







Excelで名寄せする方法は?関数の使い方と重複削除の手順を解説

「展示会で集めた名刺リストと既存の顧客データを統合したいが、どこから手をつければいいかわからない」「会社名の表記がバラバラで、同じ企業なのに別々のレコードになってしまっている」Excelで顧客データを扱う現場では、こうした状況が日常的に起きています。
名寄せという作業自体は知っていても、具体的な関数の使い方や作業の順序がわからず、結局は手作業で目視確認を続けているケースも少なくありません。
Excelでの名寄せは、TRIM・ASC・SUBSTITUTE・COUNTIF・VLOOKUPといった関数を組み合わせることで、大部分を自動化できます。重要なのは「クレンジングを先に行い、その後に重複検出をする」という順序を守ることで、この順序を間違えると同一レコードを別レコードと誤判定するリスクが高まります。
この記事では、データ統合からクレンジング・重複削除・マッチング確認まで、名寄せの4工程を順に解説します。
複数システムのデータが散在|CDP活用でデータクレンジングと名寄せを自動化
Excelで行う名寄せとは何か:作業の全体像と4つの工程
名寄せとは、複数のリストに散在する同一顧客・同一企業のデータを、表記統一と重複排除によって1つに統合する作業です。
単純に聞こえますが、「株式会社〇〇」「(株)〇〇」「㈱〇〇」のように表記が揺れていると、コンピューターは別々のレコードとして扱ってしまいます。この状態のまま重複を探しても、ほとんど検出できません。作業の全体像を把握してから進めることが、精度を高める前提条件になります。
名寄せが必要になる3つの典型場面
名寄せが必要になる場面は、業種や規模を問わず共通しています。自分の状況と照らし合わせながら確認してみてください。
最も頻繁に発生するのは、展示会やセミナーで収集した名刺リストと既存の顧客リストを統合する場面です。名刺情報は担当者が個別に入力することが多く、会社名の表記や電話番号のフォーマットが統一されていないまま蓄積されがちです。既存リストと突き合わせると、同一企業が複数のレコードとして登録されているケースが頻繁に見つかります。
次に多いのが、複数部門から集まったリストの整理です。営業部門・マーケティング部門・カスタマーサポートがそれぞれ独自に管理していたリストを一本化しようとすると、同一顧客が部門ごとに異なる表記で登録されていることがほぼ確実に起きます。
SFAやCRMへのデータ移行前の前処理も、名寄せが必要になる典型的な場面です。移行後にシステム内で重複や表記ゆれが残っていると、後から修正するコストが大きくなります。Excelの段階で名寄せを完了させておくことで、移行後のデータ品質を確保できます。
顧客データ統合とは?仕組みから名寄せ・要件定義まで基礎を解説
名寄せ4工程の流れと各工程の目的
名寄せは①データ準備・統合、②クレンジング、③重複検出・削除、④マッチング確認の4工程で構成されます。
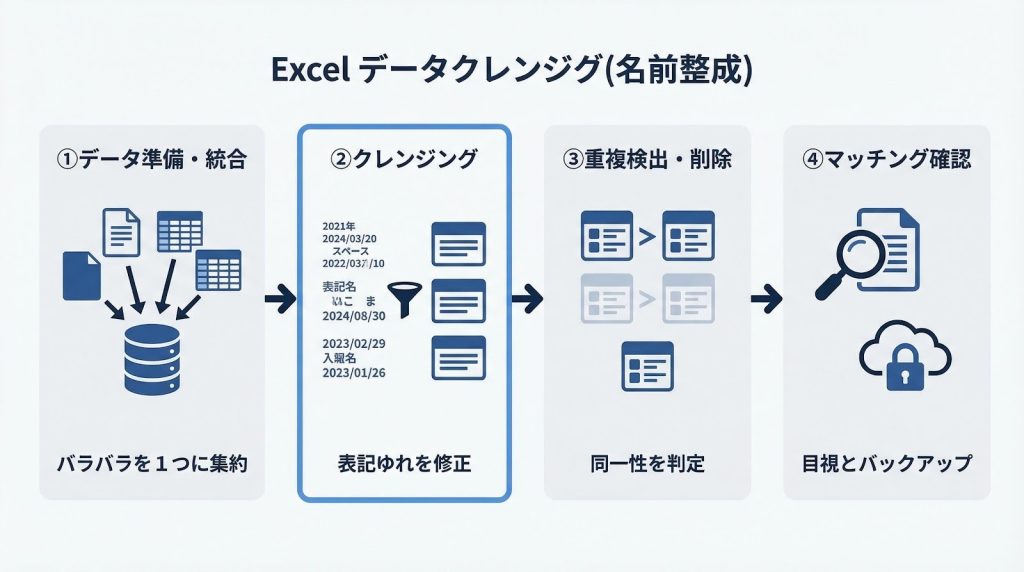
この順序には理由があります。②クレンジングを③重複検出より先に行うのは、表記ゆれが残ったままでは同一レコードを別レコードと誤判定するリスクがあるためです。順序を入れ替えると、検出精度が大きく落ちます。
各工程と対応するExcel機能の関係は次のとおりです。
| 工程 | 目的 | 主な関数・機能 |
| ①データ準備・統合 | 列構成を揃えて1シートに結合する | VLOOKUP / XLOOKUP / CONCATENATE / &演算子 |
| ②クレンジング | 表記ゆれ・全角半角・スペースを統一する | TRIM / ASC / SUBSTITUTE / CLEAN |
| ③重複検出・削除 | 重複フラグを立てて安全に除去する | COUNTIF / 重複の削除機能(データタブ) |
| ④マッチング確認 | 照合キーで同一性を最終確認する | 照合キー列による目視確認 |
②で使うTRIM・ASC・CLEANは、それぞれ「スペース除去」「全角→半角変換」「制御文字除去」という異なる役割を持っています。これらを組み合わせることで、1つの数式でまとめてクレンジングできます。詳細は後続の章で順に解説します。
顧客データ統合とは?仕組みから名寄せ・要件定義まで基礎を解説
複数のExcelリストを1つに統合する手順
名寄せ作業の出発点は、バラバラに存在するリストを1つのシートに集約することです。ここで列構成を揃えずに統合してしまうと、後続のクレンジングや重複検出で列ずれが発生し、関数が正しく機能しなくなります。
3つのステップで順に進めていきましょう。
ステップ1:列構成を揃えて統合の土台を作る
複数のリストを統合する前に、まず統合先シートのテンプレートを作成します。各リストで列名や列順がバラバラな状態のまま貼り付けると、「A列が会社名のリスト」と「A列が担当者名のリスト」が混在してしまいます。
統合先シートには、次のような列構成を先に定義しておくことをお勧めします。
- 会社名
- 担当者名
- 部署
- 電話番号
- メールアドレス
- 住所
- 出典リスト名
「出典リスト名」列は、後から「どのリストのデータか」を追跡するために使います。重複削除の際に、どちらのレコードを残すかを判断する材料になるため、最初から追加しておくと作業がスムーズになります。
各リストの列をこのテンプレートに合わせてから貼り付けることで、後続の関数操作が安定します。列名が異なる場合(例:「企業名」と「会社名」)は、貼り付け前に統一しておいてください。
ステップ2:リストを1シートに結合する
テンプレートが準備できたら、各リストのデータ行をコピーして統合先シートに貼り付けていきます。このとき、2枚目以降のリストを貼り付ける際はヘッダー行を除いてデータ行のみを選択してください。ヘッダー行が重複して混入すると、フィルターや関数操作が正常に動作しなくなります。
具体的な手順は次のとおりです。
- 1枚目のリストのデータ行(ヘッダーを含む)を統合先シートに貼り付ける
- 「出典リスト名」列に、そのリストの名称(例:「展示会2024年10月」)を入力する
- 2枚目以降のリストは、ヘッダー行を除いたデータ行のみを選択してコピーする
- 統合先シートの最終行の次の行に貼り付ける
- 「出典リスト名」列に対応するリスト名を入力する
貼り付け後は、統合先シートの行数が各リストの合計行数と一致しているかを確認してください。ヘッダー行が混入していると行数が合わなくなるため、すぐに気づけます。
ステップ3:VLOOKUP/XLOOKUPで別リストの情報を引き当てる
リストを1シートに結合した後、別リストから追加情報を引き当てたい場合にはVLOOKUP関数またはXLOOKUP関数を使います。
また、重複検出の精度を高めるために「照合キー列」を作成することも、このステップで行います。
VLOOKUPの基本構文と絶対参照
VLOOKUPの構文は次のとおりです。
=VLOOKUP(検索値, $参照範囲, 列番号, FALSE)
参照範囲には必ず絶対参照($)を付けてください。絶対参照を付けないと、数式を下方向にコピーした際に参照範囲がずれてエラーや誤引き当てが発生します。たとえば、A2セルの会社名をもとに別シートの電話番号を引き当てる場合は次のように書きます。
=VLOOKUP(A2, 別シート!$A$2:$D$100, 3, FALSE)
XLOOKUPとの使い分け
XLOOKUPも選択肢に入ります。VLOOKUPと異なり、検索列が左端でなくてもよく、見つからない場合の返り値も直接指定できます。
=XLOOKUP(検索値, 検索範囲, 戻り配列, “該当なし”)
XLOOKUPはExcel 2021以降およびMicrosoft 365で利用できます(Excel 2019以前では使用不可)。Excel 2016・2019のサポートは2025年10月に終了しており、現在はXLOOKUPが使える環境が主流になっています。
ファイルを共有する相手のExcelバージョンが不明な場合はVLOOKUPを使い、環境が確認できている場合はXLOOKUPを積極的に活用するとよいでしょう。
照合キー列の作成
重複検出の精度を高めるために、会社名と電話番号を結合した「照合キー列」を作成します。単一項目(会社名のみ)での照合より、誤マッチングを大幅に減らせます。
=A2&B2(会社名と電話番号を結合する例)
または、CONCAT関数(Excel 2016以降)を使う場合: =CONCAT(A2, B2)
※CONCATENATEはExcel 2019以降で非推奨となっているため、&演算子またはCONCAT関数の使用を推奨します。
この照合キー列は、次の工程(クレンジング後の重複検出)で検索値として使います。クレンジング済みの値を結合するよう、クレンジング後の列を参照するように設定してください。
表記ゆれを一括修正するクレンジング関数の使い方

データを1シートに統合できたら、次はクレンジングです。重複検出の前にこの工程を完了させることが、名寄せ精度の鍵になります。表記ゆれの主なパターンと、それぞれに対応する関数を整理してから作業を進めましょう。
クレンジング関数を適用した結果は、元の列を上書きせず別列に出力してください。誤修正が発覚した際に元データへ戻せるよう、元データは必ず保持しておくことが原則です。
複数システムのデータが散在|CDP活用でデータクレンジングと名寄せを自動化
主な表記ゆれのパターンと対応関数は次のとおりです。
| 表記ゆれの種類 | 例 | 対応関数 |
| 会社名の略称・記号 | (株)→ 株式会社、㈱ → 株式会社 | SUBSTITUTE |
| 余分なスペース | 「株式会社 〇〇」(全角スペース混在) | TRIM + SUBSTITUTE |
| 全角・半角の混在 | 「ABC」と「ABC」 | ASC / JIS |
| 制御文字・改行コード | 他システムからのエクスポートデータ | CLEAN |
SUBSTITUTE関数:会社名の表記を統一する
SUBSTITUTE関数は、文字列の中の特定の文字を別の文字に置換します。構文は次のとおりです。
=SUBSTITUTE(文字列, 検索文字列, 置換文字列)
「(株)」を「株式会社」に置換する場合は次のように書きます。
=SUBSTITUTE(A2, “(株)”, “株式会社”)
複数の表記パターンをまとめて処理したい場合は、SUBSTITUTEをネストします。
=SUBSTITUTE(SUBSTITUTE(A2, “(株)”, “株式会社”), “㈱”, “株式会社”)
なお、「株式会社〇〇」(前株)と「〇〇株式会社」(後株)の前後位置の統一は、関数だけでは自動判定が難しい部分です。コーポレートサイトの正式表記を基準にして、どちらかに統一する方針を決めてから作業を進めるのが一般的です。
TRIM関数:余分なスペースを除去する
TRIM関数は、文字列の先頭・末尾のスペースを削除し、文字間の連続スペースを1つに整理します。単語間の1スペースは保持されるため、氏名の「山田 太郎」のような表記は変わりません。
=TRIM(A2)
ただし、TRIMが確実に対象とするのは半角スペースです。全角スペースについては環境によって動作が異なる場合があるため、SUBSTITUTEと組み合わせて全角スペースを先に半角に変換してからTRIMを適用する方法が、より確実です。
=TRIM(SUBSTITUTE(A2, “ ”, ” “))
(「 」は全角スペース、「 」は半角スペースです)
日本語データでは全角スペースが混入しているケースが多いため、この組み合わせを標準として使うことをお勧めします。
ASC/JIS関数:全角・半角を統一する
ASC関数は全角の英数字・カタカナを半角に変換し、JIS関数はその逆(半角→全角)を行います。
=ASC(A2) (全角→半角)
=JIS(A2) (半角→全角)
どちらに統一するかは、コーポレートサイトの表記を基準にするとよいでしょう。英数字・カタカナを半角に統一するケースが多いですが、業界や企業によって異なります。統一方針を決めてから一括適用してください。
なお、Mac版ExcelではASC/JIS関数の動作がWindows版と異なる場合があります。複数のOS環境でファイルを共有している場合は、事前に動作確認をしておくことをお勧めします。
CLEAN関数:改行・制御文字を除去する
CLEAN関数は、印刷できない制御文字や改行コードを除去します。SFAやCRM、基幹システムからエクスポートしたCSVデータには、こうした制御文字が混入していることがあります。目視では気づきにくいため、他システムからのデータを扱う際は最初にCLEANを適用しておくと安全です。
=CLEAN(A2)
TRIM・ASC・CLEANを組み合わせると、スペース・全角・制御文字を1つの数式でまとめて処理できます。
=TRIM(ASC(CLEAN(A2)))
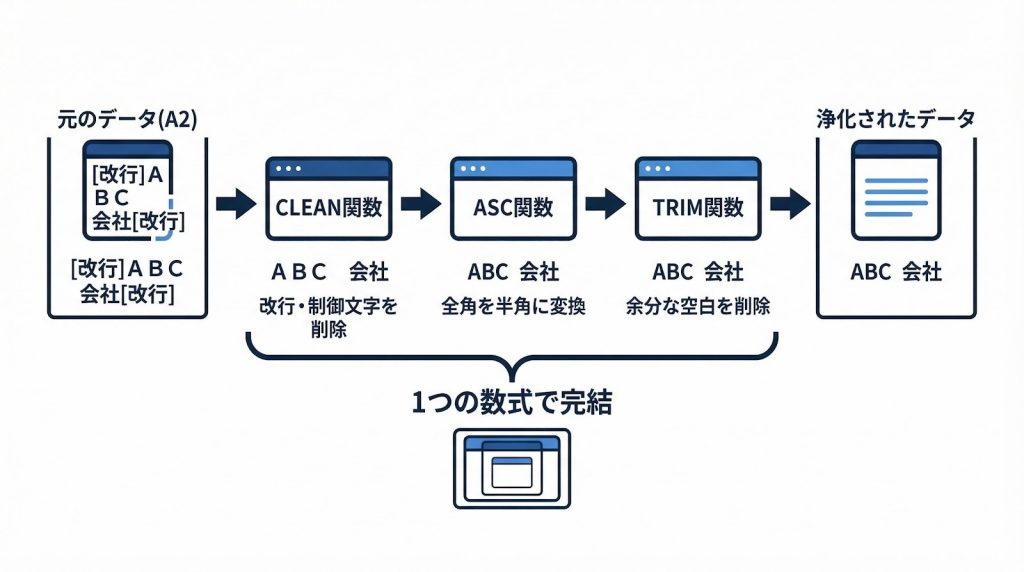
この数式をクレンジング用の列に適用し、クレンジング済みの値を照合キー列の参照元として使います。住所の表記ゆれについては、不動産登記法と住居表示法という異なる制度に起因する複雑な問題があり、デジタル庁が整備を進めているアドレス・ベース・レジストリ(2025年6月に町字データの正式版を公開済み)や、同庁が提供する住所正規化ツール「ABRジオコーダー」との照合が必要になるケースもあります。Excelの関数だけでは正規化が難しい場合があることを念頭に置いておいてください。
重複データの検出・削除と誤統合を防ぐ判定キーの設計

クレンジングが完了したら、いよいよ重複の検出と削除に入ります。ここで重要なのは、クレンジング済みの照合キー列を対象に重複を検出することです。
表記ゆれが残ったままの状態より検出精度が大幅に向上します。また、削除前には必ずバックアップコピーを取ってください。誤削除が発覚した際の復元手段を確保しておくことは、この工程の大前提です。
ステップ1:COUNTIF関数で重複フラグを立てる
重複を検出するには、COUNTIF関数を使って重複フラグ列を作成します。照合キー列(クレンジング済みの会社名+電話番号の結合値)を検索値に使うことで、会社名のみの照合より同一レコードの検出精度が高まります。
フラグ列の数式例は次のとおりです(E列が照合キー列の場合)。
=IF(COUNTIF($E$2:$E$100, E2)>1, “重複”, “”)
COUNTIF関数の検索範囲に絶対参照($E$2:$E$100)を使うことで、数式を下方向にコピーしても参照範囲がずれずに正確な重複カウントが得られます。
フラグ列を作成したら、「重複」と表示されたセルをフィルターで絞り込み、重複候補を一覧表示して内容を確認します。この目視確認を省略すると、同姓同名や同一社名の別企業を誤って重複と判定するリスクがあります。
ステップ2:条件付き書式と目視確認で安全に削除する
重複フラグを立てた後は、条件付き書式で重複セルを色付けして視覚的に確認しやすくします。設定手順は次のとおりです。
- 照合キー列を選択する
- 「ホーム」タブ→「条件付き書式」→「セルの強調表示ルール」→「重複する値」を選択する
- 色を設定して「OK」をクリックする
目視確認が完了したら、Excelの「重複の削除」機能(「データ」タブ)を使って削除します。この機能で複数列を指定する場合、指定した全列の値が一致するレコードのみが重複と判定されます。照合キーの列選択が削除精度を左右するため、慎重に設定してください。
削除を実行する前に、必ずファイルのコピーを別名で保存してください。「重複の削除」は実行直後であれば Ctrl+Z で元に戻すことができますが、ファイルを保存した後は復元できません。
削除を実行する前に、必ずファイルのコピーを別名で保存してください。残すべきレコードの選定基準としては、更新日が新しいもの・情報が充実しているものを優先するのが一般的です。
ステップ3:複合キーで誤統合を防ぐ判定設計
社名のみ・氏名のみの単一キーで照合すると、同一社名の別拠点や別法人を誤って統合するリスクがあります。電話番号や住所(都道府県)を組み合わせた複合キーで判定することで、このリスクを大幅に下げられます。
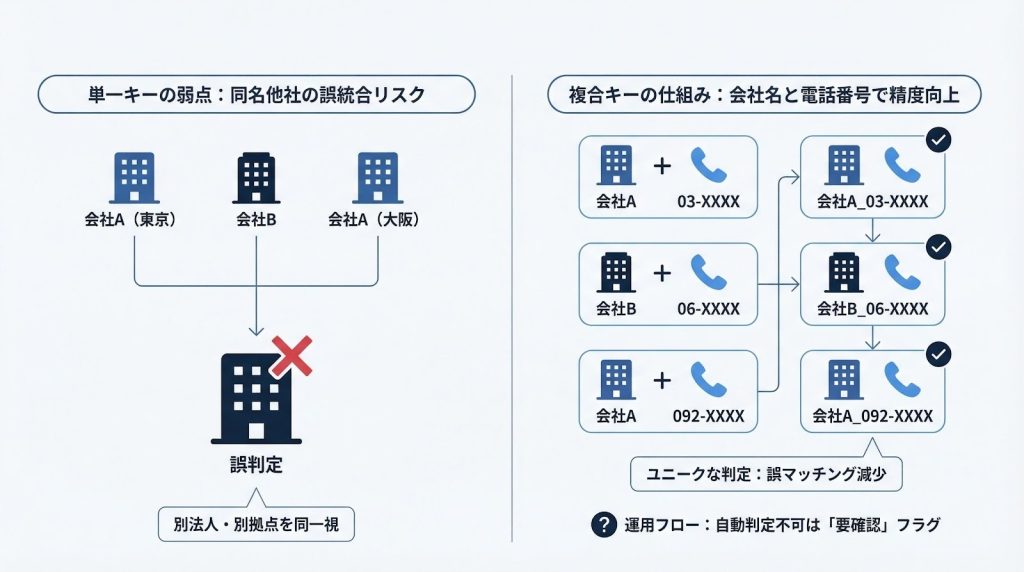
複合キーの設計例は次のとおりです。
| 照合の目的 | 複合キーの組み合わせ例 |
| 法人の同一性確認 | 会社名 + 電話番号 |
| 別拠点の区別 | 会社名 + 住所(都道府県) |
| 個人の同一性確認 | 氏名 + メールアドレス |
それでも自動判定が難しいケースは存在します。同一社名の別拠点・同姓同名の別人など、複合キーが一致しても実際には別レコードである場合や、逆に複合キーが一致しないのに同一人物である場合です。
こうしたケースには「要確認」フラグ列を追加し、担当者が目視で最終判断する運用フローを設けることで誤統合リスクを管理できます。
CDPツール比較ランキングおすすめ15選!主要機能や選び方を解説
名寄せ後のデータ品質を維持する運用ルールとExcelの限界
名寄せは一度完了させれば終わりではありません。入力ルールが整備されていなければ、時間が経つにつれて表記ゆれや重複が再び蓄積していきます。
まずExcel内でできる再発防止策を整え、それでも対応しきれない場合の移行判断基準を把握しておきましょう。
再発を防ぐ入力ルールとExcelの設定
名寄せ後に表記ゆれが再発する主な原因は、複数の担当者がそれぞれの判断で入力していることです。Excelの入力規則を使ってプルダウンリストを設定することで、会社名・部署名の表記ゆれを入力段階で防止できます。
設定手順は次のとおりです。
- プルダウンを設定したいセル範囲を選択する
- 「データ」タブ→「データの入力規則」を開く
- 「設定」タブで「リスト」を選択し、許可する値を入力する(または別シートのリスト範囲を参照する)
- 「エラーアラート」タブでスタイルを「停止」に設定する
エラーアラートを「停止」に設定すると、リスト外の値の入力を物理的にブロックできます。複数の担当者が入力するシートでは特に有効な設定です。
プルダウンリストだけでなく、担当者間で共有する入力ガイドラインも合わせて整備しておくと効果的です。「会社名は後株(〇〇株式会社)に統一」「電話番号はハイフンあり・半角で入力」といった具体的なルールを文書化して共有することで、ツールの設定だけでは防ぎきれない表記ゆれを減らせます。
Excelの限界と専用ツール・CRMへの移行判断
Excelでの名寄せ管理には、データ量や運用体制によって対応しきれなくなるタイミングがあります。次のような状況が重なってきたら、専用ツールやCRM/SFAへの移行を検討するサインです。
- データ件数が数千件を超え、関数の処理が重くなってきた
- 複数人が同時にファイルを編集する必要が生じた
- リアルタイムでのデータ更新・反映が必要になった
- ファイルの破損や誤上書きによるデータ消失リスクが無視できなくなった
代替手段の選択肢としては、大きく3つの方向性があります。
| 選択肢 | 向いているケース | 主な特徴 |
| Excelアドイン型ツール | Excelの操作感を維持したい・小規模 | Excel上で動作するため学習コストが低い |
| クラウド型名寄せツール | 法人データの名寄せ精度を高めたい | 法人番号との照合など専門機能を持つ |
| CRM/SFA移行 | 営業・マーケティング活動と連携したい | 名寄せ後のデータ活用まで一元管理できる |
さらにデータ量の増大や複数チャネルからの流入が常態化してきた場合、VLOOKUPやCOUNTIFによる手作業の名寄せには根本的な限界があります。
そこで、GENIEE CDPのような、WebサイトやSFA・CRMなど複数のタッチポイントから流入するデータをノーコードで自動集約し、ID名寄せ機能によって同一人物への紐付けを自動で行うツールが選択肢となります。
Excelでの関数操作に費やしていた工数を削減しながら、名寄せ後のデータをそのままマーケティング施策に活用できる点が、手作業管理との大きな違いです。ファイル破損リスクや更新頻度の限界を感じ始めたタイミングで、移行先の選択肢として検討してみてください。
データ活用の注意点とは?失敗を防ぐポイントや基本的な流れを解説
まとめ:Excelで名寄せを進めるための判断ポイント
この記事では、Excelで名寄せを行うための4工程を順に解説しました。各工程には対応する関数があり、SUBSTITUTE/TRIMでクレンジングを行い、COUNTIFで重複フラグを立て、VLOOKUPで情報を引き当てるという流れが基本になります。
作業精度を左右する最重要ポイントは2つです。1つは「クレンジングを重複検出より先に行う」こと。表記ゆれが残ったままでは、同一レコードを別レコードと誤判定してしまいます。もう1つは「社名・氏名の単一キーではなく、電話番号やメールアドレスを組み合わせた複合キーで同一性を判定する」こと。これが誤統合を防ぐ最も確実な方法です。
Excelでの名寄せに慣れてきた後、データ量の増加や複数チャネルからの継続的なデータ流入が課題になってきたタイミングでは、GENIEE CDPのような専用ツールへの移行も選択肢に入れてみてください。手作業の名寄せ工数を削減し、名寄せ後のデータをそのまま分析・施策活用につなげる仕組みを整えることが、次のステップになります。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。













