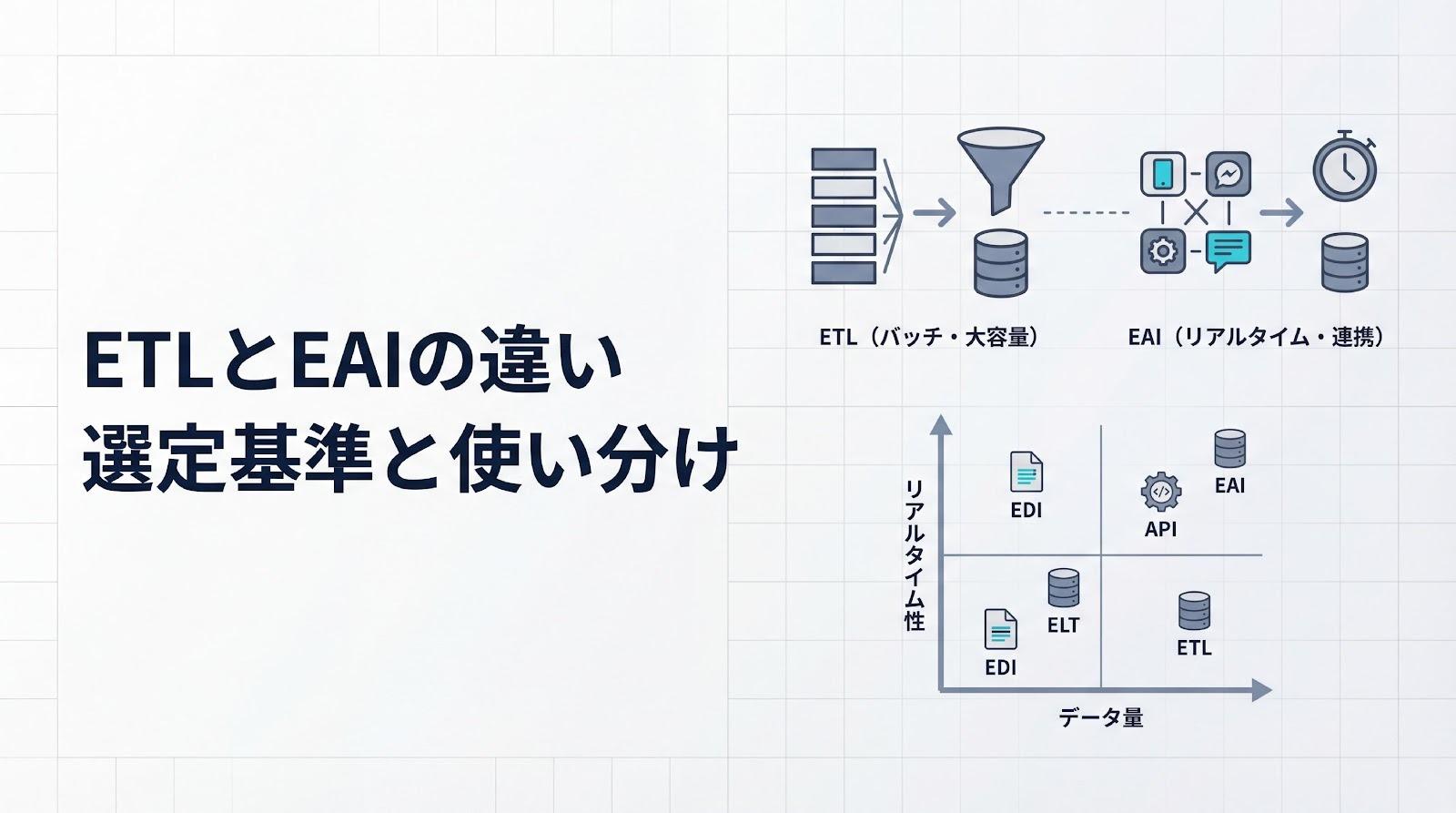
データベースとデータウェアハウスの違いとは?OLTPとOLAPの役割から解説
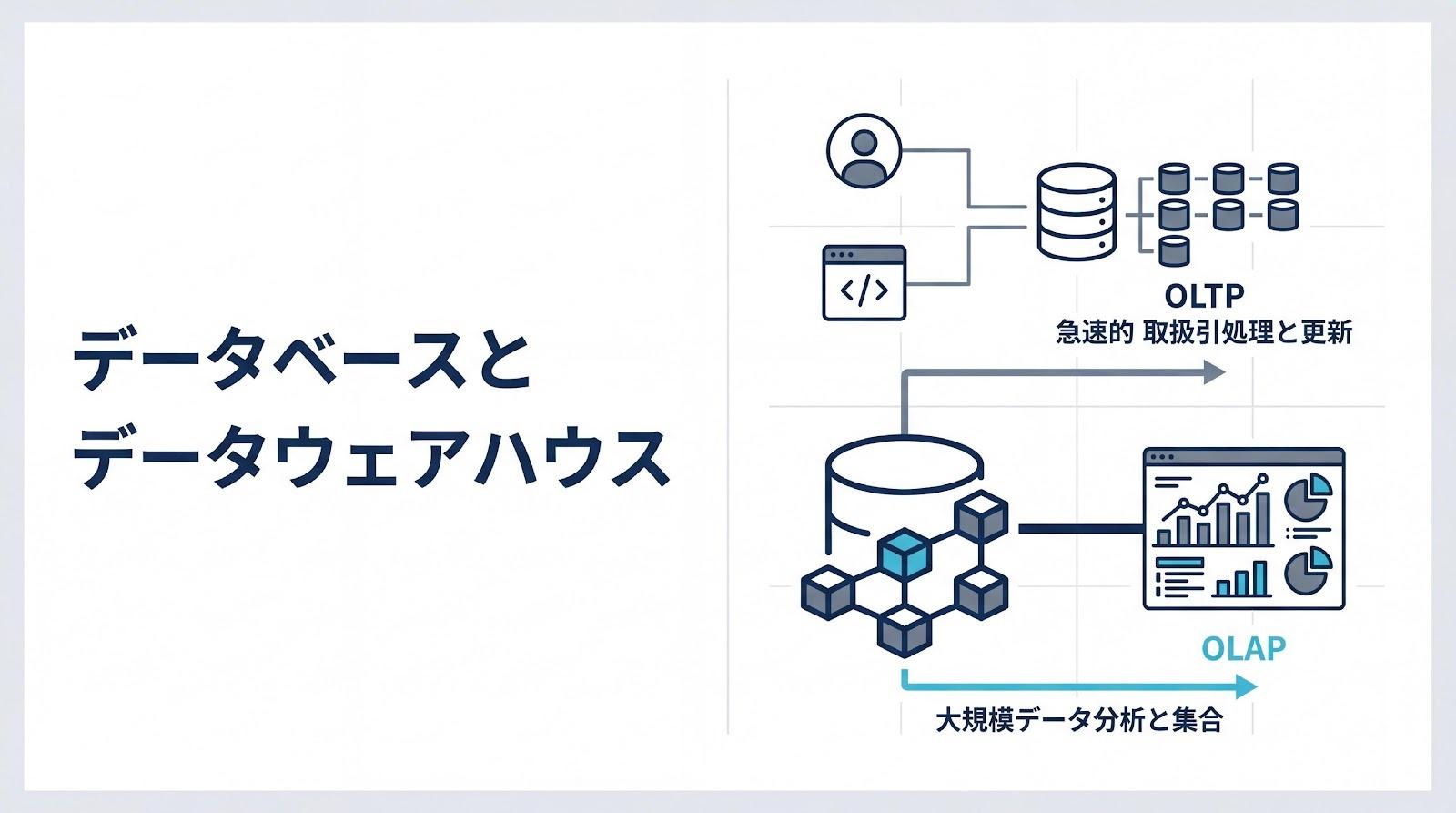
業務システムで使われるデータベース(DB)と、分析基盤として構築されるデータウェアハウス(DWH)は、どちらもデータを格納する仕組みですが、その設計思想と役割は根本的に異なります。
本記事では、データベースとデータウェアハウスの本質的な違いを整理します。、DWHが備える4つの特徴(サブジェクト指向、統合化、時系列、非更新)や、正規化と非正規化によるデータ構造の使い分け、PostgreSQLやBigQueryなどの代表的製品の比較を通じて、双方の違いを理解していきましょう。
| 項目 | OLTP(データベース) | OLAP(データウェアハウス) |
| 主な目的 | 日々の業務処理 | 意思決定のための分析 |
| 処理単位 | 短いトランザクション(INSERT/UPDATE/DELETE) | 大規模なSELECT(集計・JOIN) |
| データ量 | 数GB〜数TB | 数TB〜数PB |
| 更新頻度 | リアルタイム(秒単位) | バッチ処理(日次・週次) |
| データ構造 | 正規化(3NF以上) | 非正規化(スタースキーマ等) |
| ストレージ | 行指向 | 列指向 |
| クエリ特性 | 特定レコードへの高速アクセス | 大量レコードの集計・スキャン |
DBは「日々の業務処理」、DWHは「意思決定のための分析」に特化したシステムです。分析ニーズに対してはDWHの構築が正攻法ですが、マーケティング領域での即時活用を目指すなら、導入が容易なCDP(顧客データプラットフォーム)も有力な選択肢となります。
CDPツール比較15選!おすすめランキング・機能・選び方を徹底解説
データベースとデータウェアハウスの本質的な違い(OLTP vs OLAP)
データベースとデータウェアハウスの違いを理解する上で最も重要なのが、処理方式の違いです。
ここでは、OLTP(オンライントランザクション処理)とOLAP(オンライン分析処理)という2つの処理特性を軸に、それぞれの役割と技術的特性、そして使い分けの判断基準を整理していきます。
データベース(OLTP)の役割と処理特性
OLTP(Online Transaction Processing)は、業務システムの裏側でリアルタイムに実行される取引処理を指します。ECサイトの注文処理、銀行の入出金処理、在庫管理システムの更新など、日々の業務を支える基幹システムの多くがOLTPに分類されます。
OLTPの最大の特徴は、ACID特性(原子性・一貫性・分離性・永続性)に準拠し、データの整合性を保ちながら大量の短いトランザクションを即座に処理する点にあります。たとえば、ECサイトで顧客が商品を購入する際、在庫の引き当て、注文レコードの作成、決済情報の記録といった一連の処理が、すべて成功するか、すべて失敗するかのいずれかで完結します。この「全か無か」の仕組みによって、データの不整合を防ぎます。
技術的には、行指向ストレージ(Row-oriented storage)を採用しており、特定の1レコードに対する高速な読み書きに最適化されています。たとえば、顧客IDを指定して氏名・住所・電話番号を一括で取得する処理は、行単位でデータが格納されているため非常に高速です。
データウェアハウス(OLAP)の役割と処理特性
OLAP(Online Analytical Processing)は、蓄積された大量のデータを多角的に集計・分析するための処理方式です。過去数年分の売上データを月別・地域別・商品カテゴリ別に集計する、顧客の購買傾向を時系列で比較する、といった意思決定を支える分析業務がOLAPの主な用途となります。
OLAPでは、列指向ストレージ(Column-oriented storage)を採用することで、特定のカラムに対する大規模な集計クエリを高速に実行できます。たとえば、全顧客の「購入金額」だけを集計したい場合、列指向ストレージでは該当カラムのデータだけをスキャンすればよいため、不要なカラムを読み飛ばすことができ、ディスクI/Oを大幅に削減できます。
また、OLAPではトランザクションの即時性よりも、複数のデータソースを統合し、過去の履歴を含めた長期的なトレンド分析を行うことが重視されます。BIツール(Tableau、Power BIなど)と連携し、経営層や事業部門が直感的にデータを可視化・探索できる環境を提供するのが、DWHの重要な役割です。
【関連記事】データウェアハウスのメリットとは?デメリットや他ツールとの違いも解説
OLTP vs OLAP の比較表と使い分けの判断基準
OLTPとOLAPの違いを整理すると、以下のような対比が浮かび上がります。
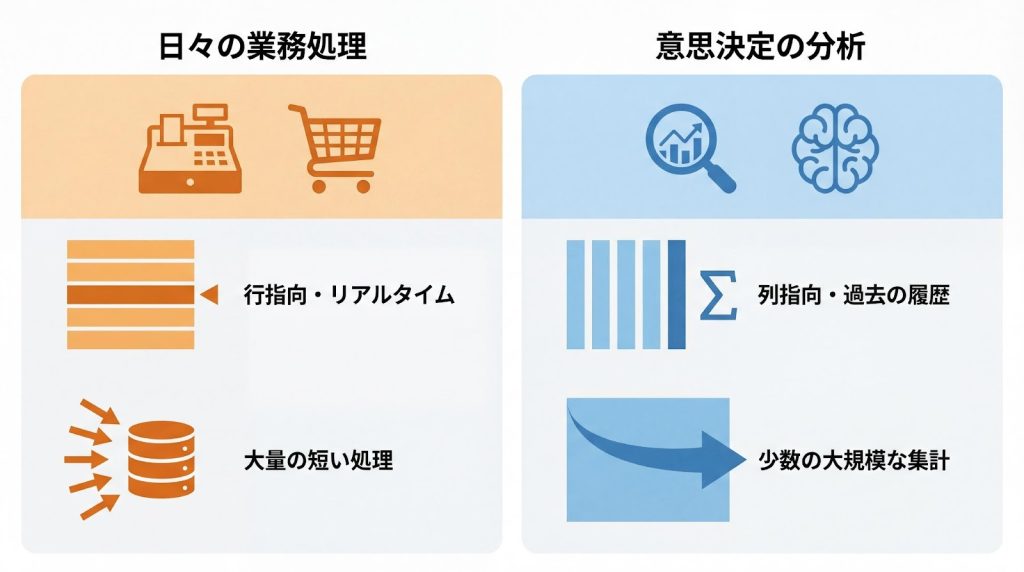
使い分けの基本原則は、業務の裏側でのリアルタイム処理にはDBを、蓄積されたデータの横断的分析にはDWHを選択することです。たとえば、ECサイトの注文処理はOLTPで実行し、月次の売上レポートや顧客セグメント分析はOLAPで実施する、といった形で役割を分担します。
判断基準としては、リアルタイム性と分析深度のどちらを優先すべきかが鍵となります。即座にデータを反映し、整合性を保つ必要がある業務処理にはDB、過去数年分のデータを横断的に集計し、傾向を把握したい分析業務にはDWHが適しています。
データウェアハウスの4つの特徴とデータ保持の仕組み
データウェアハウスの設計思想を理解する上で欠かせないのが、ビル・インモンが定義した4つの特徴です。ここでは、サブジェクト指向、統合化、時系列性、非更新性という4つの軸から、従来のDB設計との思想的な違いと、実務でのデータ保持の仕組みを深掘りしていきます。
サブジェクト指向:分析対象ごとのデータ分類
サブジェクト指向とは、業務プロセス(受注、出荷、請求など)ごとではなく、分析対象(顧客、商品、店舗など)ごとにデータを整理する設計思想です。従来のOLTPシステムでは、受注システム、在庫システム、会計システムといったように、業務フローに沿ってデータベースが分割されていました。一方、DWHでは「顧客」という軸でデータを統合し、購買履歴、問い合わせ履歴、キャンペーン反応などを一元的に参照できるように設計します。
サブジェクト指向で設計することで、ビジネスユーザーが理解しやすい形でクエリを構築することが可能になります。たとえば、「特定の商品カテゴリを購入した顧客の、過去1年間の購買頻度と平均単価を知りたい」といった分析ニーズに対し、顧客テーブルを起点に関連データを結合するだけで回答を得られます。
統合化:複数データソースの統一管理
統合化とは、散在する複数のデータソースをクレンジングし、統一フォーマットで一元管理する仕組みです。たとえば、基幹システムでは顧客IDが数値型、CRMでは文字列型、ECサイトではメールアドレスがキーとして使われている場合、そのままでは横断的な分析ができません。DWHでは、ETL(Extract, Transform, Load)プロセスを通じて、データ型の統一、重複の排除、欠損値の補完などを行い、分析可能な状態に整えます。
この統合プロセスを支える仕組みとして、MDM(Master Data Management:マスターデータ管理) があります。MDMはDWHとは独立したデータガバナンスの取り組みであり、顧客マスター・商品マスターなどの基準データを一元管理することで、DWHへのデータ統合の品質を高めます。
ただし、自社でETLを構築してデータを統合するには、相応のエンジニアリソースが必要です。マーケティング領域においては、GENIEE CDPのように、データ統合を自動化し、顧客軸(サブジェクト)での管理を容易にするパッケージ製品を活用することで、工数を大幅に削減できます。
自社でDWHを一から構築するか、CDPのような統合ツールを利用するかは、社内のリソース状況に合わせて検討すべきポイントです。
時系列と非更新:履歴データの保持と分析
DWHでは、過去のデータを上書きせず蓄積し続ける「非更新性」と、トレンド分析を可能にする「時系列性」が特徴です。OLTPシステムでは、顧客の住所が変更されると既存レコードを上書き(UPDATE)しますが、DWHではスナップショット形式でデータを保持することで、過去のある時点の状態を正確に再現できます。
たとえば、「2023年1月時点での顧客の所在地分布」を知りたい場合、DWHでは当時のスナップショットを参照すれば即座に回答できます。一方、OLTPシステムでは最新の住所しか保持していないため、過去の状態を復元することは困難です。
この時系列性により、「昨年同月比での売上成長率」「四半期ごとの顧客離脱率の推移」といった時間軸を含む分析が可能になります。特に、季節性のあるビジネスや、長期的な顧客ロイヤルティの変化を追跡する際に、非更新型のデータ保持は不可欠な要件となります。
データ構造とモデリング手法の違い(正規化 vs 非正規化)
データベースとデータウェアハウスの設計思想の違いは、データ構造にも明確に表れます。ここでは、DBの正規化とDWHの非正規化、それぞれの目的とトレードオフを整理し、スタースキーマをはじめとする具体的なモデリング手法と、実務での使い分けの判断基準を解説していきます。
データベースの正規化とそのメリット・デメリット
正規化とは、データの冗長性を排除し、更新時の整合性を保つために、テーブルを細かく分割する設計手法です。たとえば、顧客テーブルと注文テーブルを分離し、顧客IDで紐付けることで、顧客情報の変更が1箇所で済むようにします。これにより、同じ顧客情報が複数のテーブルに散在して不整合を起こすリスクを回避できます。
正規化はデータの整合性を保つのに最適ですが、複雑な集計クエリを実行する際にはオーバーヘッドが大きくなります。たとえば、「顧客ごとの年間購入金額と購入回数を集計する」クエリを実行する場合、顧客テーブル、注文テーブル、注文明細テーブル、商品テーブルなど、複数のテーブルをJOINする必要があり、処理時間が増大します。
データウェアハウスの非正規化とスキーマ設計
DWHでは、分析クエリの実行速度を優先し、意図的に冗長性を持たせた非正規化設計を採用します。代表的な設計手法がスタースキーマ(Star Schema)です。
スタースキーマは、中心にファクトテーブル(事実テーブル)を配置し、その周囲にディメンションテーブル(次元テーブル)を配置する構造を持ちます。
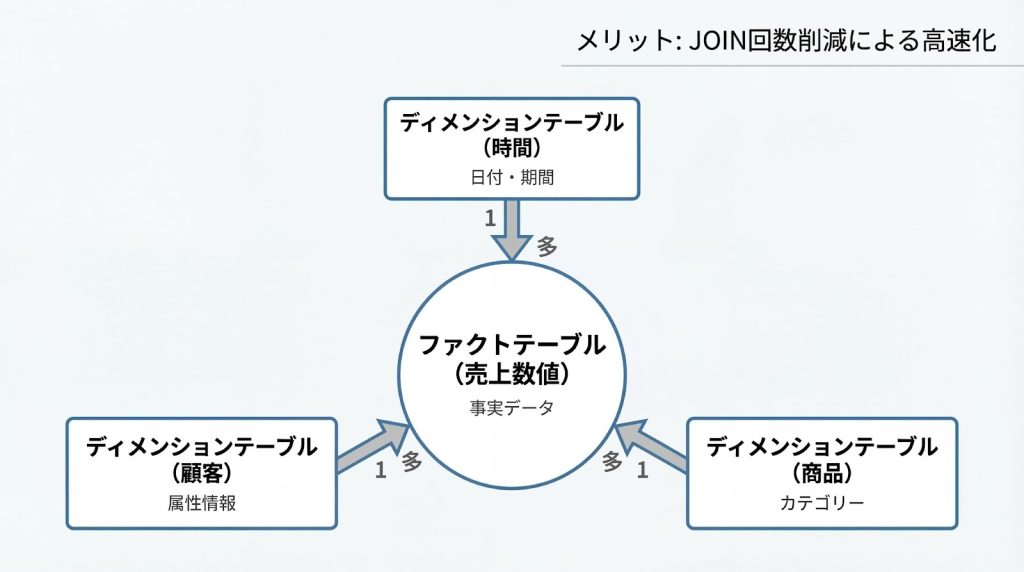
ファクトテーブルには、売上金額、販売数量、利益額といった測定可能な数値データと、各ディメンションへの外部キーが格納されます。ディメンションテーブルには、顧客、商品、店舗、時間といった分析軸の属性情報が格納されます。スタースキーマを採用することで、JOINの回数を最小限に抑え、大規模データのスキャン速度を向上させられます。
たとえば、「2023年の地域別・商品カテゴリ別の売上集計」を実行する場合、ファクトテーブルから売上金額を取得し、時間ディメンションで2023年に絞り込み、地域ディメンションと商品ディメンションでグループ化するだけで完結します。
正規化と非正規化の使い分けと実務判断基準
正規化と非正規化のどちらを選ぶかは、データ量、更新頻度、クエリ特性によって判断します。更新が頻繁なシステムはDBで正規化し、分析用のデータマートを作る段階で非正規化するのが実務的な解です。
たとえば、ECサイトの注文処理は正規化されたOLTPシステムで管理し、毎日深夜にETL処理で注文データをDWHに転送する際、スタースキーマに変換して格納します。これにより、業務システムのパフォーマンスを損なうことなく、分析用途に最適化されたデータ構造を構築できます。
現代のクラウドDWH(BigQuery、Snowflakeなど)では、ストレージとコンピュートが分離されており、非正規化によるストレージコストの増加が許容範囲内に収まるケースが多くなっています。また、列指向ストレージの採用により、冗長なカラムがあってもスキャン対象から除外されるため、パフォーマンスへの影響が限定的です。このため、「分析のしやすさ」を優先して非正規化を選択する企業が増えています。
データベースとデータウェアハウスの主要製品と選び方
データベースとデータウェアハウスの違いを理解した上で、次に直面するのが具体的な製品選定です。ここでは、代表的なRDBMS(リレーショナルデータベース管理システム)製品とクラウドDWH製品の特徴を比較し、データ量やコスト構造、運用負荷に基づいた選定基準と、判断プロセスを明確にしていきます。
【関連記事】データウェアハウス主要5製品を比較!導入に失敗しないための選び方
代表的なRDBMS製品の特徴と強み
RDBMS(リレーショナルデータベース管理システム)の代表的な製品として、PostgreSQL、MySQL、SQL Server、Oracleなどが挙げられます。
PostgreSQLは、オープンソースでありながら高い拡張性を持ち、JSON型やGIS(地理情報システム)対応など、多様なデータ型をサポートしています。小規模から中規模のOLTP用途に広く利用されており、商用製品に匹敵する機能を無償で利用できる点が強みです。
SQL Serverは、Microsoftのエコシステムとの親和性が高く、Active Directoryとの統合認証や、Power BIとの連携が容易です。エンタープライズ向けの高可用性機能(Always On可用性グループ)や、インメモリOLTP機能を備えており、ミッションクリティカルなシステムでの実績が豊富です。
Oracleは、大規模トランザクション処理における安定性と、RAC(Real Application Clusters)による高可用性が評価されています。金融機関や通信事業者など、データの整合性と可用性が最優先される業界で広く採用されています。
代表的なクラウドDWH製品の特徴と強み
クラウドDWHの代表的な製品として、Google BigQuery、Amazon Redshift、Snowflakeが挙げられます。
BigQueryは、サーバーレスアーキテクチャを採用しており、インフラの管理が不要です。ペタバイト級のデータに対しても高速なクエリ実行が可能であり、GCPの他サービス(Cloud Storage、Dataflow、Lookerなど)との統合が容易です。従量課金制のため、スモールスタートから始めやすい点も特徴です。
Amazon Redshiftは、AWSエコシステムとの親和性が高く〜列指向ストレージとMPP(超並列処理)アーキテクチャにより、大規模データの集計クエリを高速に実行できます。RA3インスタンスやRedshift Serverlessの提供により、コンピュートとストレージの分離も実現しており、柔軟なスケーリングが可能になっています。
Snowflakeは、コンピュートとストレージを分離した設計により、マルチクラウド環境での柔軟な運用を実現しています。また、Snowflake Cortexによる自然言語でのデータ分析(Snowflake Intelligence)やAI/ML機能がプラットフォームに統合されており、データサイエンティスト不在の環境でも高度な分析が可能になっています。
AWS、Azure、GCPのいずれでも稼働し、クラウドベンダーに依存しない点が強みです。また、同時実行クエリごとに独立したコンピュートリソースを割り当てられるため、複数部門での利用時にも性能劣化が起きにくい設計となっています。
技術選定の判断基準とフローチャート
製品選定の判断基準として、以下の軸を考慮します。
| 判断軸 | RDBMS向き | クラウドDWH向き |
| データ量 | 〜数TB | 数TB〜数PB |
| クエリ頻度 | 高頻度・短時間 | 低頻度・長時間 |
| リアルタイム性 | 秒単位で必要 | 日次バッチで十分 |
| 運用負荷 | 自社で管理可能 | マネージドサービス希望 |
| コスト構造 | 固定費(サーバー維持費) | 従量課金(クエリ実行量) |
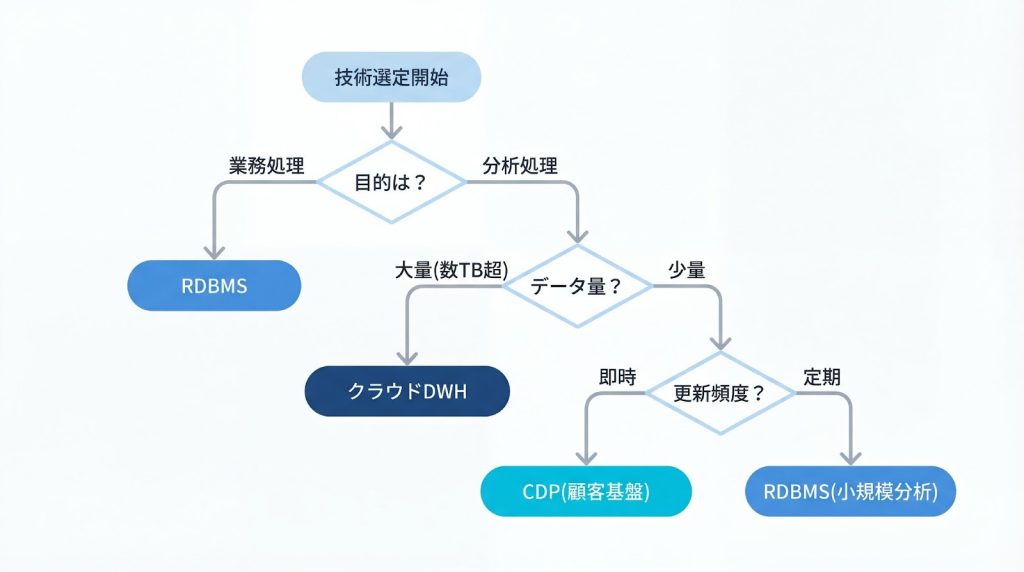
選定フローとしては、まず「リアルタイム性が必要か」を判断します。秒単位での反映が必須なら、OLTPシステム(RDBMS)を選択します。一方、日次や週次のバッチ処理で十分なら、DWHの導入を検討します。
次に、「データ量と将来的な増加見込み」を評価します。数TB以内で収まる見込みなら、PostgreSQLやSQL Serverで十分なケースが多いです。数十TB以上に成長する見込みがある場合は、クラウドDWHのスケーラビリティが有利に働きます。
最後に、「運用コストとクエリ実行ごとの従量課金コストのバランス」を検証します。BigQueryやSnowflakeは従量課金のため、クエリ実行頻度が低い場合はコストを抑えられますが、頻繁に大量のクエリを実行する場合は、Redshiftのような固定料金プランの方が経済的なケースもあります。
また、汎用的な分析基盤としてのDWHに対し、マーケティング施策への即時活用を重視するなら「CDP」という選択肢もあります。例えばGENIEE CDPは、AIによる自然言語分析サポートを備えており、データサイエンティストが不在の現場でも高度な分析が可能です。SQLを書かずに分析を進めたい場合は、DWH製品と合わせて検討する価値があります。
データベースとデータウェアハウスの違いまとめ

データベース(DB)とデータウェアハウス(DWH)は、どちらもデータを格納する仕組みですが、その役割と設計思想は根本的に異なります。OLTPとOLAPという処理方式の違いを正しく理解し、目的(運用か分析か)に応じて適切な基盤を設計することが重要です。
技術選定においては、データ量、クエリ頻度、リアルタイム性、運用負荷、コスト構造といった軸で判断します。小規模で更新頻度が高い業務システムにはPostgreSQLやSQL ServerなどのRDBMSが適しており、大規模データの横断的分析にはBigQuery、Redshift、SnowflakeなどのクラウドDWHが適しています。
まずは特定の部門やデータソースから試験導入し、成功事例を作った上で全社展開する段階的な移行戦略を採用することで、リスクを抑えながらDWH導入の効果を最大化できます。もし自社でのDWH構築が難しい場合は、GENIEE CDPのような導入ハードルの低い製品から検討を開始してみてはいかがでしょうか。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。