







ETLとは?Extract・Transform・Loadの意味からツール選定まで解説

「ETLという言葉は聞いたことがあるが、正確に説明できない」データ活用プロジェクトに関わり始めたとき、こうした状況に置かれる方は少なくありません。社内の複数システムに散在するデータをDWHやBIツールに集約する案件を担当することになり、ETLツールの導入を検討しなければならない場面は、DX推進が加速する現在、多くの企業で生じています。
ETLとは、Extract(抽出)・Transform(変換)・Load(ロード):データを書き込む工程の頭文字を取ったデータ統合プロセスの総称です。業務システムからデータを取り出し、分析に適した形に整えてDWHへ書き込む一連の処理を指します。このプロセスの品質が、BIツールで行う分析の精度を左右します。
ETLを理解するうえで押さえておきたいのは、定義だけでなく「ELTやEAIとどう違うのか」「ツールを使うべき状況はどこか」「選定時に何を見ればよいか」という実務的な判断軸です。用語の意味を知るだけでは、ツール選定や社内提案の場面で判断に詰まることがあります。
この記事では、ETLの各プロセスの役割から、ELT・EAIとの使い分け、ツール導入のメリット、選定基準まで順に整理します。
ETLとは何か:Extract・Transform・Loadの意味と役割
ETLは、複数の業務システムに散在するデータを一箇所に集約し、分析に使える状態にするための中間処理プロセスです。「業務システム群 → ETL → DWH → BIツール」というデータフローの中で、ETLはその中間を担います。
BIツールはDWH上のデータを参照するため、ETL処理の品質が低ければ、どれだけ優れたBIツールを使っても分析結果の信頼性は下がります。
各プロセスの役割は、Extract(データの取り出し)・Transform(データの整形・変換)・Load(DWHへの書き込み)の3段階に分かれており、それぞれに異なる技術的な考慮点があります。以下で順に見ていきます。
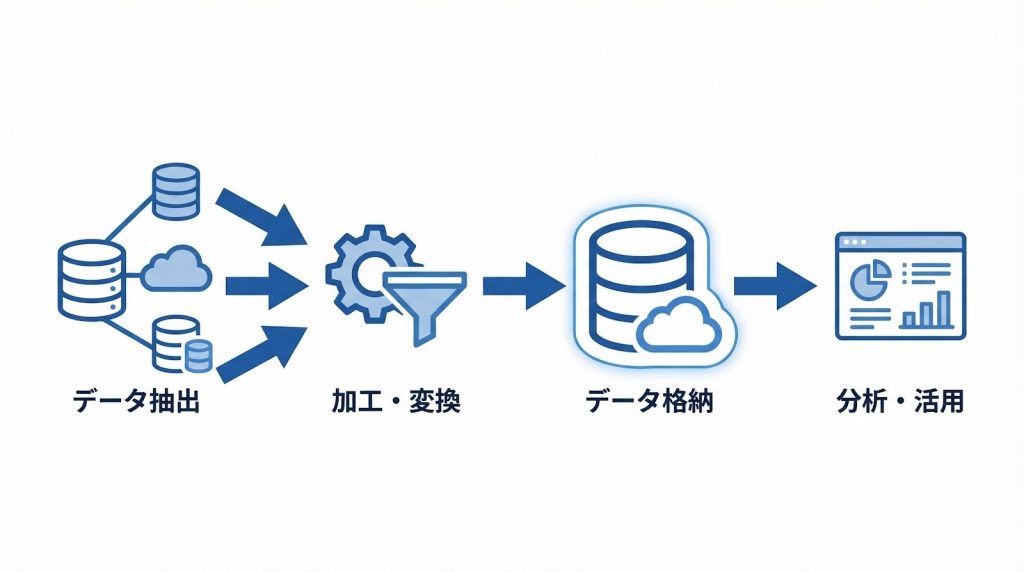
Extract(抽出):データを取り出す工程
Extractは、分析に必要なデータを各種データソースから取り出す工程です。抽出元となるシステムは、RDB(リレーショナルデータベース)・CSVファイル・REST API・SaaSアプリケーションなど多岐にわたり、連携先ごとに接続方式が異なります。複数のシステムを横断してデータを集める場合、それぞれの接続仕様に対応する必要があります。
抽出方式には大きく2種類あります。フル抽出はデータソースの全件を毎回取得する方式で、初期構築や小規模データに向いています。一方、差分抽出は前回の抽出以降に変更・追加されたデータのみを取得するため、大量データを扱う環境では処理負荷を大幅に抑えられます。日次・毎次でデータを更新する運用では、差分抽出が標準的な選択肢になります。
Transform(変換):データを整える工程
Transformは、抽出したデータを分析に適した形に整える工程で、ETLの3プロセスの中で最も処理の種類が多く、品質への影響が大きい段階です。
具体的な変換処理としては、次のようなものが挙げられます。
- クレンジング(欠損値・異常値の除去・補完)
- 重複排除
- コード変換(部門コードや商品コードの統一)
- テーブル結合(複数ソースのデータを紐付け)
- 集計・サマリー化
- 暗号化・マスキング(個人情報の保護)
なかでも対処が難しいのが、表記ゆれ・文字コードの差異・日付フォーマットの不整合です。たとえば、ある業務システムでは「株式会社〇〇」と登録されているデータが、別のシステムでは「(株)〇〇」と入力されているケースは珍しくありません。
こうした不整合をTransformで統一しておかなければ、DWH上で同一企業が別エンティティとして扱われ、集計結果に誤りが生じます。Transformを丁寧に設計することが、分析精度を保つ前提条件です。
Load(ロード):データを書き込む工程
Loadは、Transformで整えたデータを格納先に書き込む工程です。格納先は用途によって異なり、主に次の3種類が選ばれます。
- DWH(データウェアハウス):構造化データを蓄積し、BIツールからの分析クエリに応答する用途
- データレイク:構造化・非構造化を問わず生データを大量に保存し、後から柔軟に活用する用途
- データマート:特定の部門や分析目的に絞ったサブセットを提供する用途
ロード方式にも、フル抽出と同様に2種類あります。全件ロードは既存データを全て上書きまたは再投入する方式で、初期構築や小規模データに向いています。差分ロードは変更分のみを追記・更新するため、更新頻度が高い運用環境での処理効率化に有効です。
Loadが完了すると、BIツールはDWH上のデータを参照して分析・可視化を行います。Extract・Transform・Loadの3工程が正しく機能して初めて、BIツールが信頼できるデータを扱える状態になります。
ETL・ELT・EAIの違い:自社要件に合う方式の見極め方
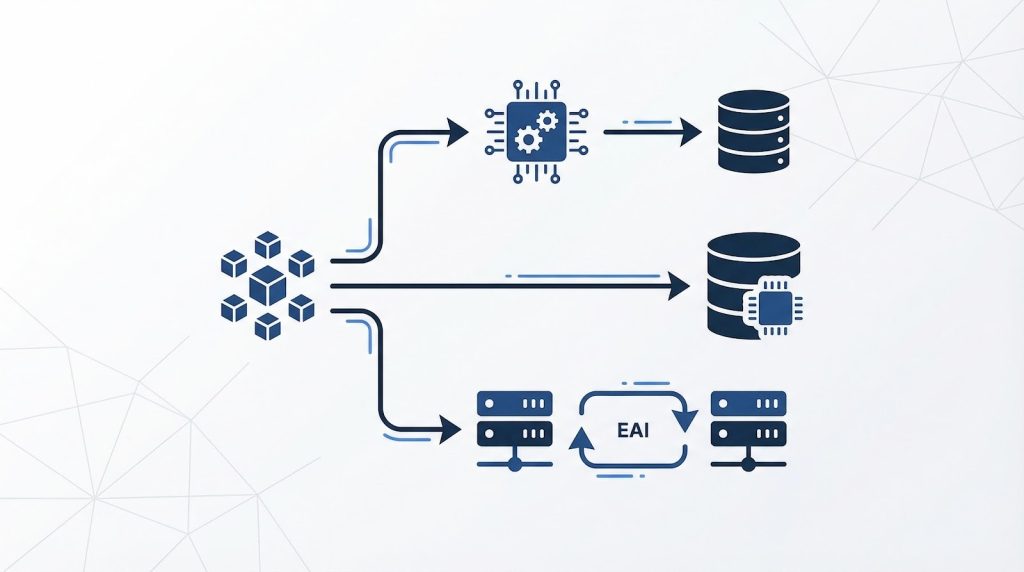
ETLと混同されやすい概念として、ELTとEAIがあります。3つは名称が似ていますが、処理の順序や目的が根本的に異なります。自社の要件に合わない方式を選ぶと、後から大きな手戻りが生じるため、違いを正確に把握しておくことが重要です。
判断の起点は「何のためにデータを動かすか」です。データ分析のためにDWHへ集約するならETL/ELT、業務システム間のリアルタイム連携が目的ならEAIという大きな分岐があります。ETLとELTの選択はその次の段階で、環境やデータ量によって決まります。
ETLとELT:処理順序と適した環境の違い
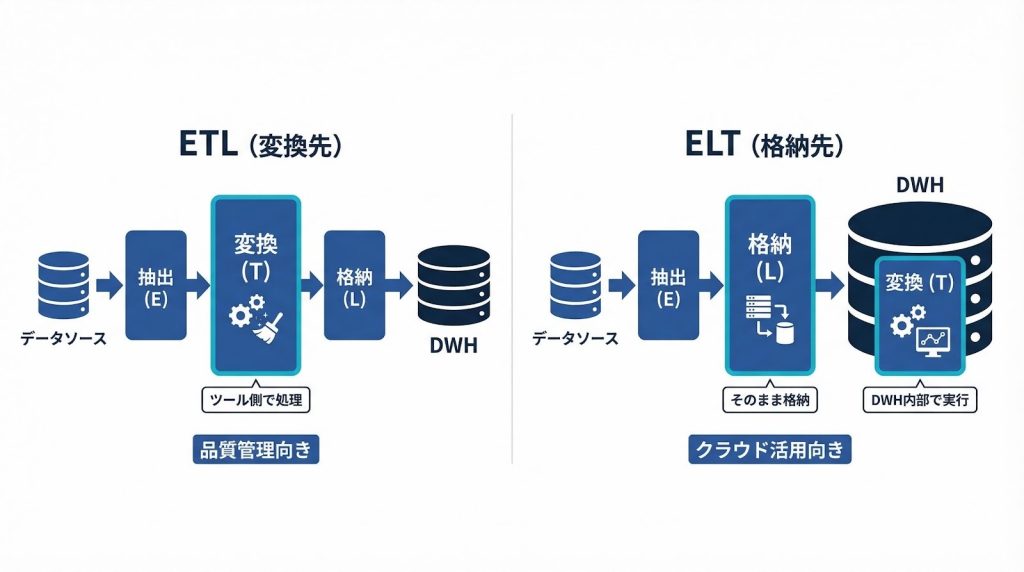
ETLとELTの最大の違いは、変換処理をどのタイミングで行うかです。
- ETL:変換(Transform)を先に行い、整えたデータをDWHに格納(Load)する
- ELT:生データをそのままDWHに格納(Load)し、DWH内で変換(Transform)する
ETLはDWHの外で変換を完了させるため、変換ロジックをETLツール側で一元管理できます。データ品質の厳密な制御が求められる場面や、オンプレミス環境でDWH側の処理能力に余裕がない場合に適しています。
ELTはSnowflakeやBigQueryのようなクラウドDWHが持つ大規模並列処理能力(MPPアーキテクチャ)を活用して変換を行います。生データをそのまま格納するため、変換前のデータを後から再利用できる柔軟性もあります。データ量が多く、クラウドDWHを活用できる環境ではELTが有利とされる傾向があります。
使い分けの目安としては、変換ロジックの管理を優先する環境ではETL、大量データの高速処理とクラウドDWHの活用を優先する環境ではELTが選ばれることが多いです。ただし、どちらが優れているという話ではなく、自社のインフラ環境と運用体制に照らして判断することが重要です。
ETLとEAI:データ集約とアプリ連携の違い
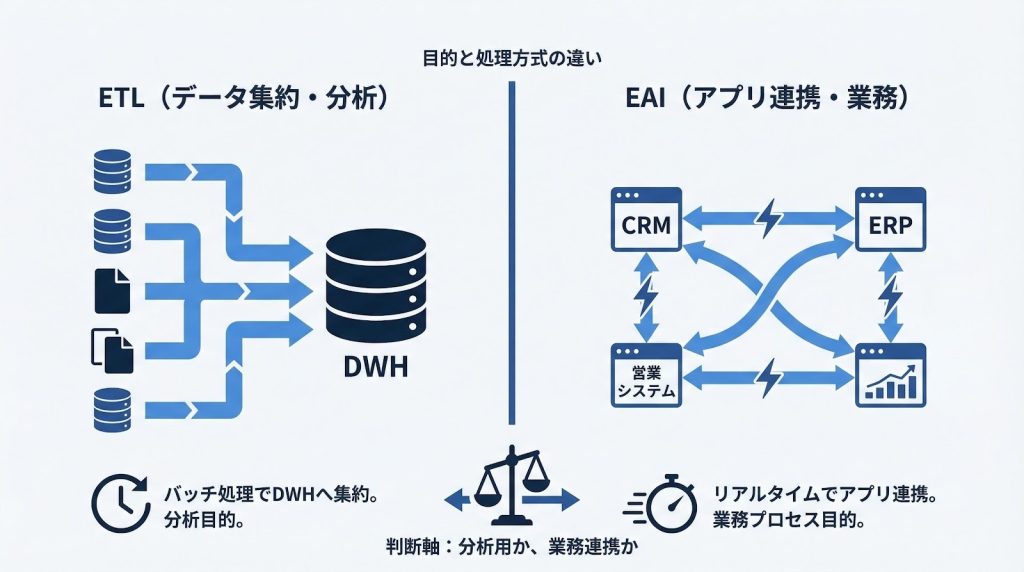
EAI(Enterprise Application Integration)は、アプリケーション間のリアルタイムなデータ連携を担うための仕組みです。ETL/ELTとは用途が根本的に異なります。
ETLはバッチ処理でDWHへデータを集約することを目的としています。夜間や定時に大量のデータをまとめて処理し、翌朝には分析用のデータが揃っている——という運用が典型的です。一方、EAIは受発注処理や在庫同期のように、業務システム間でリアルタイムにデータをやり取りする用途に使われます。
判断軸は明確です。「分析用のデータをDWHに集めたい」ならETL/ELT、「業務プロセスをリアルタイムで連携させたい」ならEAIです。両方の要件が存在する場合は、ETL/ELTとEAIを併用する構成も珍しくありません。
| 方式 | 処理タイミング | 主な用途 | 適した環境 |
| ETL | バッチ(定期) | DWHへのデータ集約・分析基盤構築 | オンプレミス・変換ロジック管理重視 |
| ELT | バッチ(定期) | 大量データのDWH格納・クラウド活用 | クラウドDWH環境・大規模データ処理 |
| EAI | リアルタイム | 業務システム間の即時連携 | オンプレミス環境・SaaS連携はiPaaSが後継 |
ETLツール導入のメリット:スクラッチ開発・手作業との比較
ETL処理の実装方法は、大きく「手作業」「スクラッチ開発(ハンドコーディング)」「ETLツール」の3つに分かれます。それぞれに特性があり、どれが適切かは自社の規模・体制・データ量によって変わります。
ただし、データ連携の規模が拡大し、複数システムが絡むようになると、手作業とスクラッチ開発には共通の限界が現れます。担当者への依存、ヒューマンエラーのリスク、仕様変更のたびに発生するコード修正。
これらが積み重なると、データ基盤の運用が特定の人物に依存した状態になります。ETLツールはこの課題に対して、開発・保守工数の削減、データ品質の標準化、属人化の防止という3つの面から改善をもたらします。
1. 開発・保守工数の削減
スクラッチ開発でETL処理を実装した場合、データソースの仕様変更や追加のたびにコードを修正する必要があります。変更が頻繁に発生する環境では、この保守作業が開発チームの工数を継続的に圧迫します。
ETLツールのGUIベースのビジュアル開発環境では、プログラミングスキルがなくてもETLフローを構築・変更できます。接続先の変更やカラムのマッピング修正も、画面上の操作で完結するため、エンジニアへの依頼待ちが発生しにくくなります。
また、スケジューリング・自動実行機能により、定時バッチ処理の起動や完了確認といった手動オペレーションを排除できます。夜間バッチの実行確認のために担当者が待機するような運用から脱却できる点は、特に少人数チームで効果が大きいです。
こうした工数削減の観点から、GENIEE CDPのようなCDPが選択肢として挙がることがあります。標準で多数のツールとノーコードで連携できるため、エンジニアリソースが限られた環境でも複数のデータソースを集約しやすく、接続設定の変更もGUI上で対応できます。
2. データ品質の標準化
手作業によるデータ統合では、担当者ごとに処理の手順や判断基準が異なりやすく、同じデータでも担当者によって結果が変わるリスクがあります。ETLツールを使うと、クレンジング・重複排除・コード変換などの変換ルールをツール上で一元管理できるため、複数の担当者が関与しても品質基準が統一されます。
表記ゆれや文字コードの差異、日付フォーマットの不整合といった処理も、ルールとして定義しておけば自動で適用されます。人が手動で確認・修正する工程が減ることで、ヒューマンエラーの発生頻度を下げられます。
さらに、エラーハンドリング機能により、異常データを自動で検知してアラートを送る仕組みを構築できます。問題が発生したときに「気づかないまま誤ったデータが分析に使われる」という状況を防ぐための安全網として機能します。
3. 属人化の防止と運用の継続性確保
スクラッチ開発で構築されたETL処理は、コードを書いた担当者以外が内容を把握しにくい状態になりがちです。担当者が異動・退職した際に「誰もそのコードを触れない」という状況は、データ基盤の運用において深刻なリスクです。
ETLツールでは、処理フローがGUI上で視覚的に表示されます。どのデータソースからどのような変換を経てどこに格納されるかが図として確認できるため、担当者が変わっても引き継ぎが容易になります。コードを読み解く作業が不要になる分、新担当者が運用を引き継ぐまでの時間も短縮されます。
ログ・監視機能も属人化防止に寄与します。処理の実行履歴・エラー内容・処理時間などがツール上に記録されるため、「あの処理が昨夜失敗した理由」を特定の担当者に聞かなくても確認できます。運用の継続性は、担当者個人の知識ではなくツールの仕組みで担保される状態が理想です。
ETLツールの選定ポイント:評価すべき機能要件と比較軸
ETLツールの選定で失敗しやすいのは、製品の機能比較から入ってしまうケースです。ツールの良し悪しは自社の要件との適合度で決まるため、まず「自社が何を必要としているか」を整理することが出発点になります。
確認すべき前提条件は、連携元・連携先のシステム数、扱うデータ量、運用に関わるメンバーのスキルセット、クラウド/オンプレミスの環境構成の4点です。これらが明確になって初めて、ツールの評価軸に優先順位をつけられます。
1. 接続性:対応データソースとコネクタの種類
ツール選定の最初の絞り込み基準は、自社の連携元・連携先システムに対応するコネクタが揃っているかどうかです。
どれだけ操作性が優れていても、接続したいシステムに対応していなければ導入の意味がありません。
自社で利用しているSaaSや基幹システムのリストを事前に作成し、候補ツールのコネクタ一覧と照合する作業が、選定の最初のステップとして有効です。特に国産SaaSや広告プラットフォームとの連携が多い環境では、対応コネクタの充実度が選定の優先基準になります。
この観点では、GENIEE CDPもSaaSや広告プラットフォームなど多様なデータソースへの対応を強みの一つとしており、国内環境での連携先を確認する際の比較対象として参考になります。
2. 開発・運用のしやすさ:GUIとノーコード対応
GUIベースのビジュアル開発に対応しているかどうかは、エンジニア以外が運用に関与できるかを左右する重要な評価軸です。データエンジニアが常駐しているチームであれば、コードベースのツールでも問題ありませんが、業務部門のメンバーが設定変更を行う可能性がある場合は、ノーコード/ローコード対応の有無を確認する必要があります。
運用支援機能の充実度も長期的なコストに影響します。具体的には次の機能が揃っているかを確認してください。
- スケジューリング(定時実行・依存関係の設定)
- ファイル監視(ファイル到着をトリガーにした自動実行)
- エラー通知(処理失敗時のアラートメール・Slack通知など)
- バージョン管理・変更履歴の追跡
これらの機能が不足していると、運用担当者が手動で補う作業が増え、結果として属人化が進みます。ツール選定の段階で「日常運用をどこまで自動化できるか」を具体的にイメージしながら評価することが重要です。
3. スケーラビリティとクラウド対応
現在のデータ量に合わせてツールを選んでも、事業成長に伴いデータ量が増加した場合にインフラを柔軟に拡張できるかどうかは、中長期の運用コストに直結します。
アーキテクチャの観点では、サーバーレス型とサーバー型で特性が異なります。AWS Glueに代表されるサーバーレス型は、インフラ管理が不要で従量課金のため小規模スタートに向いています。一方、サーバー型は大規模・固定負荷の環境でコスト予測がしやすいという特性があります。
オンプレミス環境が残っている場合は、ハイブリッド対応の可否も確認が必要です。クラウド移行を段階的に進める計画がある場合、移行途中の期間にオンプレミスとクラウドの両方に対応できるかどうかがツール選定の条件になります。
セキュリティ・データガバナンスの要件も、機能要件と並んで確認すべき重要項目です。個人情報を含むデータを扱う場合は、マスキング処理・アクセス制御・監査ログの取得機能が備わっているかを選定段階で確認してください。後から気づいても、ツールの変更は容易ではありません。
まとめ
この記事では、ETL(Extract・Transform・Load)の各プロセスの役割から、ELT・EAIとの違い、ツール導入のメリット、選定基準までを整理しました。
手作業の限界・属人化・複数システム連携の複雑化が顕在化しているなら、それはETLツールの導入を検討するサインです。ツール選定を進める際は、まず連携先システムのリストアップとデータ量の把握から着手し、その後に製品比較・PoCへと進むのが効率的です。要件が曖昧なまま製品デモを見ても、判断の根拠が定まりません。
なお、データ統合の課題を解決する選択肢は、従来型のETLツールだけにとどまりません。GENIEE CDPのように、ノーコードで多数のデータソースと連携しながら、統合後の分析・可視化・マーケティング施策への活用まで一体で対応できるCDPも、要件次第では検討に値する選択肢です。
特に2025年10月以降は「AI Data Hub」機能として、非構造化データのRAG Ready ETL処理や生成AI向けデータ整備基盤も提供しており、データ統合からAI活用までをワンストップで実現したい場合に有効です。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。













