データパイプラインとは?ETLとの違いから設計・構築手順まで解説
「データを活用したいが、複数のシステムに散在していて統合できない」「手動でのデータ抽出・加工に時間がかかりすぎる」こうした課題を抱える企業が増えています。
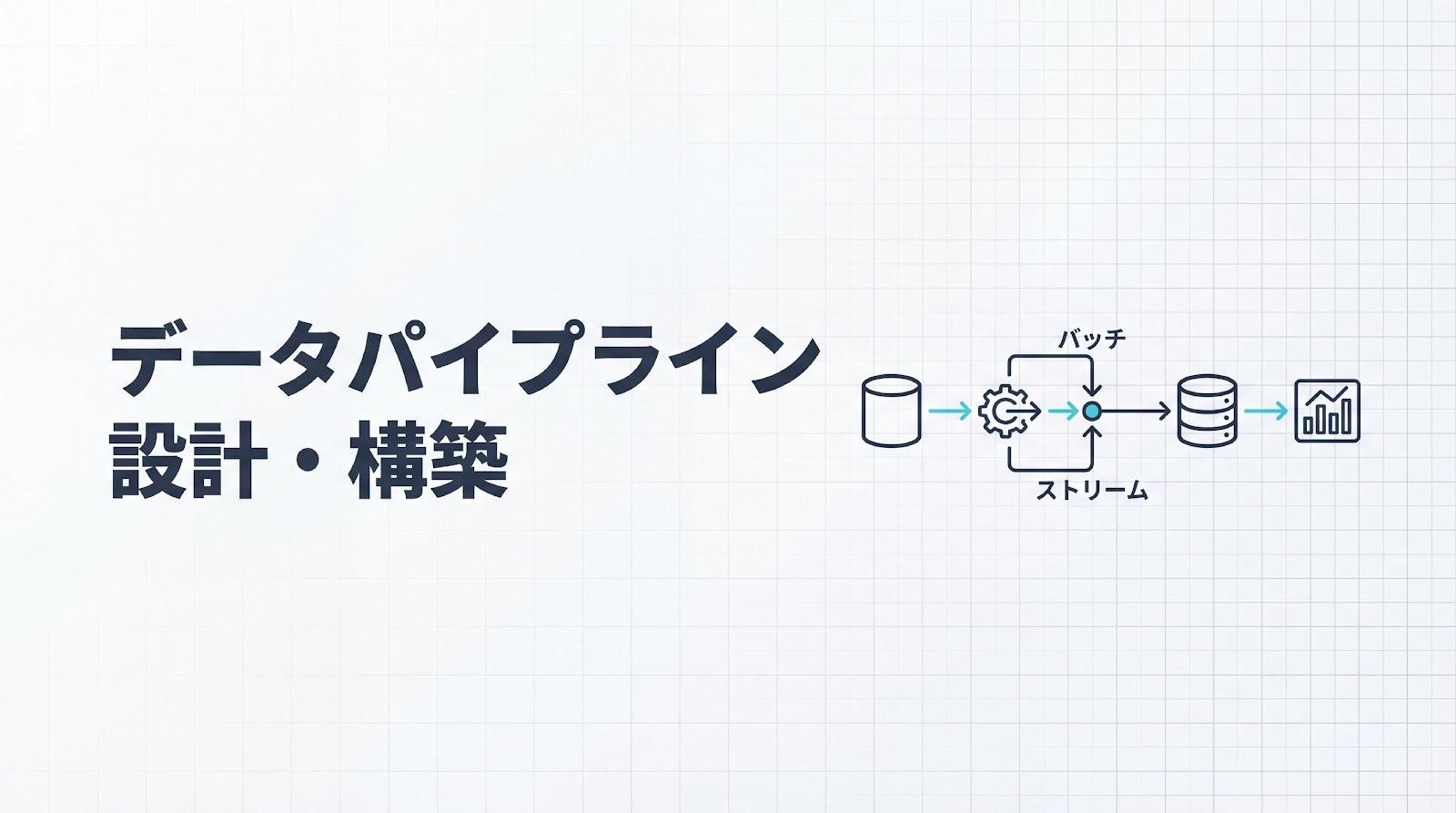
データパイプラインは、データソースから目的地まで自動的にデータを流し、処理する仕組みを指します。構築によって工数削減や意思決定の迅速化が期待できる一方、設計の複雑さや技術選定の難しさから、導入に踏み切れない企業も少なくありません。
本記事では、データパイプラインの基礎定義から、ETL・ELTとの違い、アーキテクチャ設計パターン、クラウドサービスやツールの選定基準、具体的な実装フロー、セキュリティ・運用保守の設計まで、体系的に解説します。さらに、国内外の先進企業の構築事例を通じて、実践的な示唆を提供します。
データパイプラインの構築は、データの自動処理と活用を実現する上で不可欠ですが、要件に応じた適切なアーキテクチャ選定が成功の鍵となります。
特にマーケティング目的での顧客データ統合をお考えの場合は、フルスクラッチだけでなくGENIEE CDPのような特化型基盤の活用も有力な選択肢です。
CDPツール比較15選!おすすめランキング・機能・選び方を徹底解説
データパイプラインとは?ETLとの違いと全体像
データパイプラインは、ソースから目的地までデータを自動的に流し、処理する一連の仕組みを指します。この章では、基本定義とETL・ELTとの違いを明確にし、5つのレイヤーからなる全体像を提示します。
データパイプラインの定義と基本概念
データパイプラインとは、データがシステム間を自動で移動・加工される仕組みを指します。蛇口から水が流れるように、データが連続的に処理される様子に例えられることがあります。単なるデータ移動だけでなく、分析可能な状態へ整えるプロセス全体を含む点が重要です。
手動でのデータ抽出・加工業務を排除し、定期的または即座にデータを取り込み、変換し、保存する自動化が核心です。これにより、人的ミスの削減や処理速度の向上が実現します。データパイプラインは、現代のデータ駆動型経営を支える基盤技術として位置付けられています。
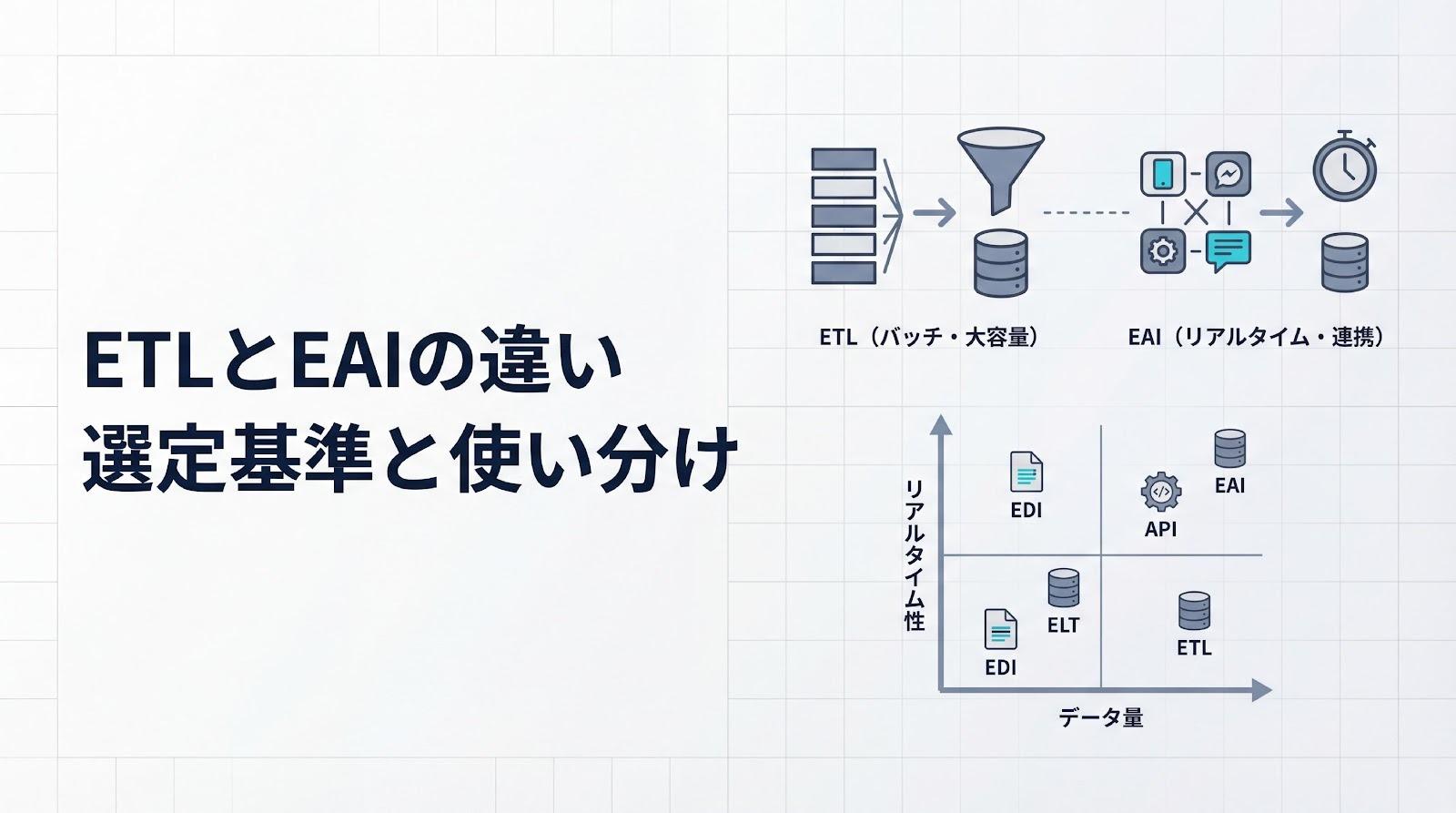
ETL・ELTとの違いを理解する
ETL(Extract, Transform, Load)は、データ抽出・変換・ロードの3段階を指し、変換をロード前に行う点が特徴です。一方、ELT(Extract, Load, Transform)は、ロード後に変換を行います。データウェアハウスやデータレイクの性能向上により、ELTの採用が増えています。
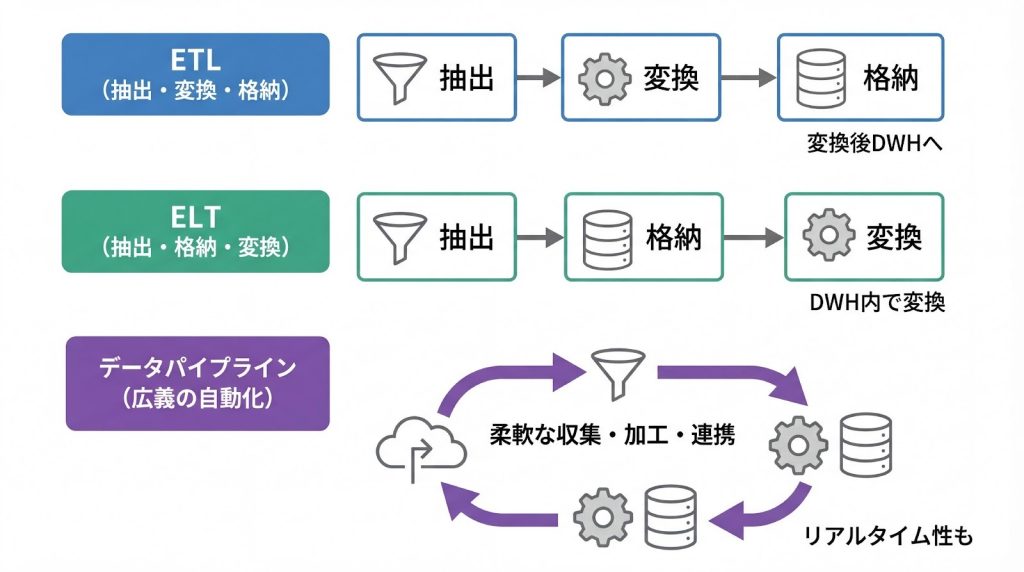
データパイプラインは、ETLやELTを含む広義の概念です。リアルタイム処理や単純なデータ移動も含まれるため、ETLよりも柔軟で幅広い用途に対応できます。ETLは変換に重点を置く一方、データパイプラインは処理の自動化と連続性を重視します。
データパイプラインの全体像:5つのレイヤー
データパイプラインは、次の5つのレイヤーで構成されます。
1. ソース(Source)
データベース、SaaS、ログファイル、IoTセンサーなど、データの発生源を指します。複数の異なるソースからデータを取り込むことが一般的です。
2. インジェスチョン(Ingestion)
ソースからデータを取り込む段階です。API、CDC(変更データキャプチャ)、ファイル転送など、ソースに応じた手法を選択します。
3. プロセッシング(Processing)
取り込んだデータをクレンジング、変換、集計します。欠損値の補完やデータ型の統一など、品質を担保する工程です。
4. ストレージ(Storage)
加工後のデータを保存します。データウェアハウス(DWH)やデータレイクなど、用途に応じた保存先を選択します。
5. アナリティクス(Analytics)
保存されたデータをBIツールや機械学習モデルで分析し、ビジネス価値を生み出します。可視化やレポート生成がこの層で行われます。
取り込みから分析までを5レイヤーに分離することで、各工程の最適化と保守性の向上が可能になります。レイヤーごとに技術やツールを選定し、全体として一貫したデータフローを実現します。
データパイプライン構築で得られる3つのメリット
データパイプラインの構築により、次の3つのメリットが得られます。
1. 工数削減
手動でのデータ抽出・加工作業を自動化することで、エンジニアやアナリストの作業時間を大幅に削減できます。定期的なレポート作成や集計業務が不要になり、より高度な分析業務に集中できます。
2. 迅速な意思決定
リアルタイムまたは準リアルタイムでデータが更新されるため、最新の情報に基づいた意思決定が可能になります。市場の変化や顧客行動の変化に素早く対応できます。
3. 品質向上
自動化されたバリデーションやクレンジング処理により、データの一貫性と正確性が向上します。人的ミスが減り、分析結果の信頼性が高まります。
特に顧客データの統合と活用が主な目的であれば、フルスクラッチでの構築以外に、GENIEE CDPのような特化型プラットフォームの活用が有力な選択肢となります。専門知識がなくてもAIが分析をサポートし、構築期間を大幅に短縮できるため、ビジネススピードを重視する企業に最適です。
データパイプラインの設計・構築例
データの鮮度要件や処理量に応じて、バッチ処理、ストリーム処理、ハイブリッド型など、適切な設計パターンを選択する必要があります。
この章では、主要な設計パターンを比較し、スケーラビリティと保守性を両立させるためのデータレイクとDWHの使い分け基準を提示します。
バッチ処理型パイプライン
バッチ処理型パイプラインは、一定期間ごとにデータを一括で処理する方式です。夜間バッチに代表される定期的な処理が典型例で、リアルタイム性が不要な大規模データの効率的な処理に適しています。
大量データを一括処理するためコスト効率が高く、Apache Airflowなどのスケジューラで管理するのが一般的です。データウェアハウスへの定期的なロードや、月次レポートの作成など、時間的余裕がある用途に向いています。処理の失敗時には再実行が容易で、運用負荷も比較的低く抑えられます。
ストリーム処理型パイプライン
ストリーム処理型パイプラインは、発生したデータを即座に処理するリアルタイム型の設計です。不正検知、パーソナライゼーション、リアルタイムダッシュボードなど、即時性が求められるユースケースに適しています。
Apache KafkaやApache Flinkを活用し、データの発生とほぼ同時に分析・アクションへ繋げることが可能になります。ただし、バッチ処理に比べて運用が複雑で、障害時の対応やデータの整合性確保に注意が必要です。コスト面でも、常時稼働するリソースが必要なため、バッチ処理よりも高くなる傾向があります。
ハイブリッド型パイプライン(Lambda/Kappa アーキテクチャ)
ハイブリッド型は、バッチとストリームを組み合わせた高度な設計です。LambdaアーキテクチャとKappaアーキテクチャが代表的です。
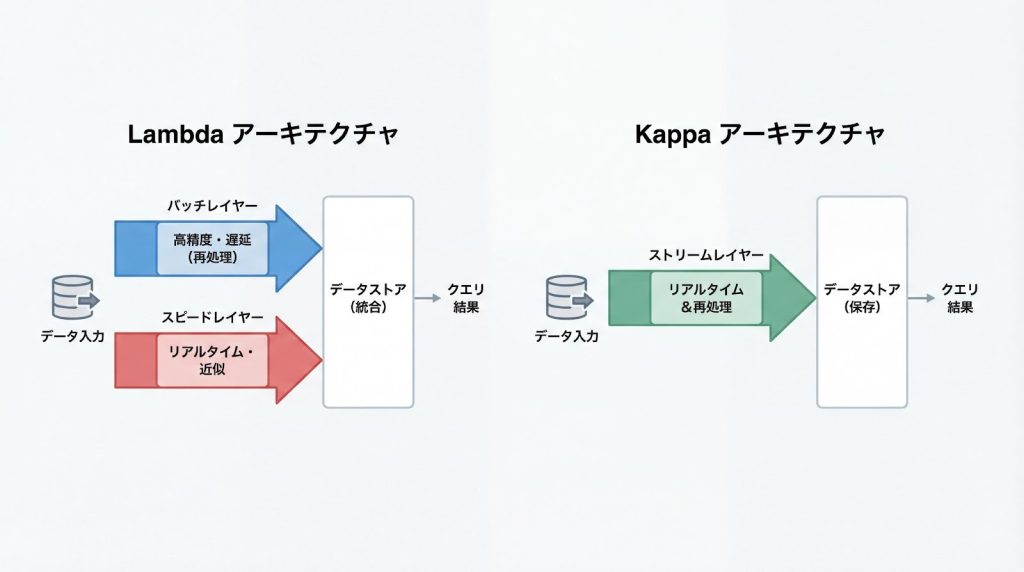
Lambda アーキテクチャ
バッチレイヤーとスピードレイヤーを並行稼働させ、バッチで正確な分析を行いつつ、ストリームで即時性を確保します。堅牢性が高い一方、2つのレイヤーを管理する複雑さがあります。
Kappa アーキテクチャ
ストリーム処理のみで構成し、過去データの再処理もストリーム基盤で行います。シンプルな設計で運用負荷が低い一方、ストリーム処理の複雑さを許容する必要があります。
過去データの再処理とリアルタイム性の両立が必要な場合、これらの高度なアーキテクチャが採用されます。要件に応じて、適切なパターンを選択することが重要です。
マイクロサービス対応パイプライン設計
マイクロサービスアーキテクチャでは、各サービスが独立してデータを管理する疎結合な設計が求められます。CDC(変更データキャプチャ)を用いて、データベースの変更をリアルタイムに捉え、他のサービスへ伝播させる手法が一般的です。
サービス間の依存を排除した設計により、システム全体の拡張性と開発の俊敏性を高めることができます。各サービスが独自のデータストアを持ち、イベント駆動でデータを連携させることで、障害の影響範囲を限定し、スケーラビリティを確保します。
データパイプラインのクラウドサービスと選定基準
AWS、GCP、Azureなどの主要クラウドサービスやOSS、SaaSの特性を比較し、自社開発の工数とビジネススピードの観点から最適なツールを選ぶための評価軸を提示します。既存の技術スタックとの親和性や、GUI/コードベースといった運用スタイルを軸に選定を行います。
主要クラウドサービス3つの比較
AWS、Azure、Google Cloudは、それぞれマネージドなデータパイプラインサービスを提供しています。各クラウドのエコシステム内での強みを理解し、自社の技術スタックに合わせて選択することが重要です。
1. AWS Glue
AWS Glueは、サーバーレスETLサービスとして、データカタログ機能を通じたAWS環境との高い親和性を持ちます。PySparkベースで柔軟なデータ変換が可能で、S3やRedshiftなどのAWSサービスとシームレスに連携します。
2. Azure Data Factory
Azure Data Factoryは、GUIベースでパイプラインを構築できるマネージドサービスです。Azure環境との統合が強く、オンプレミスとクラウドのハイブリッド構成に対応します。
3. Google Cloud Data Fusion
Cloud Data Fusionは、コード不要のGUIを提供し、豊富なコネクタで容易にパイプラインを構築できます。CDAPというオープンソースフレームワークをベースにしており、ベンダーロックインを避けやすい点が特徴です。
ELT特化型SaaSとエンタープライズETLツール
FivetranやStitch Dataなどのコネクタが豊富なELT特化型SaaSは、メンテナンス負荷の軽減に優れています。コネクタ開発の工数を削減したい場合は、自動化に特化したELT型SaaSの採用が効率的です。
一方、Informatica PowerCenterやTalendなどのエンタープライズETLツールは、高度な変換機能やデータ品質管理機能を備えています。複雑なビジネスロジックを実装する必要がある場合や、既存システムとの統合が求められる場合に適しています。
OSSツールの活用(Airflow・Kafka・Spark)
Apache Airflow、Apache Kafka、Apache Sparkは、カスタマイズ性の高いOSSとして広く採用されています。ワークフロー管理のAirflow、ストリーム基盤のKafka、高速処理のSparkという定番の組み合わせが一般的です。
OSSは高度な要件に対応できる一方、サーバー管理やバージョンアップ等の運用コストを考慮する必要があります。自社でインフラを管理できるエンジニアリング体制がある場合や、特定のカスタマイズが必要な場合に有効です。
ツール選定の6つの比較軸
ツール選定では、次の6つの軸で評価することが重要です。
1. コネクタ数
接続したいデータソースに対応しているか、コネクタの数と品質を確認します。
2. 開発手法
GUI中心か、コードベースか、自社のエンジニアのスキルセットに合わせて選択します。
3. 課金体系
データ量ベース、処理時間ベース、固定料金など、コスト構造を理解します。
4. 用途
バッチ処理、ストリーム処理、両対応か、自社の要件に合致するかを確認します。
5. 連携性
既存のBI・分析ツールやマーケティングツールとの連携のしやすさを評価します。
6. 拡張性
将来的なデータ量増加やユースケース拡大に対応できるスケーラビリティを確認します。
構築スピードを最優先し、マーケティングツールとの連携を重視するなら、GENIEE CDPのような特化型基盤が適しています。汎用的なクラウドサービスと比較して、標準コネクタによるノーコード連携が可能なため、開発・運用コストを抑えつつ、即座にデータ活用を開始できます。
データパイプライン構築の流れ
要件定義からテストまで、具体的な構築プロセスを7つのステップで解説します。全体設計を最初に行いつつ、実装は最小限のデータソースから段階的に拡張するスモールスタートの進め方を提示します。
ステップ1:要件定義とデータソースの洗い出し
「どのデータを・どこから・どこへ・どの頻度で」という基本要件を整理します。ビジネス上の目的を明確にし、優先順位を決定するプロセスが重要です。
対象データの特定と保存先の選定を事前に行うことで、後の設計手戻りを最小限に抑えられます。関係者へのヒアリングを通じて、必要なデータ項目や更新頻度、データ品質の要求水準を明確にします。
ステップ2:データモデルとスキーマ設計
分析に適した非正規化やスタースキーマの考え方を取り入れます。ディメンション(次元)とファクト(事実)を定義し、クエリの高速化を意識した設計を行います。
分析用途では、結合処理を減らすための非正規化やスタースキーマの採用が一般的です。トランザクションデータベースとは異なり、読み取り性能を優先した設計が求められます。
ステップ3:データ取り込み(インジェスチョン)の実装
API、CDC、ファイル転送など、データソースに合わせた最適な取り込み手法を選択します。リアルタイム性とシステム負荷のバランスを考慮した実装が必要です。
DBの変更をリアルタイムに捉えるCDCは、ソース負荷を抑えつつ鮮度の高いデータ取得を可能にします。バッチ処理に比べて複雑ですが、即時性が求められる場合に有効です。
ステップ4:データ変換(プロセッシング)の実装
クレンジング、集計、結合といった加工プロセスを実装します。データ品質を担保するためのバリデーション手法も重要です。
欠損値処理やデータ型変換をこの段階で徹底することで、後続の分析精度を担保できます。異常値の検出やビジネスルールに基づくデータ整合性チェックも含まれます。
ステップ5〜7:保存・ワークフロー管理・テスト
DWHへのロード、依存関係を定義したスケジューリング、異常検知テストを実施します。エラー発生時の通知やリトライ設計の重要性が高まります。
リトライ設定やログ監視を含むワークフロー管理が、パイプラインの安定稼働を支える基盤となります。テスト段階では、データの整合性、処理時間、エラーハンドリングの妥当性を確認します。
スモールスタートで段階的に構築する方法
最初から全データを対象にせず、価値の出やすい特定領域から始めるMVP(Minimum Viable Product)の考え方が有効です。早期に成功体験を作り、組織的な理解を得るための進め方を提案します。
単一のデータソースから分析を始めることで、構築コストを抑えつつ迅速にビジネス価値を検証できます。初期段階で得られた知見を基に、段階的にデータソースや処理を拡張していきます。
データパイプライン設計におけるセキュリティ・信頼性・運用保守の設計
本番運用に不可欠なセキュリティ対策、データガバナンス、耐障害性設計を網羅します。構築だけでなく、データの機密性保持と障害時の自動復旧を設計段階から組み込むことが重要です。監視メトリクスの設定やコスト最適化など、持続可能なパイプライン運用のための指針を示します。
通信プロトコルとセキュリティ対策
TLS暗号化やVPN接続、IAMによるアクセス制御の重要性を理解します。外部からの不正アクセスや内部不正を防ぐための技術的・組織的対策が必要です。
暗号化通信と厳格な認証・認可の設定は、データパイプラインにおけるセキュリティの最低要件です。データの機密性を保護するため、転送中・保存時の両方で暗号化を実施します。
データガバナンスとコンプライアンス対応
個人情報保護法やGDPRへの対応、データリネージ(Data Lineage:データの流れ・系譜の追跡))の可視化を実施します。法規制を遵守しつつ、データの流れ・系譜の追跡を可能にするための管理体制が求められます。
データの収集・保存・利用・廃棄の各段階で、適切な管理措置を講じることが重要です。データカタログやメタデータ管理ツールを活用し、データの所在や利用状況を可視化します。
エラーハンドリングと耐障害性の設計
リトライ、デッドレターキュー、冪等性の確保など、障害に強いパイプラインの作り方を実践します。一時的なエラーでシステム全体を止めないための工夫が必要です。
同じ処理を繰り返しても結果が変わらない「冪等性」を確保することで、障害復旧が容易になります。エラー発生時には、失敗したデータを別キューに移し、後で再処理できる仕組みを設けます。
データオブザーバビリティと品質監視
データの鮮度や正確性を監視するメトリクスを設定します。異常値を検知してアラートを飛ばす仕組みにより、サイレントなデータ劣化を防ぎます。
完全性や適時性などの品質指標を常時監視することで、分析結果の信頼性を維持し続けることができます。データ量の急激な変化や、期待値から外れた値の出現を自動検知します。
運用保守コストの最適化
マネージドサービスの活用や自動スケーリングによるコスト削減手法を検討します。過剰なリソース消費を防ぐためのコスト監視と予算管理が重要です。
クラウドのマネージドサービスを積極的に活用することで、開発および運用の人的コストを削減できます。自動スケーリングにより、処理量に応じたリソース調整を行い、無駄なコストを抑えます。
業界別!データパイプライン構築事例

大規模ストリーミングからマーケティング基盤の刷新まで、国内外の先進事例を紹介します。事例企業の多くは、リアルタイム処理への移行とマネージドサービスの活用でビジネス価値を高めています。成功企業の共通項を抽出し、自社への適用に向けた示唆をまとめます。
株式会社サイバーエージェント(メディア・インターネット広告・ゲーム)
サイバーエージェント様の事例では、大規模なデータ処理基盤で利用していたHBaseが老朽化し、HadoopエコシステムやZooKeeperへの依存性が高く、設定やチューニングが複雑で運用負荷が高いという課題を抱えていました。また、障害発生時のダウンタイムが長い点も問題でした。
解決策として、老朽化したデータ処理基盤を刷新し、HBaseで運用していた部分をオープンソースのNewSQLデータベース「TiDB」に移行しました。BI基盤においては、Tableau Serverの環境をコンテナ化し、リソースを柔軟に拡張できる体制を構築しました。クラウドDWHにライブ接続しつつ、Tableauのインメモリデータベース「Hyper」を活用することで、ユーザーの待ち時間を限りなくゼロにする分析体験を目指しました。
成果として、TiDBへの移行により、MySQL互換のため学習コストを抑えつつ、アプリケーション開発者が本来の機能実装に専念できる環境を実現しました。BI基盤のコンテナ化により、従来は数日かかっていた障害対応やバージョンアップが数分で可能になり、運用効率が飛躍的に向上しました。
参照元:https://pingcap.co.jp/case-study/cyberagent/
データパイプラインとは?まとめ
データパイプラインは、データソースから目的地まで自動的にデータを流し、処理する仕組みであり、現代のデータ駆動型経営を支える基盤技術です。
構築にあたっては、要件定義とデータソースの洗い出しから始め、データモデルとスキーマ設計、データ取り込み、データ変換、保存、ワークフロー管理、テストという7つのステップを踏むことが重要です。
また、最初から全データを対象にせず、価値の出やすい特定領域から始めるスモールスタートの考え方が、構築コストを抑えつつ迅速にビジネス価値を検証する鍵となります。
もし、社内にデータエンジニアリングの専門家が不在で、顧客データの統合と活用にお困りの場合は、GENIEE CDPの導入をご検討ください。AIを活用した分析基盤により、AX(AIトランスフォーメーション)を加速させることが可能です。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。