エンタープライズ・データウェアハウスとは?導入手順と製品選定の考え方について解説
企業のデータ活用が競争優位の源泉となる中、部門ごとに散在するデータを統合し、組織全体で「信頼できる唯一の情報源」を確立することが急務となっています。しかし、レガシーシステムの存在やデータ形式の不統一により、全社横断的な分析基盤の構築は多くの企業にとって大きな課題です。
エンタープライズ・データウェアハウス(EDW)は、こうしたデータサイロを解消し、組織全体で一貫性のあるデータ活用を実現するための中核的な基盤です。本記事では、EDWの定義から最新のクラウド製品比較、段階的な移行プロセス、そしてガバナンス体制の構築まで、導入に必要な知識を網羅的に解説します。
具体的には、主要クラウドEDW製品の機能・料金比較、レガシーシステムからの移行ロードマップ、データガバナンスとセキュリティ統制の実装方法、そして投資対効果を最大化するためのコスト最適化戦略を、実際の企業事例とともに紹介します。
EDW導入の全体設計と技術構成要素

この章では、エンタープライズ・データウェアハウス(EDW)の基本的な定義と役割、そしてEDWが解決する主要な課題について解説します。データレイクやデータマートとの違いを明確にし、全社規模のデータ統合基盤としてのEDWの位置づけを理解していきます。
エンタープライズ・データウェアハウス(EDW)とは
エンタープライズ・データウェアハウス(EDW)は、組織全体のデータを統合・構造化して保存し、分析や意思決定に活用するための全社規模のデータ基盤です。部門や業務システムごとに分散しているデータを一元的に集約し、組織横断的な分析を可能にする点が最大の特徴です。
EDWは、データレイクやデータマートとは明確に異なる役割を持ちます。データレイクが生データを大量に保存する「データの貯蔵庫」であるのに対し、EDWはデータを構造化・整理して保存し、すぐに分析可能な状態で提供します。
一方、データマートは特定部門や用途に特化した小規模なデータ集合であり、EDWから必要なデータを切り出して構築されることが一般的です。
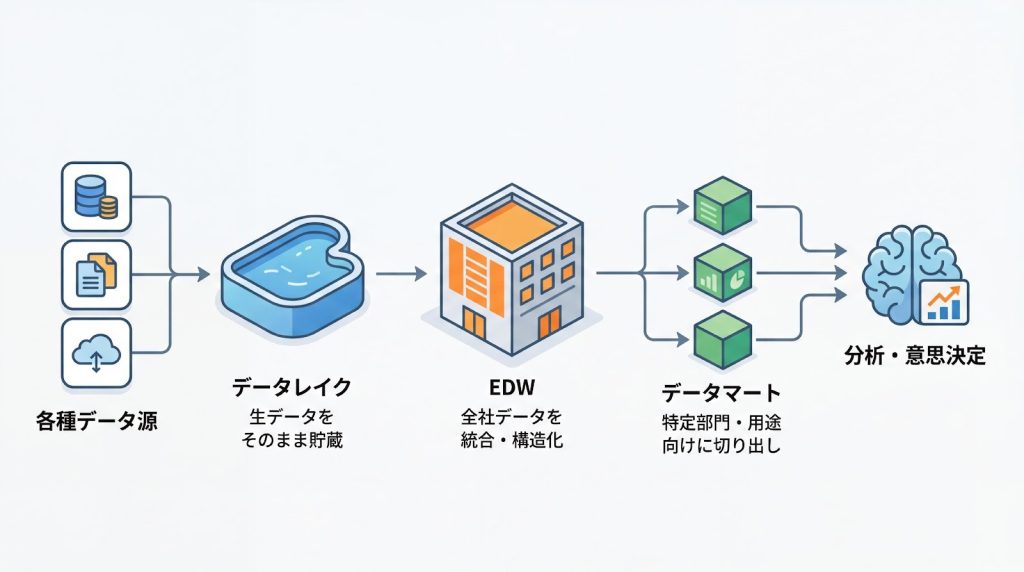
これらは対立する概念ではなく、相互に補完し合う関係にあります。データレイクで多様な生データを受け入れ、EDWで全社的な分析基盤を構築し、データマートで部門ごとの迅速な分析を実現するという、階層的なデータ活用の構造が理想的です。
EDWが解決する3つの課題
EDWは、現代の企業が直面するデータ活用上の主要な課題を解決します。ここでは、データサイロ化、指標の不一致、処理能力の限界という3つの課題について詳しく見ていきます。
1. データサイロ化の解消
多くの企業では、販売管理システム、在庫管理システム、顧客管理システムなど、部門ごとに異なるシステムが独立して運用されています。この結果、データが部門間で分断され、全社的な視点での分析が困難になる「データサイロ化」が発生します。
EDWは、これらの分散したデータソースから情報を収集し、統一されたフォーマットで一元管理します。これにより、部門を横断した顧客行動の分析や、サプライチェーン全体の可視化が可能になります。
顧客データの統合が特に重要な場合は、CDP(カスタマーデータプラットフォーム)のような活用特化型の基盤を併用することで、早期に価値を創出できる場合もあります。全社基盤としてのEDWに対し、マーケティング活用に特化した情報源としてGENIEE CDPのような選択肢を検討するのも一つの手です。
【関連記事】
CDPツール比較15選!おすすめランキング・機能・選び方を徹底解説
2. 指標の不一致の解消
システムごとにデータの定義や集計方法が異なると、同じ「売上高」でも部門によって数値が異なるという事態が発生します。これは経営判断の混乱を招き、組織の意思決定を遅らせる要因となります。
EDWでは、データの取り込み時に標準化されたルールに基づいて変換・整理を行い、「信頼できる唯一の情報源(Single Source of Truth: SSOT)」を確立します。全社で共通の指標定義を共有することで、経営層から現場まで一貫した認識のもとで意思決定ができるようになります。
3. 処理能力の限界への対応
データ量の増大に伴い、既存のデータベースでは複雑なクエリの実行に数時間かかるなど、業務に支障をきたすケースが増えています。特に、リアルタイムに近い分析や、大量の履歴データを対象とした集計が求められる場面では、従来型のシステムでは対応が困難です。
現代のクラウド型EDWは、ストレージとコンピューティングを分離したアーキテクチャを採用し、必要に応じて処理能力を柔軟にスケールできる設計になっています。これにより、データ量の増加に対しても性能を維持しながら、コストを最適化することが可能です。
クラウド型EDWの選定基準と主要5製品の比較

この章では、主要なクラウド型EDW製品の特徴と選定基準について解説します。Snowflake、Google BigQuery、Amazon Redshift、Microsoft Azure Synapse Analytics、Oracle Autonomous Data Warehouseの5製品を取り上げ、アーキテクチャ、料金体系、処理要件に応じた選定ポイントを整理します。
主要クラウドEDW 5製品の機能・料金比較
クラウド型EDWの選定では、自社のクラウド戦略や分析要件に応じて、各製品の特性を理解することが重要です。ここでは、主要5製品の基本的な特徴と料金体系を比較します。
| 製品名 | 提供元 | アーキテクチャの特徴 | 料金体系 | 主な強み |
| Snowflake | Snowflake Inc. | ストレージとコンピュートの完全分離、マルチクラウド対応 | 従量課金(ストレージ+コンピュート) | 柔軟なスケーリング、データ共有機能 |
| Google BigQuery | Google Cloud | サーバーレス、ペタバイト級の高速クエリ | 従量課金(クエリ処理量またはスロット予約) | アドホック分析、機械学習統合 |
| Amazon Redshift | Amazon Web Services | 列指向ストレージ、MPP(超並列処理) | インスタンス課金またはサーバーレス従量課金 | AWSサービスとの統合、大規模バッチ処理 |
| Azure Synapse Analytics | Microsoft Azure | データ統合とビッグデータ分析の統合環境 | 従量課金(DWU単位またはサーバーレス)※Microsoft Fabricへの統合移行が進行中 | Power BIとの連携、エンタープライズ統合 |
| Oracle Autonomous Data Warehouse | Oracle Cloud | 自律運用(自動チューニング、パッチ適用) | ECPU課金またはストレージ課金(旧来のOCPUはレガシーメトリックとして廃止済み) | Oracleエコシステム、運用自動化 |
各製品の料金体系は、利用パターンによって大きく異なります。アドホック分析が中心の場合は従量課金が有利ですが、定常的な大量処理が必要な場合は予約型やインスタンス型の方がコストを抑えられる場合があります。詳細な料金は各製品の公式サイトで最新情報を確認することを推奨します。
処理要件別の選定ポイント
EDW製品の選定では、自社の分析頻度、データ量、運用体制を考慮することが重要です。ここでは、処理要件に応じた選定の考え方を整理します。
1. アドホック分析中心の場合
データアナリストやビジネスユーザーが、必要に応じて柔軟にクエリを実行する環境では、サーバーレス型のアーキテクチャが適しています。
Google BigQueryは、事前のインフラ設定なしにペタバイト級のデータに対して高速なクエリを実行でき、使った分だけ課金されるため、アドホック分析に最適です。
2. 大規模バッチ処理中心の場合
定期的な大量データの集計やETL処理が中心の場合は、予測可能な処理パターンに対して最適化された製品が有利です。
Amazon Redshiftは、AWSの各種サービス(S3、Glue、Lambda等)と強力に統合されており、大規模なバッチ処理パイプラインを効率的に構築できます。
3. マルチクラウド戦略を採用する場合
特定のクラウドベンダーに依存せず、複数のクラウド環境を活用する戦略を採る場合は、Snowflakeのようなマルチクラウド対応製品が選択肢となります。AWS、Azure、Google Cloud上で同じアーキテクチャを利用でき、クラウド間でのデータ共有も容易です。
4. 運用負荷を最小化したい場合
データベースの運用管理に専任の人材を割けない組織では、自律運用機能を持つ製品が有効です。Oracle Autonomous Data Warehouseは、パフォーマンスチューニング、パッチ適用、バックアップなどを自動化し、運用負荷を大幅に削減します。
また、データ分析の専門家そのものが不足している組織では、AI活用による分析サポート機能を持つ製品の検討も有効です。たとえばGENIEE CDPのように、AIが自然言語での分析をサポートしてくれるツールを選べば、専門家不在でも高度なデータ活用が実現できます。
レガシーシステムからEDWへの段階的移行を行うにあたって
この章では、既存のレガシーシステムからEDWへの移行を成功させるための段階的なアプローチを解説します。パイロット導入から完全移行までの4フェーズにおける実施内容を示します。
4段階の移行ロードマップ
EDWへの移行は、一度にすべてのシステムを切り替えるのではなく、段階的に進めることでリスクを最小化します。ビジネス影響度と技術的難易度を考慮しながら、パイロット導入から始めて徐々に範囲を拡大していくアプローチが推奨されます。
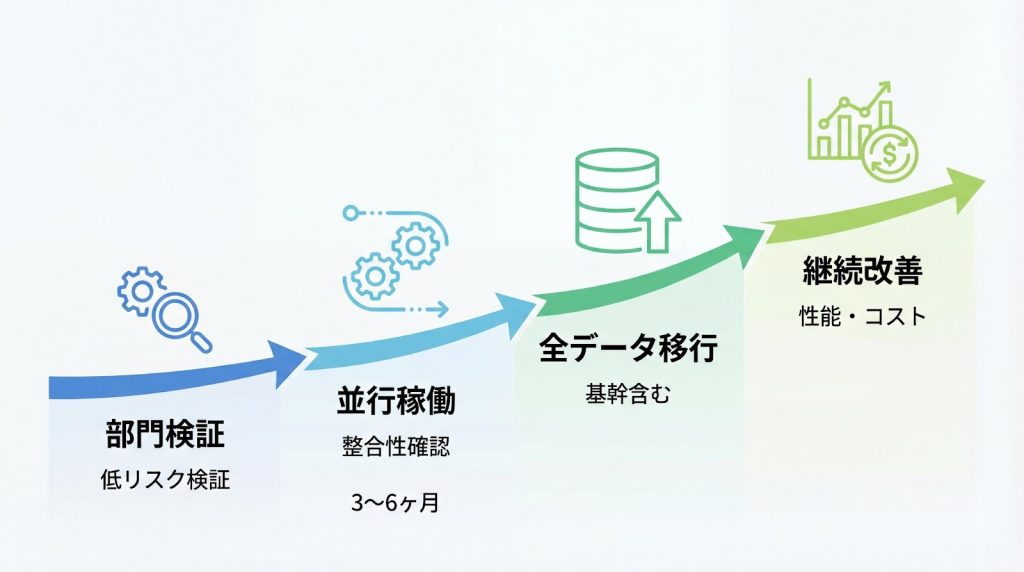
フェーズ1: パイロット導入(1〜3ヶ月)
最初のフェーズでは、ビジネス影響が限定的で技術的にもシンプルな部門やデータソースを選定し、小規模なパイロット環境を構築します。たとえば、特定の販売拠点のデータや、分析用途に限定したデータセットから開始します。
この段階では、EDWの基本的なアーキテクチャを検証し、データ取り込みのパイプライン、変換ルール、セキュリティ設定などの基本設計を確立します。また、実際のユーザーによる分析作業を通じて、パフォーマンスや使い勝手を評価します。
フェーズ2: 部分的な展開(3〜6ヶ月)
パイロットで得られた知見をもとに、対象範囲を拡大します。複数の部門やデータソースを追加し、より複雑なデータ統合やクエリパターンに対応します。この段階では、既存システムとEDWを並行稼働させ、データの整合性を継続的に検証します。
並行稼働期間を3〜6ヶ月確保することで、既存システムとEDWの出力結果を比較し、差異があれば原因を特定して修正します。これにより、業務を止めることなく段階的に移行を進められます。
フェーズ3: 全社展開(6〜12ヶ月)
部分展開で安定性が確認できたら、全社規模での展開に移ります。すべての主要なデータソースをEDWに統合し、組織全体で「単一の真実」を共有できる状態を目指します。
この段階では、データガバナンスの体制を正式に確立し、データ品質の監視、アクセス権限の管理、メタデータの整備などを組織的に運用します。また、ユーザー向けのトレーニングやドキュメント整備を行い、全社的なデータ活用文化を醸成します。
フェーズ4: レガシーシステムの廃止(12ヶ月以降)
EDWが安定稼働し、すべての業務がEDW上のデータで運用できることが確認できたら、レガシーシステムの廃止を計画します。ただし、法的な保存義務があるデータや、特殊な業務要件で引き続き必要なシステムについては、慎重に判断します。
廃止のタイミングでは、データのアーカイブ方針を明確にし、必要に応じて長期保存用のストレージに移行します。また、廃止後の問い合わせ対応やトラブルシューティングのための体制も整備しておきます。
アクセス制御とセキュリティポリシーの整備
EDWには組織全体のデータが集約されるため、適切なアクセス制御とセキュリティポリシーの実装が不可欠です。
ここでは、ロールベースアクセス制御(RBAC)やデータマスキング技術を用いた保護手法を解説します。
1. ロールベースアクセス制御(RBAC)の実装
RBACは、ユーザーの職務や役割に応じてアクセス権限を付与する仕組みです。たとえば、営業部門のマネージャーには営業データへの読み取り権限を、データエンジニアにはETLパイプラインの編集権限を、経営層には全社データへの参照権限を付与するといった形で、必要最小限の権限を割り当てます。
職務に応じたアクセス権限の最小化により、内部不正や誤操作によるデータ漏洩リスクを低減できます。また、権限の付与・変更・削除のプロセスを明確にし、定期的な権限レビューを実施することで、不要な権限が放置されることを防ぎます。
2. データマスキングと匿名化
個人情報や機密情報を含むデータを分析に利用する場合、データマスキングや匿名化の技術を適用します。たとえば、顧客名や住所を伏せ字にする、クレジットカード番号の一部のみを表示する、年齢を年代に丸めるといった処理を行います。
これにより、分析に必要な情報の傾向は保持しつつ、個人を特定できないようにします。特に、開発環境やテスト環境では、本番データをそのまま使用せず、マスキングされたデータを利用することが推奨されます。
3. 監査ログの記録と監視
すべてのデータアクセスやクエリ実行の履歴を監査ログとして記録し、定期的にレビューします。異常なアクセスパターンや大量のデータダウンロードが検知された場合は、速やかに調査し、必要に応じて権限を停止します。
監査ログは、セキュリティインシデントの発生時に原因究明や影響範囲の特定に不可欠です。また、法令遵守の観点からも、個人情報保護法が求める安全管理措置として、アクセス記録の保持と定期的な確認が求められます。
4. 暗号化の実装
データの保存時(at rest)および転送時(in transit)の両方で暗号化を実施します。クラウド型EDWの多くは、標準で暗号化機能を提供していますが、暗号鍵の管理方法や、顧客管理鍵(CMK)の利用可否など、セキュリティ要件に応じた設定が必要です。
特に、個人情報や機密性の高いデータを扱う場合は、暗号化の強度や鍵のローテーション方針を明確にし、組織のセキュリティポリシーに準拠した運用を行います。
EDW導入の投資対効果測定とコスト最適化戦略
この章では、EDW導入の投資対効果(ROI)を測定する指標と、導入後のコストを最適化する手法を解説します。経営層への予算承認を得るための定量的な成果指標と、実際の企業事例を通じた具体的な成果を紹介します。
ROI測定の3つの指標
EDW導入の効果を可視化するためには、コスト削減、意思決定の迅速化、ビジネス機会の創出という3つの軸で測定します。これにより、経営層に対して投資の妥当性を説明しやすくなります。
1. コスト削減効果
EDW導入により、データ集計やレポート作成の工数が削減されるケースが多く見られます。従来は部門ごとに手作業でデータを収集・集計していた作業が、EDW上のダッシュボードやクエリで自動化されることで、月次の作業時間が大幅に短縮されます。
また、レガシーシステムの保守コストや、複数のデータベースライセンス費用を統合することで、ランニングコストの削減も期待できます。クラウド型EDWの従量課金モデルを活用すれば、使用量に応じた柔軟なコスト管理が可能になります。
2. 意思決定の迅速化
データが統合され、リアルタイムに近い形で分析できるようになると、経営判断のスピードが向上します。たとえば、在庫状況と販売動向を組み合わせた分析により、発注タイミングを最適化したり、キャンペーンの効果を即座に評価して次の施策に反映したりできます。
意思決定の迅速化は、直接的な金額換算が難しい場合もありますが、市場機会の逃失を防ぐ効果や、競合に対する優位性の確保という形で価値を生み出します。
3. ビジネス機会の創出
データ分析の高度化により、これまで見えなかった顧客インサイトや市場トレンドを発見し、新たなビジネス機会を創出できます。たとえば、顧客の購買パターンを分析してクロスセル提案を最適化したり、製品の利用データから新サービスのアイデアを得たりすることが可能です。
EDWと既存ツールの連携を活用することで、開発コストを抑えつつ施策のリードタイムを短縮し、迅速に市場投入できる体制を構築できます。特にGENIEE CDPは主要なマーケティングツールと標準連携しており、開発コストを抑えつつ、FinOpsの観点からも効率的なデータ活用基盤を構築できます。
コスト最適化の成功事例
実際の企業事例を通じて、EDW導入がもたらした具体的な成果を紹介します。製造業や通信業など、多様な業種での成功パターンを共有します。
株式会社LIXIL: 分析時間の大幅短縮
株式会社LIXILは、複数の企業統合の背景から各社のシステム間でデータが連携されておらず、全社横断でのデータ活用が困難でした(出典URL: https://it.impress.co.jp/articles/-/21484)。
基幹システムをGoogle Cloud上のSAP S/4HANAへ移行すると同時に、全社横断のデータ分析基盤「Lixil Data Platform」を構築し、データウェアハウスとしてGoogle BigQueryを採用しました。
この結果、データ活用のセルフサービス化を実現し、BigQueryの高速なクエリ処理能力により、ある分析では処理時間を1日から10秒程度へ大幅に短縮しました。(出典URL: https://it.impress.co.jp/articles/-/21484)経営情報管理基盤としてSAP Analytics Cloudも導入し、経営判断のさらなる迅速化を目指しています。
株式会社NTTドコモ: ガバナンスと利便性の両立
株式会社NTTドコモは、全社規模でデータを活用する上で、高度なデータガバナンスを維持しつつ、各部門のユーザーが必要なデータに自由にアクセスできる環境の両立が課題でした(出典URL: https://www.snowflake.com/ja/customers/all-customers/case-study/ntt-docomo/)。データウェアハウスとしてSnowflakeを導入し、全社規模のデータ基盤を構築しました。
利用ルールを全面的に見直し、ユーザーにとって分かりやすい形に再整備するとともに、リソース利用状況に応じたコスト分担の仕組みを構築しました。この結果、高度なデータガバナンスと自由なデータアクセスを両立させ、データ活用の効率化と管理工数の削減を実現しています。
株式会社SUBARU: 部門横断のデータ統合
株式会社SUBARUは、部門や業務ごとにシステムがサイロ化しており、開発から生産、保守までのデータを横断的に連携させることが困難でした(出典URL:https://monoist.itmedia.co.jp/mn/articles/2409/03/news077.html)。全社的なデータ統合プラットフォームを構築するため「グローバルPLMプロジェクト(2020年開始)」を推進し、Informatica社のAI搭載クラウド型データ管理基盤「IDMC」とAmazon Redshiftを組み合わせたデータ統合基盤を導入しました。
車両識別番号(VIN)、品番、顧客IDを骨格として、開発から保守までの車両生涯データを統合管理する基盤を構築し、開発から製造、販売、保守に至るまでのデータを部門横断的に統合することに成功しました。導入後、約400種類のデータアセットのカタログ化を完了させています。
エンタープライズ・データウェアハウスとは?まとめ
エンタープライズ・データウェアハウスの導入は、組織全体のデータ活用を変革する大きな取り組みです。本記事で解説した全体設計、製品選定、段階的移行、ガバナンス体制、ROI測定の各ステップを理解することで、失敗のリスクを最小化し、確実に成果を生み出すEDW基盤を構築できます。
技術的な準備だけでなく、組織体制やデータ品質の整備にも十分な時間を確保してください。特に、データスチュワードやデータオーナーといった「人」の役割を明確にし、全社的なデータ活用文化を醸成することが、EDW導入の成功を左右します。
もし、全社的なEDW構築の前に、まずは顧客データの統合と活用からスモールスタートしたいとお考えであれば、GENIEE CDPの導入も検討してみてください。AIによる分析サポートと豊富な標準連携機能により、最短ルートでデータドリブンなマーケティングを実現できます。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。