データマートとは?DWH・データレイクとの違いと構築手順を解説
データ基盤の構築や運用において、「データレイク」「データウェアハウス(DWH)」「データマート」という用語が頻繁に登場しますが、それぞれの役割や違いを正確に理解している方は意外と少ないのではないでしょうか。
特に、BIツールでの分析が遅い、エンドユーザーがテーブル構造を理解できずデータ活用が進まないといった課題を抱えている企業では、データマートの適切な設計と運用が解決の鍵となります。
本記事では、データマートの技術的定義と役割を明確にし、DWHとの決定的な違いを「データ粒度」「更新頻度」「利用目的」といった多角的な視点から整理します。さらに、実際の構築手順やテーブル設計のポイント、業務シーン別の活用例を具体的に解説することで、明日から取り組めるデータマート構築の道筋を示します。
データマートは現場の分析速度を劇的に向上させますが、自社構築には専門知識と工数が必要です。
「データ分析の専門家不在」や「構築工数の削減」が課題なら、DWHとマート機能を統合したGENIEE CDPのようなツールの活用も選択肢です。この機会にぜひCDPをご検討ください。
CDPツール比較15選!おすすめランキング・機能・選び方を徹底解説
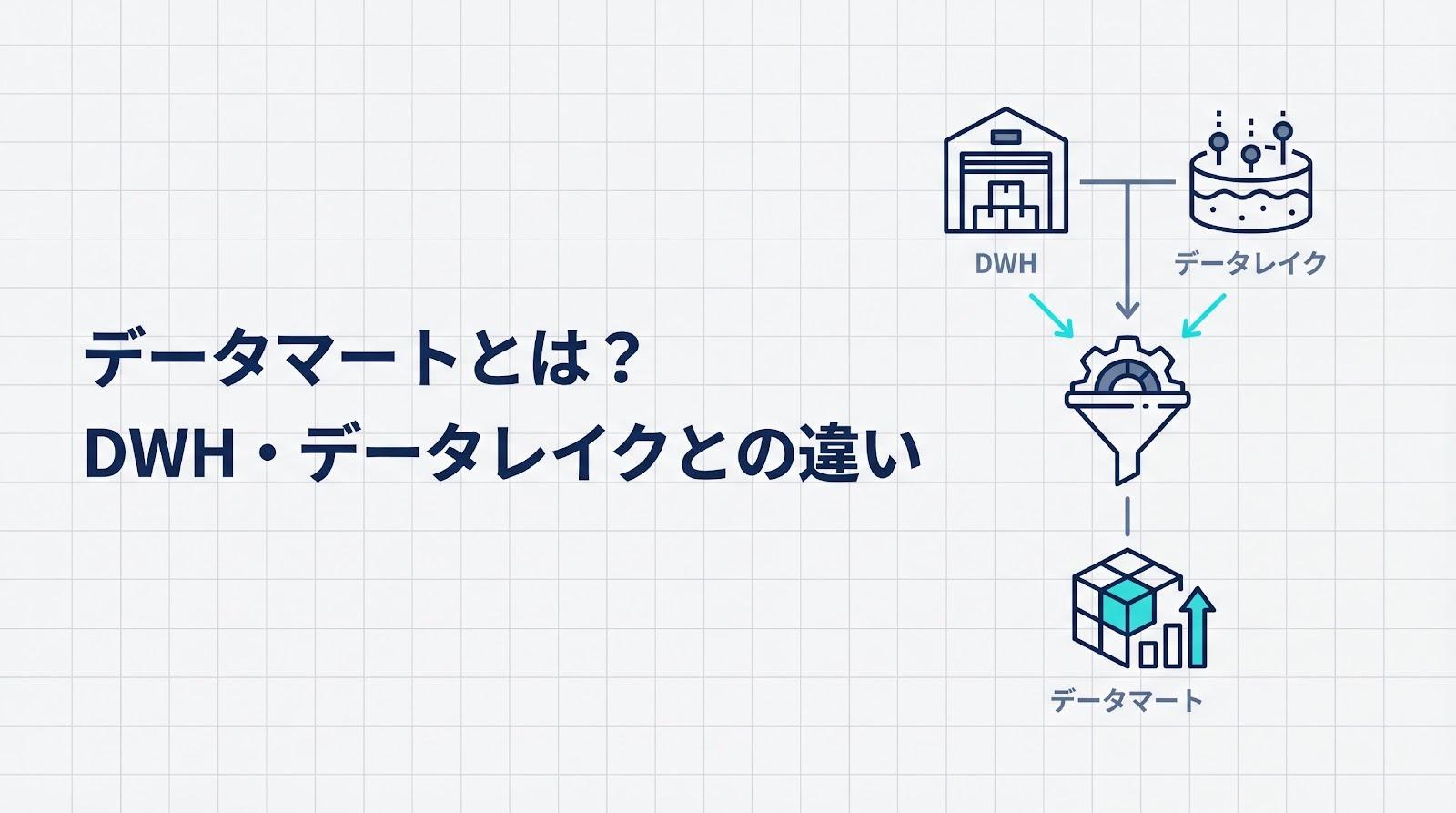
データマートとは?データレイク・DWH・データマートの三層構造における位置づけ

データ基盤を構成する「データレイク」「データウェアハウス(DWH)」「データマート」は、それぞれ異なる役割を担いながら相互に補完し合う関係にあります。
この章では、各層の技術的定義と役割を整理し、なぜ現代のデータ活用においてデータマートが不可欠なのか、その背景と三層構造の全体像を解説します。
データマートの技術的定義と役割
データマートとは、データウェアハウス(DWH)から特定の業務目的や部門のために抽出・加工されたデータセットを指します。営業部門向けの売上分析データマートや、マーケティング部門向けの顧客分析データマートなど、エンドユーザーが直接分析しやすいように最適化された構造を持つのが特徴です。
データマートの最大の役割は、ユーザーの利便性を高めることにあります。DWHが全社横断的なデータを網羅的に保持するのに対し、データマートは特定の業務領域に特化してデータを絞り込み、事前に集計やディメンション(分析軸)の整理を行うことで、BIツールでの分析を高速化し、SQLの専門知識がないユーザーでも直感的にデータを扱えるようにします。
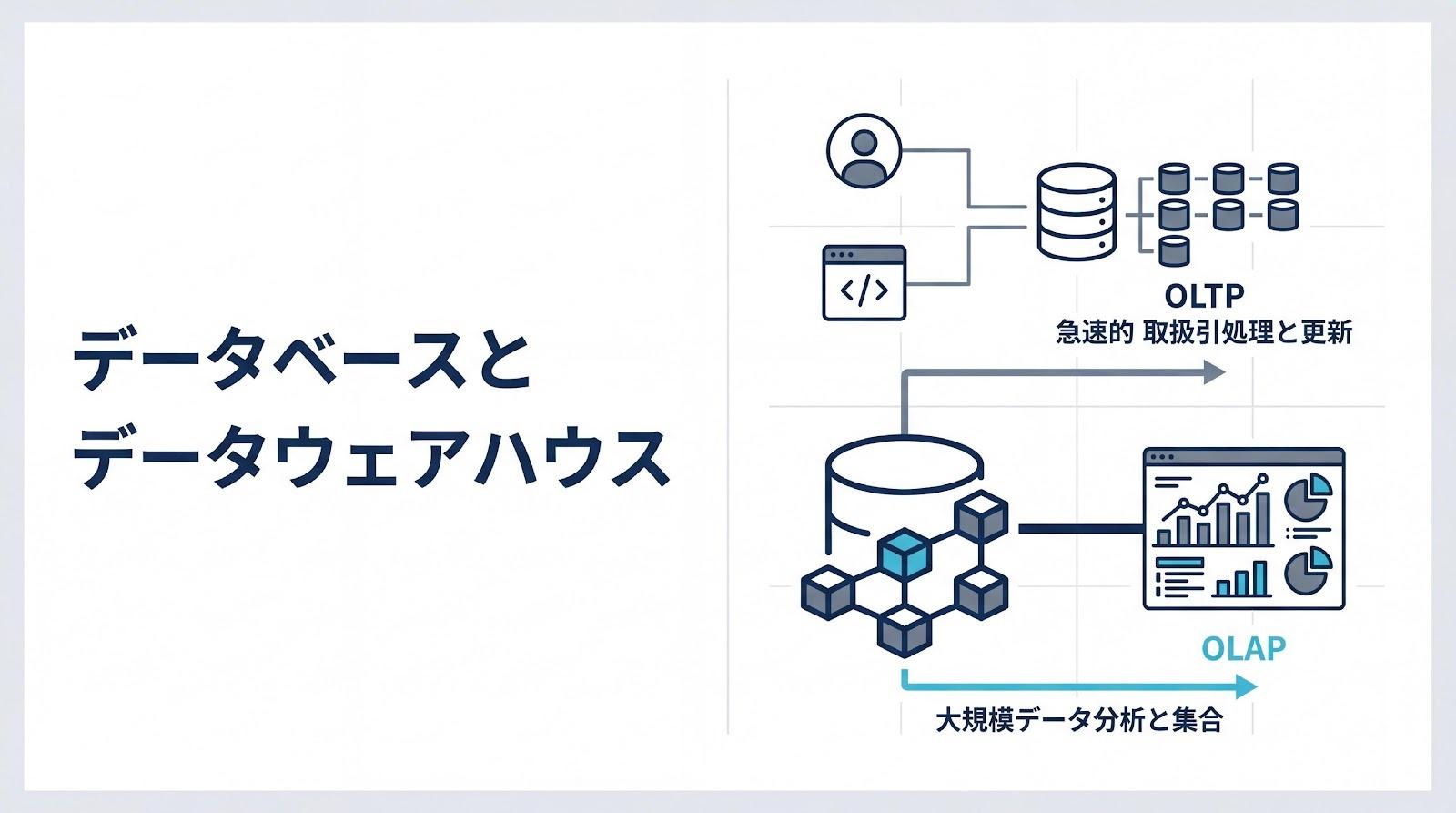
データレイク・DWH・データマートの三層構造
データ基盤の標準的なアーキテクチャは、「データレイク(生データ)」「DWH(統合データ)」「データマート(活用データ)」という三層構造で表現されます。これはしばしば「食材倉庫」「厨房」「料理」に例えられます。
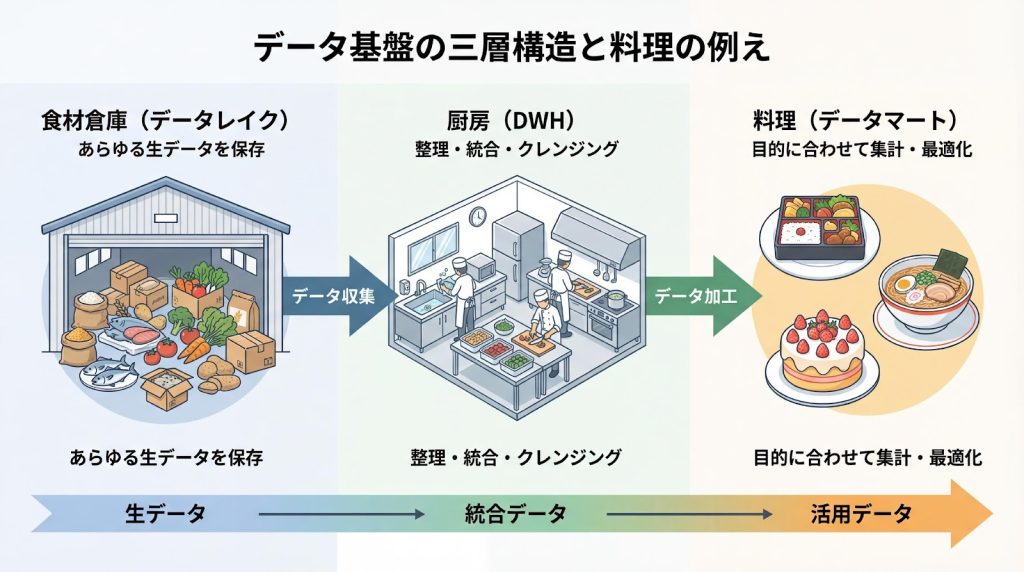
データレイクは、あらゆるシステムやログから収集された生データを、元の形式のまま大量に保管する「食材倉庫」です。構造化データだけでなく、画像や動画、IoTセンサーデータなど非構造化データも含めて蓄積します。
次に、DWHはデータレイクから必要なデータを取り出し、クレンジング(重複排除や欠損値補完)やスキーマ統一を行って、全社で一貫性のあるデータとして整理する「厨房」の役割を果たします。そして最後に、データマートはDWHから特定の業務目的に合わせてデータを抽出・集計し、すぐに分析できる形に仕上げた「料理」として提供されます。
この三層構造により、生データの柔軟な保管、全社統一のデータ品質管理、そして現場での迅速な分析という、それぞれの要求を同時に満たすことが可能になります。
なお、近年では顧客データ活用に特化したGENIEE CDPのように、実質的にDWHとデータマートの役割を兼ね備え、統合管理を容易にするプラットフォームも利用されています。
データマートが必要とされる3つの理由
データマートの導入が推奨される背景には、主に「パフォーマンス向上」「使いやすさの改善」「セキュリティの強化」という3つの理由があります。
1. パフォーマンスの向上
DWHは全社のデータを網羅的に保持するため、テーブル数やレコード数が膨大になりがちです。このような環境で複雑な集計クエリを実行すると、処理に時間がかかり、BIツールのダッシュボード表示が遅延する原因となります。データマートでは、分析に必要なデータだけを事前に抽出・集計しておくことで、クエリ実行速度を劇的に向上させることが可能です。
2. 使いやすさの改善
DWHのテーブル構造は、データの正規化や統合管理を重視するため、エンドユーザーにとっては複雑で理解しづらいことがあります。
データマートでは、スタースキーマなどのシンプルな構造を採用し、ビジネス用語に沿ったテーブル名やカラム名を設定することで、SQLの専門知識がない現場担当者でも直感的にデータを扱えるようになります。
3. セキュリティの強化
DWHには機密性の高いデータが含まれることが多く、全社員に対して全データへのアクセスを許可するのはリスクが伴います。データマートを部門ごとに構築することで、必要最小限のデータのみを公開し、アクセス権限を細かく制御できるため、情報漏洩のリスクを低減できます。
データマートとDWHの決定的な違い|データ粒度・更新頻度・利用目的の比較
データマートとDWHは、どちらも企業のデータ活用を支える重要な要素ですが、その設計思想や運用方法は大きく異なります。
この章では、データ粒度、更新頻度、対象ユーザーといった多角的な指標でDWHとデータマートを比較し、自社のニーズに合わせてどちらを優先すべきかの判断材料を提供します。
データ粒度とテーブル構造の違い
DWHは全社横断的な明細データを保持し、トランザクション単位での詳細な記録を維持します。例えば、ECサイトのDWHであれば、個々の注文明細や顧客の行動ログが1件1件記録されています。
これに対し、データマートは特定の分析目的に合わせて集計されたサマリーデータを保持します。たとえば、「月別・商品カテゴリ別の売上合計」や「顧客セグメント別の購買頻度」といった形で、あらかじめ集計済みのデータを格納します。
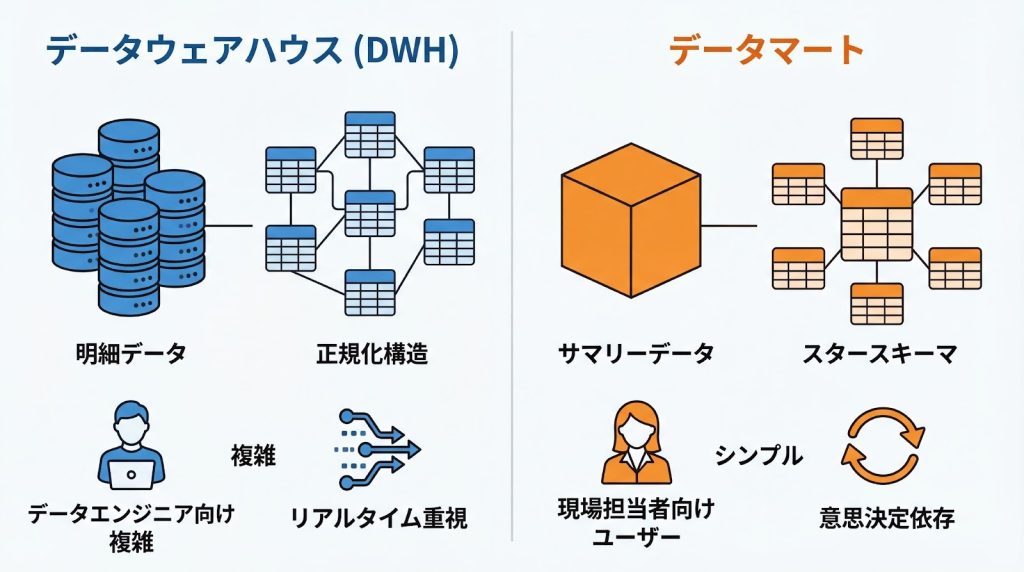
テーブル構造の面では、DWHは正規化されたリレーショナルモデルを採用することが多く、データの一貫性と柔軟性を重視します。一方、データマートでは分析のしやすさを優先し、スタースキーマを用いたシンプルなテーブル設計が推奨されます。
スタースキーマは、中心にファクトテーブル(売上や注文などの事実データ)を配置し、周囲にディメンションテーブル(商品、顧客、時間などの属性データ)を配置する構造で、結合回数を最小限に抑えることができます。
更新頻度と鮮度管理の違い
DWHは、基幹システムやトランザクションデータベースからリアルタイムまたは短い間隔(数分~数時間)でデータを取り込み、常に最新の状態を維持することが求められます。特に、在庫管理や需要予測など、リアルタイム性が重視される用途では、DWHの鮮度管理が重要です。
一方、データマートの更新頻度は、業務上の意思決定サイクルに合わせて柔軟に設計されるべきです。たとえば、月次の経営レポート用データマートであれば月1回の更新で十分ですし、日次の営業ダッシュボード用であれば毎朝バッチ処理で更新する、といった形です。
データマートの更新タイミングを業務サイクルに合わせることで、不要な処理負荷を避けつつ、必要なタイミングで最新のデータを提供できます。
利用目的と対象ユーザーの違い
DWHは、データアナリストやデータエンジニアといった専門職が、複雑な分析や機械学習モデルの構築に利用することを想定しています。そのため、SQLやPythonなどのプログラミングスキルを持つユーザーが、柔軟にデータを抽出・加工できる環境が求められます。
これに対し、データマートは現場の担当者がセルフサービスで活用できるよう、使い勝手が最適化されています。SQLを使わずにBIツールで直感的に分析できるよう、テーブル構造がシンプルで、カラム名もビジネス用語に沿った分かりやすい名称が設定されます。
営業担当者がTableauやPower BIでダッシュボードを作成したり、マーケティング担当者がLookerで顧客セグメントを抽出したりする際に、データマートが活躍します。
データマートの具体的な設計手順
データマートの構築は、要件定義から実装、ツール選定まで、体系的なプロセスを踏むことが成功の鍵となります。この章では、実践的な6ステップを順に解説し、モダンなELT手法やクラウドDWHの選び方についても触れます。
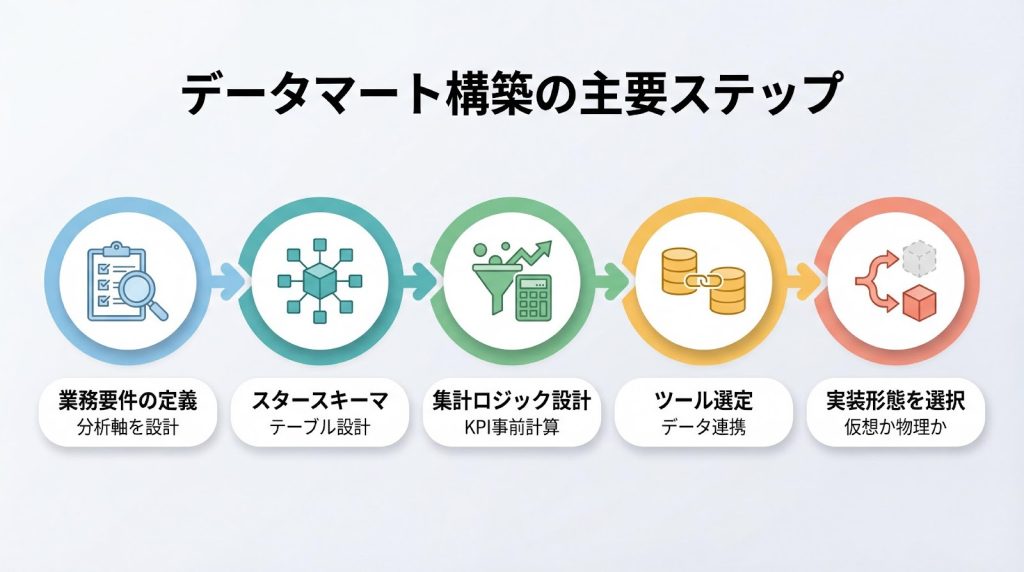
ステップ1: 業務要件の定義と分析軸の設計
データマート構築の第一歩は、誰が何の目的でどの指標を分析したいかという業務要件を明確にすることです。たとえば、「営業部門が月次で売上推移を把握し、商品カテゴリ別・地域別の実績を比較したい」といった具体的なニーズをヒアリングします。
この段階で重要なのは、分析の粒度(日次・月次など)を誤ると再構築が必要になるため、現場の要件を詳細にヒアリングすることです。
たとえば、月次集計だけで良いと思っていたが、後から週次での分析が必要になった場合、元のデータマートでは対応できず、設計をやり直すことになります。また、分析軸(時間、商品、顧客、地域など)を洗い出し、どのディメンションが必要かを整理します。
ステップ2: スタースキーマによるテーブル設計
業務要件が固まったら、次はテーブル設計です。データマートでは、スタースキーマが最も推奨される設計パターンです。スタースキーマは結合回数を最小限に抑え、BIツールでの集計処理を高速化するのに最も適した構造です。
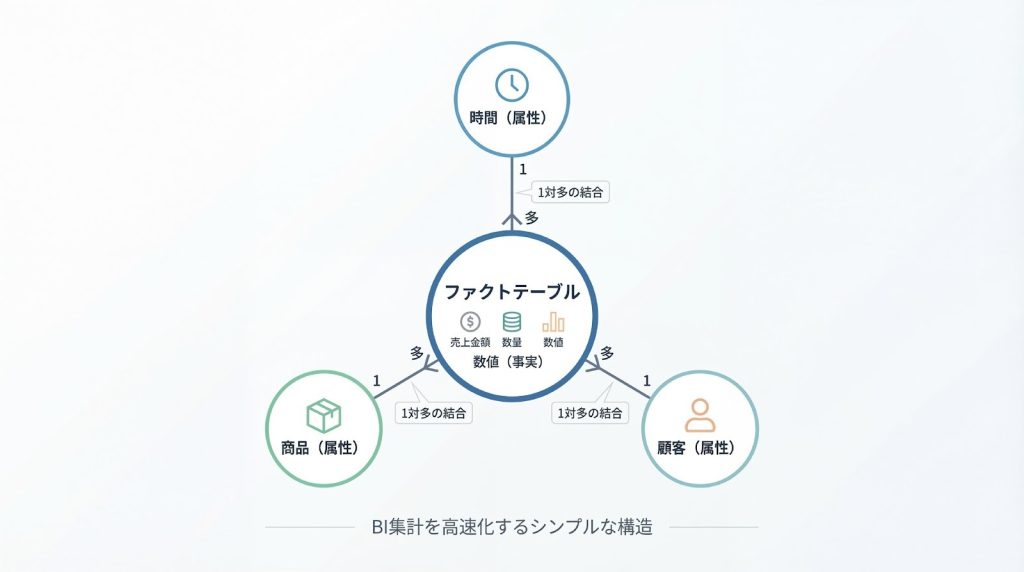
スタースキーマの中心には、ファクトテーブル(売上明細、注文明細など)を配置します。ファクトテーブルには、売上金額や数量といった数値データ(メジャー)と、各ディメンションテーブルへの外部キーが格納されます。
そして、ファクトテーブルの周囲に、商品マスター、顧客マスター、時間マスター、地域マスターといったディメンションテーブルを配置します。ディメンションテーブルには、商品名やカテゴリ、顧客の属性情報、日付や曜日といった分析軸の情報が含まれます。
この構造により、BIツールでは「商品カテゴリ別の月次売上」といった集計を、ファクトテーブルと各ディメンションテーブルを1回ずつ結合するだけで実現できるため、クエリがシンプルで高速になります。
ステップ3: 集計ロジックと事前集計の設計
データマートの大きなメリットの一つは、頻繁に使用する指標を事前に計算しておくことで、ユーザーの待ち時間をゼロにできる点です。たとえば、売上合計や平均単価などの主要KPIを事前に集計しておくことで、複雑な計算を都度行う必要がなくなります。
集計ロジックを設計する際は、以下のポイントを考慮します。まず、どの指標を事前集計するか(売上合計、平均単価、前年比など)を決定します。次に、集計の粒度(日次、週次、月次など)を定義し、最後に集計のタイミング(バッチ処理の実行時刻)を決めます。
たとえば、営業ダッシュボード用のデータマートでは、毎朝6時に前日までの売上データを日次・商品別・地域別に集計し、売上合計、平均単価、前年同日比といった指標を計算してテーブルに格納します。これにより、ユーザーが朝一番にダッシュボードを開いた際、すでに計算済みのデータが表示され、待ち時間なく分析を開始できます。
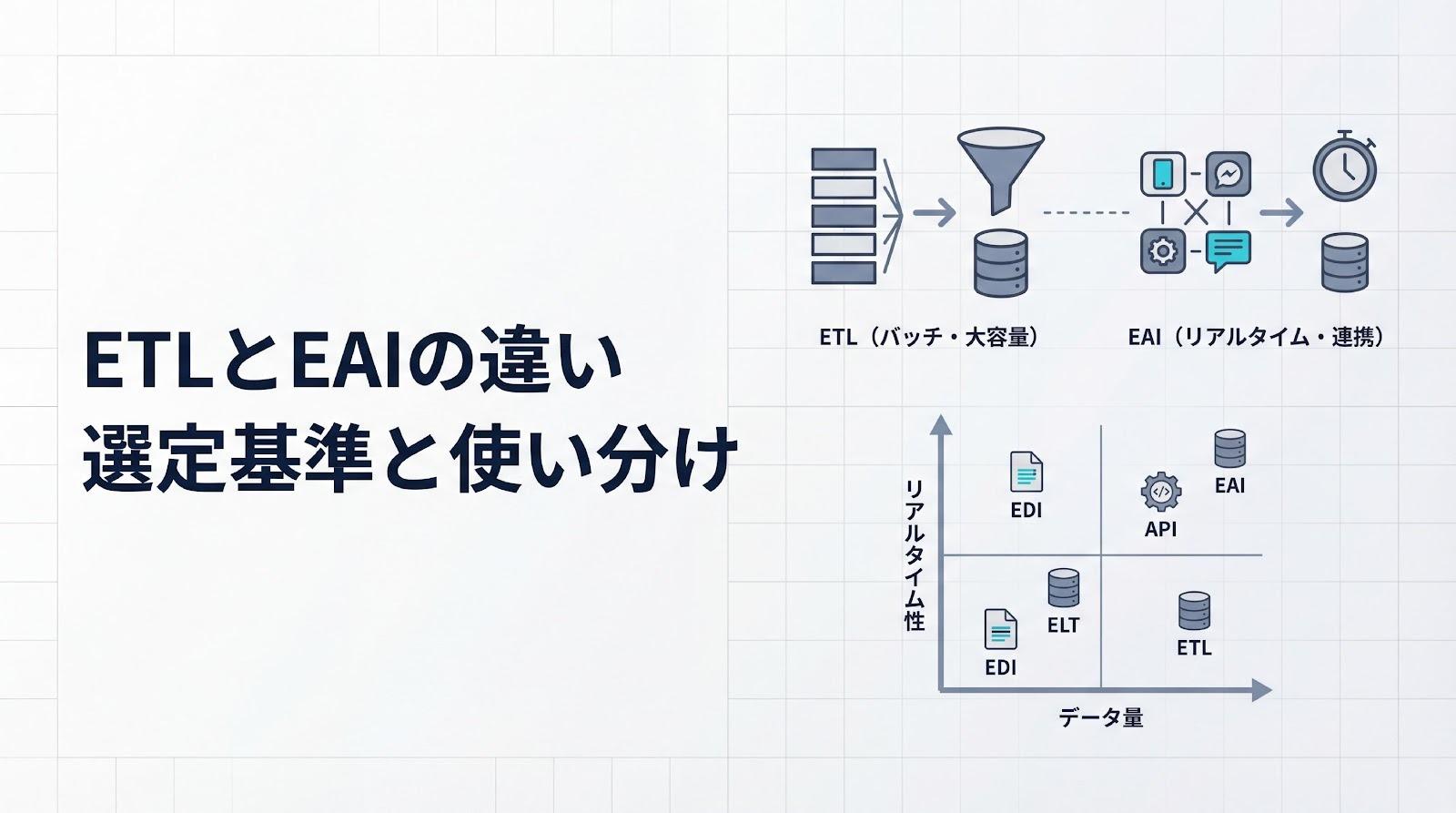
ステップ4: ETLツールの選定(従来型とモダンスタック)
データマートへのデータ投入には、ETL(Extract, Transform, Load)ツールを使用します。従来型のETLツールとしては、Informatica、Talend、DataSpiderなどがあり、GUIでデータ変換フローを設計できるのが特徴です。
近年では、ELT(Extract, Load, Transform)と呼ばれるモダンなアプローチも普及しています。ELTでは、まずデータをクラウドDWHにロードしてから、DWH内でSQLを使って変換処理を行います。dbtやAirflowといったツールが代表例で、バージョン管理やテストの自動化が容易になるメリットがあります。
専門人材が不足している場合、ノーコードでデータ統合・マート化が可能なプラットフォームの選択が工数削減に直結します。たとえばGENIEE CDPのようにデータ統合からマート化までをノーコードで完結できるプラットフォームを選択することで、自前でパイプラインを構築する手間を省き、分析開始までのリードタイムを大幅に短縮できます。
ステップ5: 仮想データマート(View)と物理データマート(実体化)の選択
データマートの実装形態には、仮想データマート(View)と物理データマート(実体化)の2つがあります。それぞれにメリット・デメリットがあり、コストとパフォーマンスのトレードオフを考慮して選択する必要があります。
仮想データマート(View)
仮想データマートは、DWH上にViewを作成し、クエリ実行時に都度データを集計する方式です。
メリットは、常に最新のデータが参照できることと、ストレージコストがかからないことです。デメリットは、クエリ実行のたびに集計処理が走るため、パフォーマンスが低下する可能性があることです。
物理データマート(実体化)
物理データマートは、集計済みのデータを実際のテーブルとして保存する方式です。メリットは、クエリが高速に実行できることです。デメリットは、ストレージコストがかかることと、更新タイミングによってはデータの鮮度が落ちることです。
一般的には、クエリ頻度が高く、パフォーマンスが重視される場合は物理データマートを、更新頻度が高く、常に最新データが必要な場合は仮想データマートを選択します。クエリ頻度やデータ量に応じてViewと物理テーブルを使い分けることで、コストとパフォーマンスの最適なバランスを実現できます。
データマートの実装・活用具体例
具体的な業務シーンに即したテーブル設計のパターンと、先進企業の導入事例を紹介します。この章を通じて、自社での活用イメージを具体化するためのヒントを提供します。
データマートの実装例
売上分析データマートの実装パターン
売上分析データマートは、時間・商品・店舗のディメンションを組み合わせ、多角的なドリルダウンが可能な構造を構築します。
中心となるファクトテーブルには、売上明細(売上日、商品ID、店舗ID、売上金額、数量など)を格納し、周囲に時間ディメンション(日付、曜日、週、月、四半期、年など)、商品ディメンション(商品名、カテゴリ、ブランド、価格帯など)、店舗ディメンション(店舗名、地域、店舗規模など)を配置します。
前年比や予算達成率などの頻出指標をあらかじめ保持することで、経営ダッシュボードの更新をスムーズにします。たとえば、月次の売上サマリーテーブルには、売上合計、前年同月比、予算達成率、平均客単価といった指標を事前に計算して格納しておくことで、経営会議用のレポート作成が数秒で完了します。
顧客分析データマートの実装パターン
顧客分析データマートは、RFM分析やLTV(顧客生涯価値)算出など、マーケティングに不可欠な顧客分析を容易にする設計が求められます。中心となるファクトテーブルには、購買履歴(購買日、顧客ID、商品ID、購買金額など)を格納し、周囲に顧客ディメンション(顧客名、年齢、性別、地域、会員ランクなど)、商品ディメンション、時間ディメンションを配置します。
RFM分析(Recency: 最終購買日、Frequency: 購買頻度、Monetary: 購買金額)を行うための集計テーブルを作成し、顧客ごとのRFMスコアを事前に計算しておくことで、セグメント抽出が高速化されます。
また、GENIEE CDPが提供するようなAIによる自然言語サポート機能を備えたツールは、専門知識のない現場担当者によるデータ活用を強力に支援します。たとえば、「先月の優良顧客セグメントを抽出して」「月次売上推移を棒グラフで出して」といった自然言語の指示だけで、自動的にデータが集計され、グラフやダッシュボードが生成されるような環境を整えることも可能です。
データマート実装の企業事例
実装事例:メルカリのBigQueryを活用したCRM施策
株式会社メルカリでは、各マイクロサービスにデータが散在し、全社横断的なデータ活用やCRM施策のためのデータ整備に課題がありました。特に、データ活用が民主化される一方で、ガバナンスの維持・管理が難しくなっていました(出典URL: https://primenumber.com/blog/01-2024-mercari)。
メルカリはデータウェアハウスとしてGoogle BigQueryを導入し、データ分析基盤を構築しました。これにより、各サービスから収集したデータを一元的に集約し、分析やマーケティング、意思決定など様々な用途で社内メンバーが活用できる環境を整備しました。
この基盤は、CRMツールへ連携するデータソースとして活用され、Eメール通知やクーポン付与、キャンペーン配信などの顧客アプローチ施策に利用されています。また、また、GitHubを活用したクエリ管理の仕組みを整備することで、データガバナンスが大幅に向上し、データ品質の改善と障害発生リスクの低減を実現しました。
整備されたデータ基盤はCRMツールと連携し、Eメール通知やクーポン付与、キャンペーン配信などの顧客アプローチ施策に活用されています。
実装事例:MonotaROのリアルタイムデータ分析基盤
株式会社MonotaROは、「データドリブンカンパニー」を掲げていますが、旧来のオンプレミス環境のデータ分析基盤では、総計100億レコードに及ぶ膨大なデータの取り扱いや、リアルタイムな分析に限界がありました(出典URL: https://cloud.google.com/blog/ja/topics/customers/monotaro-bigquery)。
MonotaROはデータ分析基盤をGoogle BigQueryに移行しました。これにより、購買データ、商品データ、Webアクセスログなど多種多様なデータをリアルタイムに収集・分析・可視化できる環境を内製で構築しました。
データ分析基盤の統合により、データアップロードの安定性が向上し、運用管理の工数が削減されました。データ分析基盤の統合により、データアップロードの安定性が向上し、運用管理の工数が削減されました。
ニアリアルタイムでのデータ同期が実現し、従来は月1回だった重いバッチ処理を日次で実行できるようになったことで、精度の高い情報に基づいた改善サイクルが加速しました。
データマート運用における課題と対策について

データマートを量産すると、「サイロ化」「管理の複雑化」「コスト増」という3大リスクが顕在化します。こ
の章では、これらの課題への具体的な処方箋を提示し、持続可能な運用体制の作り方を解説します。
課題1: データサイロ化のリスクと対策
データマートを部門ごとに個別に構築すると、同じ指標でも計算ロジックが異なり、部門間で数字が一致しないという問題が発生します。たとえば、営業部門の売上集計とマーケティング部門の売上集計で、集計期間や対象範囲が微妙に異なり、経営会議で混乱を招くケースがあります。
この問題を防ぐには、全社共通のマスターデータを一元管理し、各マートがそれを参照する仕組みを整えることが重要です。商品マスター、顧客マスター、組織マスターなどの基幹マスターデータをDWH側で統一管理し、各データマートはそのマスターを参照する形で設計します。
【関連記事】サイロ化とは?語源・原因・解消ステップをわかりやすく解説
また、GENIEE CDPのようにマーケティングツール群と標準連携が可能な基盤を採用することで、データ活用までのリードタイムを最小化し、サイロ化を防ぐ効率的な運用が可能になります。
課題2: データ鮮度管理の複雑化と対策
データマートが増えると、どのマートがいつ更新されたのか、どのデータソースから作られたのかが不透明になり、古いデータを参照してしまうリスクが高まります。特に、複数のマートが相互に依存している場合、更新順序を誤ると整合性が崩れます。
この課題に対しては、データカタログを整備し、各マートの最終更新日時や担当者を可視化することが有効です。データカタログツール(Alation、Collibra、Apache Atlasなど)を導入し、各データマートのメタデータ(テーブル名、カラム定義、更新頻度、データソース、担当者など)を一元管理します。
また、データリネージュ(データの流れ)を可視化することで、どのマートがどのDWHテーブルから作られ、どの順序で更新されるべきかを明確にします。
課題3: ストレージコストとコンピュートコストの増大と対策
クラウドDWH(BigQuery、Redshift、Snowflakeなど)では、ストレージ容量とクエリ実行量に応じて課金されます。データマートを無計画に増やすと、ストレージコストとコンピュートコストが急増し、予算を圧迫します。
コスト最適化のためには、利用頻度の低いデータマートを定期的に棚卸しし、削除またはコールドストレージへ移動させる運用ルールが不可欠です。
たとえば、四半期ごとにデータマートの利用状況をレビューし、過去3ヶ月間アクセスがないマートは削除候補とします。また、長期保存が必要だが頻繁にアクセスしないデータは、低コストなストレージ階層(Amazon S3 Glacier Deep Archive、Azure Archive Blob Storageなど)へ移動させることで、コストを大幅に削減できます。
データマート運用のベストプラクティス
データマート運用を成功させるためには、スモールスタートでの成功体験の作り方や、ユーザートレーニングによるセルフサービス化の促進が重要です。
まずは特定の1部門で成果を出し、そのナレッジを横展開していくアプローチが、全社的なデータ活用文化の醸成に有効です。たとえば、営業部門で売上分析用のデータマートを構築し、ダッシュボードで可視化して成果を出した後、そのノウハウをマーケティング部門や管理部門に展開していきます。
また、ユーザートレーニングを実施し、現場担当者がBIツールを使いこなせるようにすることも重要です。定期的なハンズオンセミナーやマニュアルの整備により、IT部門への問い合わせを減らし、セルフサービスでのデータ活用を促進できます。
データマート構築の設計手順と運用のポイントまとめ
データマートはDWHを補完し、現場の意思決定を加速させるための「使いやすいデータ」を提供する存在です。DWHが全社横断的なデータを網羅的に保持するのに対し、データマートは特定の業務目的に特化してデータを絞り込み、事前に集計やディメンションの整理を行うことで、BIツールでの分析を高速化し、SQLの専門知識がないユーザーでも直感的にデータを扱えるようにします。
構築にあたっては、業務要件の徹底した洗い出しと、自社の技術スタックに合ったツール選定が成功の鍵を握ります。まず、誰が何の目的でどの指標を分析したいかを明確にし、分析の粒度と分析軸を定義します。
運用面では、データサイロ化、鮮度管理の複雑化、コストの増大という3大リスクに注意が必要です。全社共通のマスターデータ管理、データカタログによるメタデータの可視化、定期的なマート棚卸しによるコスト最適化といった対策を講じることで、持続可能な運用体制を構築できます。
最後に、スモールスタートで特定の1部門での成功体験を作り、そのナレッジを横展開していくアプローチが、全社的なデータ活用文化の醸成につながります。もし自社での構築や運用に不安がある場合は、専門家不在でも高度な分析が可能なGENIEE CDPの導入を検討してみてはいかがでしょうか。現場担当者がセルフサービスでデータを活用できる環境を整え、組織全体のデータドリブンな意思決定を促進しましょう。
データマート構築は、一度作って終わりではなく、継続的な改善と運用が求められる取り組みです。本記事で解説した設計手順と運用のポイントを参考に、自社のデータ活用を次のステージへ引き上げる第一歩を踏み出していただければ幸いです。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。