築・運用することで、データドリブンな意思決定を実現し、ビジネス価値の最大化を図ることができます。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。