Zero ETLとは?AWSでの設定手順と従来ETLとの使い分けを解説
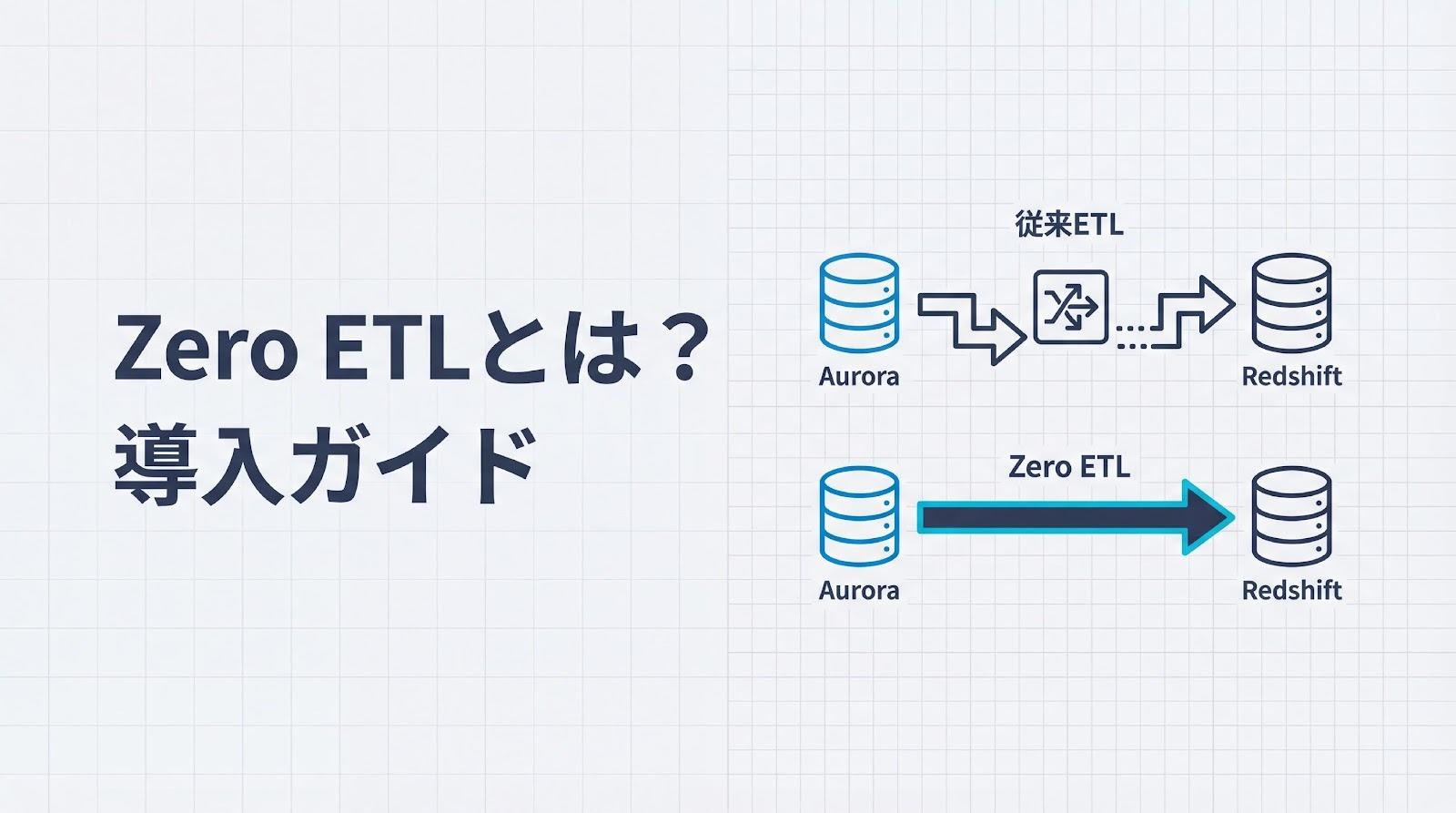
Zero ETLは、データソースから分析基盤へパイプライン構築なしでデータを連携する技術として注目を集めています。従来のETLジョブでは、Glueなどを用いたパイプラインの構築・保守に多くの工数がかかり、スキーマ変更のたびに停止や修正が必要でした。
Zero ETLを導入することで、こうした運用負荷を大幅に削減し、数秒から数分でのニアリアルタイム同期を実現できます。一方で、対応リージョンやエンジンバージョンなどの前提条件があり、複雑なデータ変換には対応できないという技術的制約も存在します。
本記事では、Zero ETLの仕組みと従来ETLとの違いを明確にし、AWSにおける利用可能条件、Aurora→Redshift統合の具体的な設定手順、運用負荷・コスト削減効果の定量評価、Zero ETLで対応できないケースと使い分け基準を順に解説します。
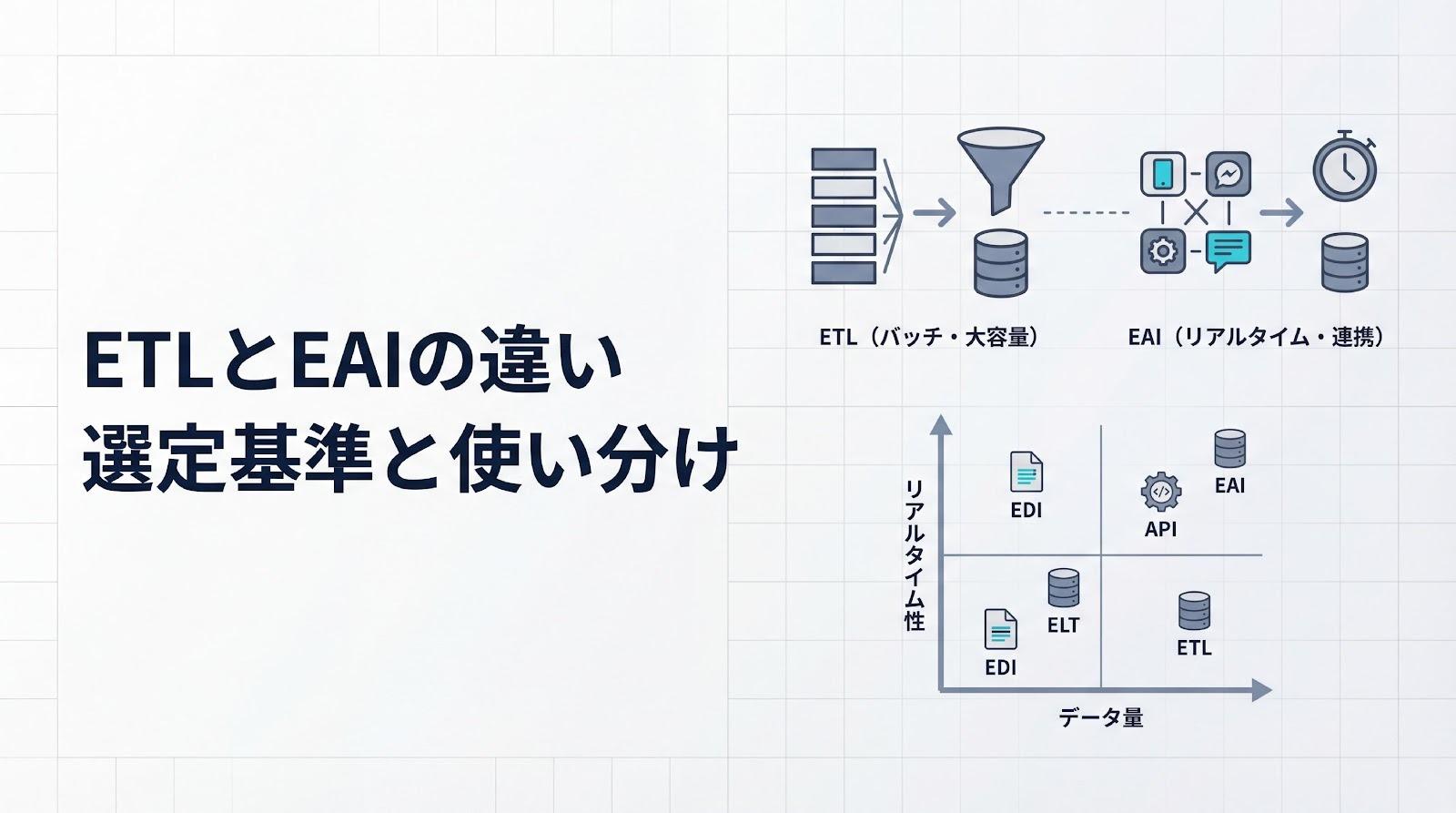
Zero ETLの仕組みと従来ETLとの決定的な違い
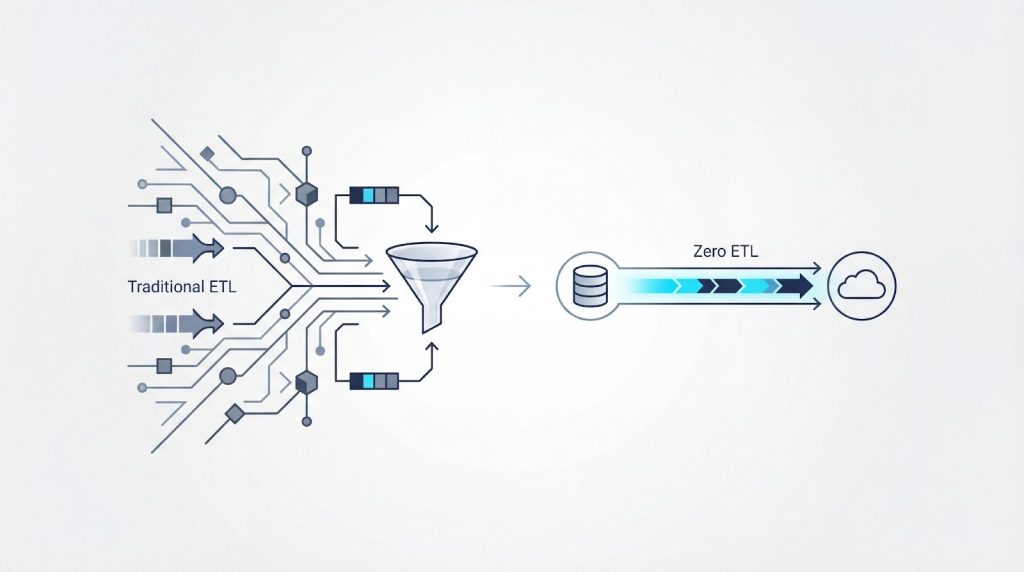
Zero ETLは、データソースから分析基盤へ直接データを統合し、従来のETLパイプライン構築を不要にする技術です。この章では、従来のETLプロセスが抱える3つの課題と、CDCベースの同期メカニズムがもたらす運用上のメリットを見ていきます。
従来のETLプロセスが抱える3つの課題
従来のETLプロセスには、パイプラインの保守工数、データ遅延、スキーマ変更への脆弱性という3つの主要課題があります。
特にデータエンジニアリングの専門スキルを持つ人材が不足する日本企業においては、これらの課題が深刻な運用リスクとなっています。
1. パイプラインの保守工数負担
ETLジョブは、データソースの追加やスキーマ変更のたびにコードの修正とテストが必要です。Glueジョブのスクリプトを更新し、エラー監視とリトライ処理を設定し、ログを確認する作業が継続的に発生します。
データエンジニアはパイプラインのメンテナンスに多くの時間を費やし、より高度な分析業務に注力できない状況が生まれています。
2. バッチ処理による遅延
従来のバッチ処理では、数時間から半日以上のデータ遅延が発生することがあります。夜間バッチでデータを転送する構成では、前日の業務データが翌朝まで分析基盤に反映されず、リアルタイムな意思決定の妨げとなります。
市場の急激な変化に対応するためには、より短いサイクルでのデータ更新が求められます。
3. スキーマ変更への脆弱性
ソース側のテーブルにカラムが追加されたり、データ型が変更されたりすると、ETLパイプラインが停止します。復旧には、スクリプトの修正、テスト環境での検証、本番環境へのデプロイという一連の作業が必要です。この間、データの同期が止まり、分析業務に影響が出ることもあります。
なお、ETLの運用負荷を下げることが目的であれば、インフラ層のZero ETLだけでなく、顧客データの統合・活用に特化したGENIEE CDPのようなプラットフォームを利用することも、データエンジニアの工数削減における有効な選択肢の一つです。
Zero ETLが可能とする、遅延の少ない統合アプローチ
Zero ETLは、CDC(Change Data Capture)技術を用いてトランザクションログを監視し、変更を即座に反映します。データベースのログを直接参照するため、ソース側の負荷を抑えつつ、ニア・リアルタイムな同期を実現できます。
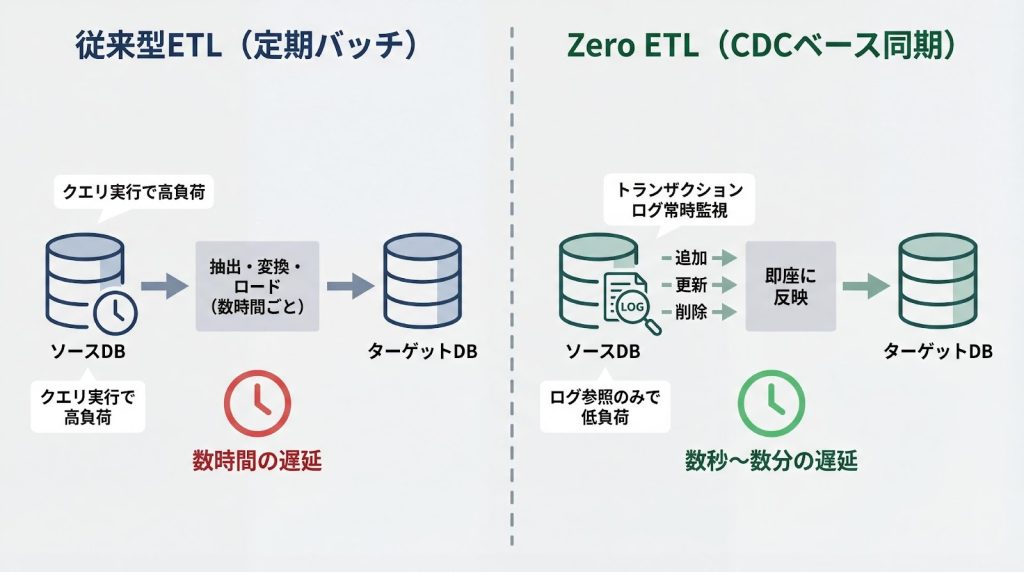
1. トランザクションログの監視
AuroraのバイナリログやPostgreSQLのWAL(Write-Ahead Log)を監視し、INSERT、UPDATE、DELETEなどの変更イベントを検知します。ログはデータベースが通常の運用で生成するものであり、追加のクエリ実行によるパフォーマンス低下を避けられます。
2. ニアリアルタイムなデータ反映
変更イベントは数秒から数分でターゲット側に伝播されます。従来のバッチ処理と比較して、データの鮮度が大幅に向上し、最新の業務状況に基づいた分析が可能になります。
3. スキーマ変更の自動追従
ソース側でカラムが追加された場合、Zero ETLは変更を自動検知してターゲット側に反映します。これにより、パイプライン停止のリスクが軽減され、運用の継続性が保たれます。ただし、データ型の変更など一部の変更は手動対応が必要となる場合があります。
AWSにおけるZero ETLの利用条件
Zero ETL統合を導入する前に、対応リージョン、エンジンバージョン、インスタンスクラスなどの前提条件を確認する必要があります。
この章では、利用可能条件の確認方法、データ変換の技術的制約と回避策、IAMロール・暗号化・ネットワーク設定の前提条件を順に見ていきます。
対応リージョン・エンジン・インスタンスクラスの確認方法
Zero ETL統合は、すべてのAWSリージョンやAuroraのバージョンで利用できるわけではありません。導入を検討する際は、まず自社環境が要件を満たしているかを確認することが重要です。
1. 対応リージョンの確認
Zero ETL統合は、東京リージョン(ap-northeast-1)をはじめとする主要リージョンで利用可能です。AWSの公式ドキュメントで最新の対応状況を確認し、自社のデータソースとターゲットが同じリージョン内にあるかを確認してください。
2. Auroraエンジンバージョンの確認
Aurora MySQLおよびAurora PostgreSQLの特定バージョン以降でZero ETL統合がサポートされています。RDSコンソールの「Zero-ETL統合」タブから、現在のクラスターが要件を満たしているかを確認できます。バージョンが古い場合は、アップグレードを検討する必要があります。
3. インスタンスクラスの確認
一部のインスタンスクラスではZero ETL統合が利用できません。特に古い世代のインスタンスや、小規模なインスタンスでは対応していない場合があります。対応状況はAWSの公式ドキュメントで確認し、必要に応じてインスタンスクラスの変更を計画してください。
データ変換・フィルタリングの技術的制約と回避策
Zero ETL統合は、テーブル単位の同期が基本であり、JOINや集計などの複雑な変換処理を同期プロセス内では実行できません。複雑なクレンジングが必要な場合は、Redshiftに取り込んだ後にELT形式で変換を行う構成が推奨されます。
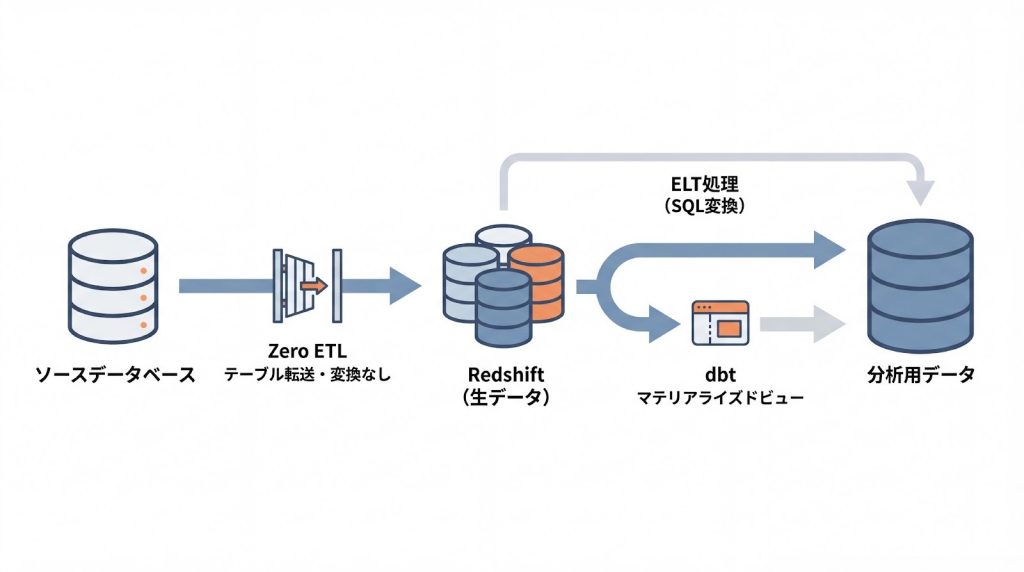
1. 同期プロセスで実行できない処理
Zero ETL統合では、複数テーブルの結合、カラムの加工、条件に基づくフィルタリングなどの処理は行えません。ソース側のデータがそのままターゲット側に反映されるため、事前の変換が必要な場合は別の手段を検討する必要があります。
2. Redshift側での後処理
Zero ETLで生データを取り込み、Redshift側でSQLベースの変換を行うことで管理を簡素化できます。マテリアライズドビューを活用して集計処理を定期的に実行し、分析用のテーブルを作成する方法が一般的です。
3. dbtを用いた変換管理
dbt(data build tool)を使用することで、Redshift内でのSQL変換をコード管理し、テスト・デプロイのワークフローを整備できます。これにより、ELTアーキテクチャへの転換がスムーズに進みます。
IAMロール・暗号化・ネットワーク設定の前提条件
Zero ETL統合を正常に動作させるには、AuroraからRedshiftへの書き込み権限を持つIAMロールの構成、KMSキーの共有、VPC間の疎通確認が必要です。
1. IAMロールの構成
AuroraからRedshiftへデータを書き込むためのIAMロールを作成し、Auroraクラスターにアタッチします。ロールには、Redshiftへのデータ書き込み権限と、必要に応じてS3バケットへのアクセス権限を付与してください。
2. KMS暗号化キーの共有
AuroraとRedshiftが異なるKMSキーで暗号化されている場合、データの転送時に復号化・再暗号化が必要です。同じKMSキーを使用するか、キーポリシーでクロスアカウント・クロスリージョンのアクセスを許可する設定を行ってください。
3. ネットワーク設定とセキュリティグループ
Redshift側でAuroraクラスターからのインバウンド通信を許可するセキュリティグループ設定が必要です。VPCピアリングやTransit Gatewayを使用して、異なるVPC間での通信を確立する場合もあります。
Zero ETL導入による運用負荷・コスト削減効果
Zero ETL統合の導入により、ETLジョブの構築・管理工数が削減され、データエンジニアはより高度な分析業務に注力できるようになります。
この章では、従来ETLの運用コスト試算、Zero ETL利用料とROIの試算、業種別の導入効果事例を見ていきます。
従来ETLパイプラインの運用コスト
従来のETLパイプラインには、GlueのDPU料金、エラー監視・リトライ対応にかかる人件費など、隠れた運用コストが存在します。
1. Glue DPU料金
AWS Glueでは、DPU(Data Processing Unit)単位で課金されます。1 DPUは、4 vCPUと16 GBメモリに相当し、1時間あたりの料金が設定されています。日次バッチで複数のジョブを実行する場合、月間のDPU料金は数万円から数十万円に及ぶことがあります。
2. エラー監視・リトライ対応の人件費
ETLジョブがエラーで停止した場合、原因調査と修正対応が必要です。データエンジニアが1件のエラー対応に数時間を費やすこともあり、月間のパイプライン保守工数が数十時間に及ぶ場合、Zero ETLへの移行で大幅なコスト削減が見込めます。
Zero ETL利用料とROIの試算
Zero ETL統合には、データ転送量やストレージ増加に伴う追加料金が発生しますが、削減されるインフラ・人件費と比較してROIを評価することが重要です。
1. データ転送量に応じた料金
Zero ETL統合では、AuroraからRedshiftへのデータ転送量に応じて料金が発生します。転送量が多い場合は、月間数千円から数万円の追加コストとなる可能性があります。
2. Redshiftストレージの増加
Auroraのデータが全量Redshiftに同期されるため、ストレージ使用量が増加します。RA3ノードでは、ストレージとコンピュートが分離されており、必要に応じてストレージを拡張できます。
▼Redshift Serverless利用時のコスト注意点
Zero ETLの統合先にRedshift Serverlessを使用する場合、デフォルトのベースキャパシティは128 RPU(約$63/時間)に設定されています。Zero ETL統合が有効な間はRedshift Serverlessが起動状態を維持しやすいため、想定外の高額請求が発生するリスクがあります。導入前に必ずベースキャパシティを最小値(4 RPU)から設定し、使用量上限(RPUの日次上限)を設定することを強く推奨します。
3. ROIの試算
Zero ETLの利用においては、データ量や更新頻度に応じたコストシミュレーションを行い、損益分岐点を明確にすることが重要です。従来ETLの運用コストがZero ETLの追加コストを上回る場合、導入によるROIがプラスとなります。
また、「データエンジニアリングの専門スキルを持つ人材不足」という課題に対しては、Zero ETLによる工数削減の先にある「分析の民主化」も重要です。GENIEE CDPのようなAIによる自然言語分析サポートを備えたツールを導入することで、専門職でなくてもデータ活用が可能になり、組織全体のROI向上に寄与します。
業種別の導入効果事例
金融やITサービス業界では、Zero ETLの導入により、レイテンシー削減や運用効率向上の成果が報告されています。
1. Pionex US: 暗号資産取引プラットフォームのレイテンシー削減
Pionex US(出典URL: https://aws.amazon.com/jp/solutions/case-studies/pionex-case-study)は、Amazon Aurora MySQLとAmazon RedshiftのZero-ETL統合を導入し、データ処理のレイテンシーを大幅に削減しました。従来は最大30分のデータ遅延が発生していましたが、Zero ETL導入後は30秒未満に短縮され、トレーダーが市場の急激な変化に迅速に対応できるようになりました。
2. Infosys: ペタバイト規模のニアリアルタイム分析
Infosys(出典URL: https://aws.amazon.com/jp/blogs/database/how-infosys-used-amazon-aurora-zero-etl-to-amazon-redshift-for-near-real-time-analytics-and-insights)は、Amazon AuroraとAmazon RedshiftのZero-ETL統合を利用して、ペタバイト規模のデータをニアリアルタイムで分析し、物流・出荷追跡の最適化を実現しています。複数のAuroraデータベースやテーブルから複雑なパイプラインを構築することなく、データをRedshiftにシームレスに移動させる仕組みを構築しました。
3. OutSystems: データパイプライン管理工数の削減
OutSystems(出典URL: https://www.fivetran.com/case-studies/case-study-outsystems)は、サードパーティのデータ統合ツールFivetranとSnowflakeを導入し、データパイプラインを完全に自動化・マネージド化しました。
これはAWS Zero ETLとは異なるアプローチですが、パイプライン管理の自動化・マネージド化による工数削減効果の参考事例として、週25時間の削減を実現しています。
Zero ETLで対応できないケースと従来ETLとの使い分け基準
Zero ETLには技術的な制約があり、すべてのユースケースに適しているわけではありません。
この章では、複雑なデータ変換が必要な場合の代替策、外部データ連携・データ品質管理が必要な場合の対処法、スキーマ変更対応とハイブリッド構成の設計を見ていきます。
複雑なデータ変換が必要な場合の代替策
Zero ETLで生データを取り込み、Redshift側でSQLベースの変換を行うことで管理を簡素化できます。dbtを用いたRedshift内での変換や、マテリアライズドビューによる集計処理など、ELTアーキテクチャへの転換が推奨されます。
1. dbtによるSQL変換
dbt(data build tool)を使用することで、Redshift内でのSQL変換をコード管理し、テスト・デプロイのワークフローを整備できます。変換ロジックをSQLファイルとして管理し、バージョン管理システムで履歴を追跡することが可能です。
2. マテリアライズドビューによる集計
Redshiftのマテリアライズドビューを活用して、定期的に集計処理を実行し、分析用のテーブルを作成します。これにより、クエリのパフォーマンスを向上させつつ、変換ロジックをRedshift内で完結させることができます。
外部データ連携・データ品質管理が必要な場合の対処法
外部SaaSデータの取り込みや、高度なデータ品質チェックが必要な場合は、Zero ETLと外部ツールを組み合わせた構成が有効です。
1. 外部ツールによるSaaSデータ取り込み
SalesforceやGoogle Analyticsなどの外部SaaSデータは、API経由で取得する必要があります。このような場合、Fivetranなどの外部ツールでデータを取り込み、Zero ETLデータとRedshift上で結合する構成が一般的です。
なお、Zero ETLが苦手とする「外部SaaSやオフラインデータの統合」が必要なケースにおいては、標準連携機能が豊富なGENIEE CDPを併用することで、技術的な開発工数をかけずにデータを一元化し、Zero ETLの制約を補完することが可能です。
2. データ品質チェックの実装
Zero ETL統合では、データ品質チェックを同期プロセス内で実行できません。Redshift側でGreat Expectationsなどのデータ品質ツールを使用し、データの整合性や完全性を検証する仕組みを構築してください。
スキーマ変更対応とハイブリッド構成の設計
Zero ETLは、カラム追加などのスキーマ変更を自動追従しますが、データ型の変更には対応できません。段階的な移行ロードマップと変更管理プロセスの策定が推奨されます。
1. データ型変更への対応
データ型の変更はターゲット側での手動修正が必要となるため、変更管理プロセスの策定が推奨されます。ソース側でデータ型を変更する前に、Redshift側での影響範囲を確認し、必要に応じてテーブル定義を更新してください。
2. ハイブリッド構成の設計
Zero ETLと従来ETLを併用するハイブリッド構成も有効です。リアルタイム性が求められるデータはZero ETLで同期し、複雑な変換が必要なデータは従来ETLで処理することで、それぞれの長所を活かした柔軟なデータ基盤を構築できます。
AWS Zero ETL統合のまとめ
Zero ETL統合は、データソースから分析基盤へのパイプライン構築を不要にし、運用負荷を大幅に削減する技術です。従来のETLプロセスが抱えるパイプライン保守工数、データ遅延、スキーマ変更への脆弱性という3つの課題を解決し、ニアリアルタイムなデータ連携を実現します。
Zero ETLの導入により、ETLジョブの構築・管理工数が削減され、データエンジニアはより高度な分析業務に注力できるようになります。一方で、複雑なデータ変換や外部データ連携が必要な場合は、従来ETLや外部ツールとの併用が推奨されます。
もし、AWSでの基盤構築そのものが目的ではなく、その先の「AI活用やマーケティング成果」を重視される場合は、AX(AIトランスフォーメーション)を支援するGENIEE CDPの導入も検討してみてください。対応条件の確認からPoC実施、段階的移行というステップを踏むことで、導入リスクを最小化し、最適なデータ基盤を実現しましょう。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。