







データファブリック基盤構築における実装戦略:データメッシュとの違いと国産CDPの活用

この記事で分かること
- データファブリック基盤構築が大規模組織で求められる背景と、データサイロ化が引き起こす具体的な課題
- データファブリックとデータメッシュの根本的な違いと、自社に適したアーキテクチャの選び方
- データファブリック基盤構築における3層アーキテクチャの設計方法と実装上の5つの課題・対策
- グローバルプラットフォームと国産CDPの強み・弱みの比較と、規模・業種別の推奨プラットフォーム
- 段階的導入ロードマップ(4フェーズ)と、金融グループ・中堅企業の成功事例から学ぶ実践的な知見
金融機関やグループ企業を中心に、「データファブリック基盤構築」への関心が急速に高まっています。しかし、データファブリックとデータメッシュの違いを十分に理解しないまま導入を進めると、組織体制や技術選定において大きな失敗を招くリスクがあります。
本記事では、データファブリック基盤構築の実装戦略を体系的に解説し、データメッシュとの根本的な違いを明確にします。さらに、グローバルプラットフォームと国産CDPの選択肢を比較し、自社に最適なアーキテクチャの選定方法を提示します。DX推進部署やシステム部門の責任者の方々が、自社のデータ活用戦略を策定する際の実践的な指針としてご活用ください。
────────────────────────────────────────
データファブリック基盤構築が求められる背景

大規模組織が直面するデータサイロ化の課題
大規模な金融グループやコングロマリット企業では、組織の拡大とともにデータ管理の複雑性が増し、以下のような深刻な課題が発生しています。
- 事業部門ごとのデータ分散:各事業部が独立したシステムを運用し、データが分散・孤立している
- データ定義の不統一:同じ「顧客」という概念でも、部門ごとに異なる定義で管理されている
- アクセス権限の複雑性:個人情報を含むため、過度なアクセス制限によりデータ利活用が進まない
- 手作業による連携:部門間のデータ連携がExcelファイルの手動転送に依存している
- 分析スキルの属人化:データ分析ができる人材が限定的で、組織全体のボトルネックになっている
これらの課題を放置すると、経営判断の遅延、クロスセル機会の損失、コンプライアンスリスクの増大など、ビジネス上の深刻な影響が生じます。こうした状況を打開するために、「データファブリック基盤構築」という概念が注目を集めています。
データファブリック基盤構築の定義
データファブリック基盤構築とは、物理的にデータを一箇所に集約するのではなく、論理的な統合層を構築し、データの所在を意識せずにシームレスにアクセス・活用できるアーキテクチャを実現することです。このアーキテクチャが実現する主なキーポイントは以下の通りです。
- 論理的統合:データの物理的な移動を最小化し、既存システムへの影響を抑える
- セキュアなアクセス:アクセス権限を細かく制御し、コンプライアンスを確保する
- リアルタイム性:必要な時に最新データにアクセスできる環境を整備する
- スケーラビリティ:データ量の増加にも柔軟に対応できる拡張性を持つ
データファブリック基盤構築は、単なるデータ統合プロジェクトではなく、組織全体のデータ活用文化を変革するための戦略的な取り組みです。適切に実装することで、データドリブンな意思決定を組織全体に浸透させることができます。
────────────────────────────────────────
データファブリックとデータメッシュの根本的な違い

データメッシュとは
データメッシュは、データ所有権を各事業部門に分散させ、各部門が自律的にデータを管理・提供する分散型アーキテクチャです。テック企業を中心に注目されているアプローチで、以下の特徴を持ちます。
- 分散所有:各事業部がデータの所有権と責任を持つ
- 自律的管理:各部門が独立してデータパイプラインを構築・運用する
- API駆動:データを他部門に提供する際はAPIを通じて提供する
- ドメイン駆動設計:ビジネスドメインごとにデータ構造を設計する
どちらを選ぶべきか
データファブリックとデータメッシュは、根本的に異なるアーキテクチャです。以下の観点から、自社に適したアプローチを選択することが重要です。
データファブリック基盤構築が適切な場合:
- 金融機関、保険会社など、規制が厳しい業界
- グループ企業間でのデータ共有が必須
- 個人情報を含むデータが大量にある
- 既存システムの統合が優先課題
- 短期間での導入を希望
- 中央集約型のガバナンスを重視
データメッシュが適切な場合:
- テック企業など、組織の自律性が高い
- 各事業部門が独立したデータ戦略を持つ
- スケーラビリティが最優先
- 長期的な組織文化の変革に投資できる
- 各部門に高度なデータエンジニアリング人材がいる
一般的に、金融機関や大規模グループ企業では、規制対応やガバナンスの観点からデータファブリックが適しています。一方、高い技術力と組織の自律性を持つテック企業では、データメッシュが有効です。自社の組織体制、規模、成熟度を正確に把握した上で、適切なアーキテクチャを選択することが成功の第一歩です。
────────────────────────────────────────
データファブリック基盤構築の実装アーキテクチャ
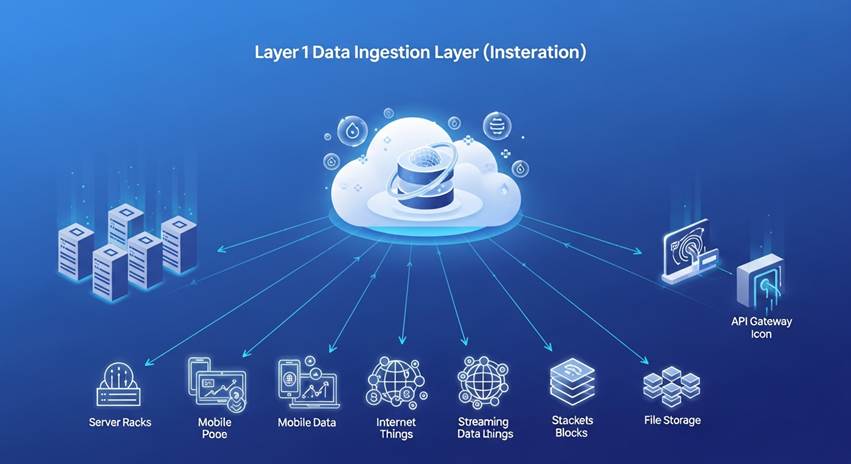
中核となるクラウドDWHの役割
データファブリック基盤構築では、クラウドDWHを中核に据えることが一般的なアプローチです。クラウドDWHは以下の点で優れており、データファブリックの実現に不可欠な役割を担います。
- スケーラビリティ:データ量の増加に自動対応し、運用負荷を軽減する
- パフォーマンス:複雑なクエリも高速実行し、リアルタイム分析を実現する
- セキュリティ:エンタープライズグレードの暗号化・アクセス制御を提供する
- ゼロコピー共有:データの物理的な複製なしにセキュアに共有できる
- AI/ML統合:生成AIモデルとの連携が容易で、高度な分析を実現する
実装の3層構造
データファブリック基盤は、以下の3層構造で実装することが推奨されます。各層の役割を明確にし、段階的に構築することで、リスクを最小化しながら効果的なデータ活用基盤を実現できます。
第1層:データ取り込み層
- 各事業部のシステムから、ETL/ELTツールでデータを取り込む
- 外部データプロバイダーからのデータ連携を実現する
- リアルタイムストリーミングデータの取り込みに対応する
第2層:統合・変換層
- クラウドDWH上でデータを統合・クレンジングする
- データ定義の統一化(マスタデータ管理)を実施する
- メタデータ管理(データカタログ)を整備する
第3層:利活用層
- AI/BIツールによる分析・可視化を実現する
- 各事業部への安全なデータ提供(アクセス制御)を行う
- 生成AIとの連携による自動分析機能を提供する
この3層構造を適切に設計することで、データの取り込みから活用まで一貫したデータフローを実現し、組織全体のデータ活用を促進することができます。
データファブリック基盤構築に活用できるCDPソリューションについては、GENIEE CDP製品サイトをご参照ください。
────────────────────────────────────────
データファブリック基盤構築における5つの実装課題と対策
データファブリック基盤構築を成功させるためには、実装過程で発生しやすい5つの課題を事前に把握し、適切な対策を講じることが重要です。
課題1:ガバナンスの複雑性 権限管理の失敗
個人情報を含むデータのアクセス権限が複雑化し、過度なアクセス制限によってデータ利活用が進まないケースが多く見られます。また、権限設定の漏れによるセキュリティリスクも深刻な問題です。根本原因は、事業部ごとに異なるセキュリティ要件を統一できていないこと、マスキング・匿名化のルールが不明確なこと、監査ログの管理体制が不十分なことにあります。
対策として、データ分類ルール(個人情報・機密情報・一般情報)を明確化し、事業部・職種・プロジェクト単位での細かいアクセス制御を設計することが重要です。また、データガバナンスオフィスを設置し、継続的に運用する体制を整えることが不可欠です。
課題2:データ品質の不統一 定義の混乱
各事業部で「顧客」「売上」などの定義が異なり、データ統合時に重複・矛盾が発生することで、分析結果の信頼性が低下します。マスタデータ管理(MDM)の仕組みがないことが根本原因です。対策として、MDMツールを導入し、重要な概念の定義を統一するとともに、メタデータ管理ツール(データカタログ)で定義を一元管理し、最重要データから段階的に統一化を進めることが効果的です。
課題3:組織体制の曖昧性——責任の所在不明
データファブリック基盤の運用責任が不明確で、問題発生時に誰が対応するのか分からない状況が生じます。データ部門とビジネス部門の役割分担が不明確なことが主な原因です。対策として、データガバナンスオフィス(DGO)を設置し、データオーナー・データスチュワード・データエンジニアの役割を明確化することが重要です。月次のガバナンス会議を開催し、課題を共有・解決する仕組みを構築してください。
課題4:段階的導入の失敗 スケール先行
最初から全データを統合しようとしてプロジェクトが停滞したり、個人情報を含むデータの取り込みでセキュリティ対応が追いつかないケースが多く見られます。対策として、段階的導入計画を策定し、第1段階ではログデータなど個人情報を含まないデータから開始することが重要です。セキュリティ・ガバナンス体制を強化した上で、段階的に個人情報を含むデータに拡大し、最終的に全社展開を実現します。
課題5:ツール選定の誤り スケーラビリティ不足
導入当初は問題なかったが、データ量が増加するとパフォーマンスが低下し、追加投資が必要になってROIが悪化するケースがあります。将来のデータ量・ユーザー数を過小評価することが根本原因です。対策として、3〜5年後の想定データ量・ユーザー数を見積もり、クラウドDWHのスケーラビリティを活用した自動スケーリングを設計することが重要です。AI/BIツールのパフォーマンスを大規模データセットで事前検証し、定期的な監視とチューニングを実施してください。
データ基盤の選定に迷われている方は、「AI基盤プラットフォーム比較ガイド」もご参考ください。主要プラットフォームの機能・コスト・サポート体制を詳しく比較しています。
────────────────────────────────────────
データファブリック基盤構築の実装パターン:グローバルプラットフォーム vs 国産CDP

グローバルプラットフォームの強みと課題
グローバルクラウドDWHと大手クラウドプロバイダーの統合アーキテクチャは、技術的な柔軟性、ペタバイト規模のスケーラビリティ、グローバル対応、豊富なエコシステムという点で優れています。グローバル展開を視野に入れた大規模企業や、複雑なカスタマイズが必要な場合に適しています。
一方で、アーキテクチャが複雑で専門知識が必要なこと、日本語サポートが限定的なこと、初期投資が大きいこと、金融規制対応(個人情報保護法・金融庁ガイドライン)の実装が複雑なことなど、国内企業にとっての課題も存在します。
国産CDPの選択肢と特徴
こうした課題に対して、国産CDPプラットフォームは異なるアプローチを提供します。国産CDPの主な特徴は以下の通りです。
- 日本企業向けの設計:個人情報保護法・金融庁ガイドラインなど日本の法規制に対応
- 手厚いサポート体制:日本語による専任サポート、導入支援、ガバナンス設計コンサルティング
- データファブリック基盤構築への対応:事業部門横断のデータ統合、セキュアなアクセス制御、メタデータ管理
- 同等の機能:AI/BIツール統合、自然言語分析、生成AI連携など、グローバルプラットフォームと同等の機能を提供
- 導入の容易さ:複雑な設定が不要で、短期間での導入が可能
- コスト効率:初期投資・運用コストが低く、ROIを早期に実現できる
- ガバナンス体制の構築支援:データガバナンスオフィスの立ち上げ、運用ルール策定をサポート
- 上場企業による信頼性:堅牢なセキュリティと継続的なサポート体制
CDP選定の詳細については、「CDP活用完全ガイド」をご覧ください。選定基準から導入事例まで詳しく解説しています。
────────────────────────────────────────
データファブリック基盤構築の段階的導入ロードマップ
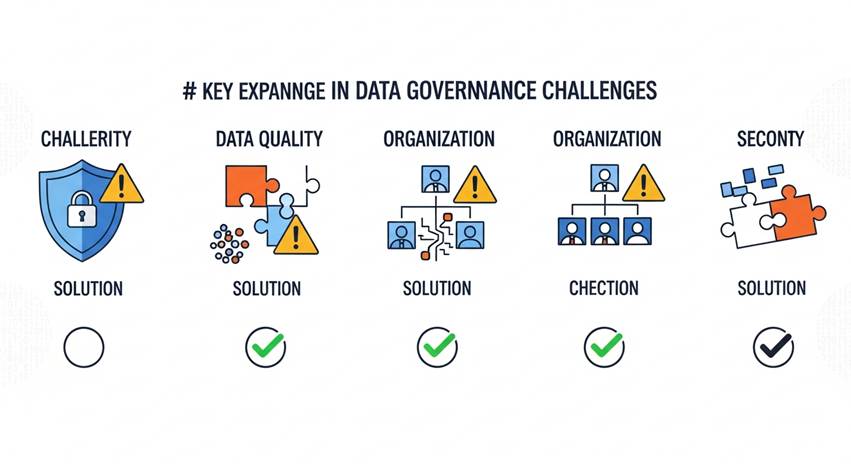
データファブリック基盤構築を成功させるためには、段階的な導入計画が不可欠です。以下の4フェーズで進めることで、リスクを最小化しながら確実に成果を積み上げることができます。
Phase 1:基盤設計・ガバナンス体制構築(3〜4ヶ月)
- ビジネス要件の定義(どのデータを統合するか、何を実現するか)
- データ分類ルール、アクセス権限の設計
- マスタデータ管理(MDM)の対象データを特定
- データガバナンスオフィス(DGO)の設置、役割定義
- プラットフォーム選定(グローバル vs 国産CDP)
- セキュリティ・コンプライアンス要件の整理
Phase 2:パイロット導入(3〜6ヶ月)
- 個人情報を含まないデータから開始(ログデータ、マーケティングデータなど)
- クラウドDWH/CDPの構築、テスト
- AI/BIツールの導入、ユーザー教育
- メタデータ管理(データカタログ)の整備
- ユーザーからのフィードバック収集、改善
Phase 3:セキュリティ強化・個人情報対応(2〜3ヶ月)
- マスキング・匿名化ルールの実装
- アクセス制御の細分化(事業部・職種・プロジェクト単位)
- 監査ログの記録・監視体制の構築
- 金融庁ガイドライン、個人情報保護法への対応確認
- 個人情報を含むデータの段階的取り込み
Phase 4:全社展開(6〜12ヶ月)
- 全事業部へのサービス提供開始
- グループ企業間のデータ共有実現
- 継続的なガバナンス運用(月次会議、定期監査)
- 新しいユースケースの開発支援
- 生成AI連携による高度な分析機能の提供
このロードマップは目安であり、自社の規模・組織体制・データ成熟度に応じて柔軟に調整することが重要です。特にPhase 1のガバナンス体制構築を丁寧に行うことが、後続フェーズの成功を左右します。
────────────────────────────────────────
データファブリック基盤構築の成功事例
事例1:金融グループのデータ統合(グローバルプラットフォーム活用)
複数の金融事業(銀行・証券・保険)を展開するある大手金融グループでは、各事業のデータが分散し、クロスセル機会を逃し続けていました。顧客の全体像を把握できないため、最適な金融商品を提案できない状況が続いていたのです。
同グループは、グローバルクラウドDWHを中核に据え、各事業のデータを統合するデータファブリック基盤を構築しました。ゼロコピー共有機能を活用することで、データの物理的な複製なしにセキュアなデータ共有を実現し、AI/BIツールによる自然言語分析も導入しました。
その結果、クロスセル機会の発掘により売上が大幅に向上し、データ分析の実行時間が数日から数時間へと劇的に短縮されました。さらに、現場主導のデータ活用が組織全体に定着し、データドリブンな意思決定文化が醸成されています。
事例2:中堅企業のデータ民主化(国産CDP活用)
営業・マーケティング部門でExcelによる手作業分析が常態化していたある中堅企業では、データ分析スキルが限定的な人材に依存し、組織全体のボトルネックになっていました。施策の効果測定に時間がかかり、市場変化への対応が遅れていたのです。
同社は国産CDPを導入し、営業・マーケティングデータを統合しました。AI/BIダッシュボードにより自然言語による分析を実現し、専門的なデータエンジニアリングスキルがなくても現場担当者が自ら分析できる環境を整備しました。導入期間はわずか数ヶ月と、短期間での効果実現を達成しています。
その結果、Excel作業が大幅に削減され、営業担当者が自ら分析・意思決定できるようになりました。マーケティング施策の効果測定が迅速化し、PDCAサイクルが加速しています。この事例は、高度な技術力がなくても、適切なプラットフォームを選択することで、短期間でデータ民主化を実現できることを示しています。
────────────────────────────────────────
まとめ:データファブリック基盤構築の成功要件
データファブリック基盤構築を成功させるためには、以下の4つの要件を満たすことが重要です。
1. データメッシュとの違いを理解した上での選択
データファブリックとデータメッシュは、根本的に異なるアーキテクチャです。自社の組織体制、規模、成熟度に応じて、適切なアーキテクチャを選択することが成功の第一歩です。特に金融機関や規制業界では、ガバナンスの観点からデータファブリックが適しています。
2. ガバナンス体制の構築が最優先
データファブリック基盤構築の成功は、技術ではなく「ガバナンス」で決まります。データガバナンスオフィスを設置し、データオーナー・データスチュワード・データエンジニアの役割を明確化した上で、継続的に運用することが必須です。
3. 段階的導入によるリスク低減
最初から全データを統合するのではなく、個人情報を含まないデータから開始し、段階的に拡大することでリスクを低減できます。各フェーズでユーザーからのフィードバックを収集し、継続的に改善することが重要です。
4. プラットフォーム選定が長期的な成功を左右
グローバルプラットフォームと国産CDPは、それぞれ異なる強みを持っています。グローバル展開・大規模データ・複雑なカスタマイズが必要な場合はグローバルプラットフォームが、日本国内での利用・規制対応・短期導入・コスト効率を重視する場合は国産CDPが適しています。
データファブリック基盤構築は、単なる技術導入ではなく、組織全体のデータ活用文化を変革するプロジェクトです。
自社の状況を正確に把握し、最適なプラットフォームを選定することで、長期的な競争優位性を確保することができます。
自社のデータファブリック基盤構築についてご相談されたい方は、GENIEE CDP製品サイトよりお気軽にお問い合わせください。専門のコンサルタントが貴社の状況に合わせた最適な導入プランをご提案いたします。
AX推進に関するご相談もお気軽にお問い合わせください。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。














