







名寄せとは?その意味やデータ統合に向けた具体的な進め方を解説

「名寄せをしなければ」と感じながらも、どこから手をつければよいか迷っている方は少なくありません。
SFA・CRM・MAなど複数のシステムに同一顧客のデータが散在し、表記ゆれや重複が積み重なると、営業の重複アプローチや分析精度の低下といった問題が日常的に起きるようになります。
名寄せとは、複数のシステムやデータベースに分散した同一人物・同一企業のレコードを特定し、一つの正しいレコードに統合する作業です。定義自体はシンプルですが、実務では「どの順序で進めるか」「Excelで足りるか専用ツールが必要か」「誤統合をどう防ぐか」という判断が積み重なります。
この記事では、名寄せの定義と対象範囲から、重複が生じる原因など、実務で判断に迷いやすいポイントを順に整理していきます。
名寄せとは何か?定義と対象範囲
名寄せという言葉は、もともと金融機関の文脈で使われていましたが、現在はビジネスデータ統合全般を指す言葉として広く定着しています。
まず定義と対象範囲を整理した上で、混同されやすいデータクレンジングとの関係を確認します。
名寄せツールとは?3つのタイプと選び方・主要4製品の比較を解説
名寄せが必要なデータの種類
名寄せの対象は、個人顧客データと法人顧客データの両方に及びます。個人顧客であれば氏名・住所・電話番号・メールアドレスが主な照合項目となり、法人顧客であれば企業名・法人番号・部署名・担当者名が対象になります。
特に問題が起きやすいのは、営業・マーケティング・カスタマーサポートがそれぞれ別のシステムを使っている環境です。
SFAには営業担当が登録した顧客情報、CRMにはサポート履歴、MAにはメール配信用のリストと、同一の顧客が部門ごとに独立して登録されていくため、気づかないうちに重複が蓄積します。システムをまたいで顧客の全体像を把握しようとしたとき、初めてその規模の大きさに直面するケースも珍しくありません。
名寄せロジックとは?キー設計・アルゴリズムの種類・実装手順を解説
データクレンジングと名寄せの違い
データクレンジングと名寄せは、しばしば同じ作業として混同されますが、役割が異なります。クレンジングは「表記ゆれや形式の不統一を修正する前処理」であり、名寄せは「クレンジング済みのデータを使って同一人物・同一企業を判定し、統合する工程」です。
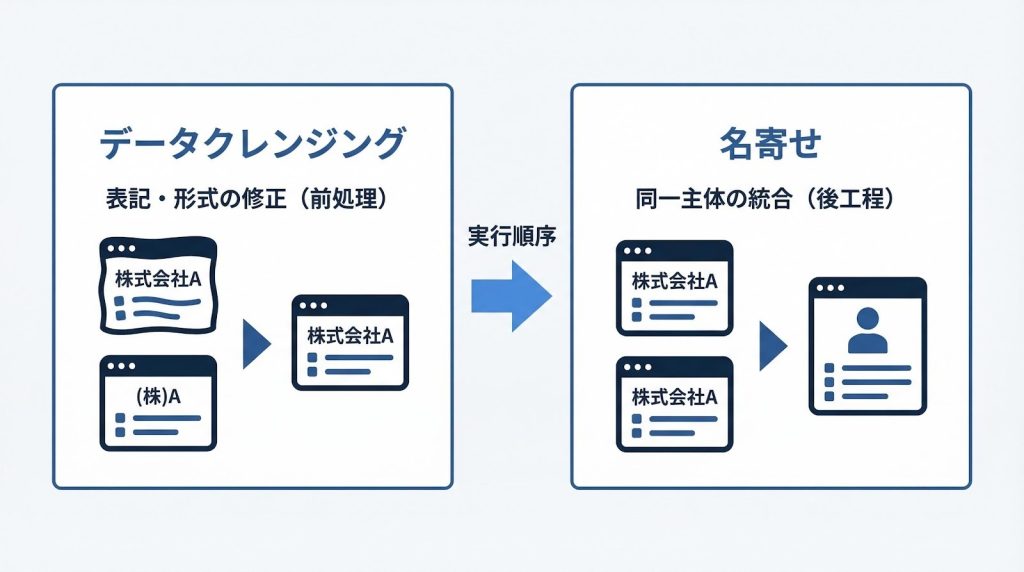
順序として、クレンジングを先に行い、その後に名寄せを実施するのが標準的な流れです。「株式会社」と「㈱」が混在したままマッチングをかけると、同一企業が別レコードとして残り続けます。クレンジングで表記を統一してからマッチングに進むことで、精度が大きく変わります。両者を独立した別工程として設計し、順序を守ることが重要です。
データクレンジングと名寄せの違いとは?実施手順やツールの選び方を解説
名寄せはなぜ必要?顧客データに重複・不整合が生じる原因
名寄せが必要になる背景には、データが重複・不整合を起こしやすい構造的な原因があります。
原因を把握しておくと、名寄せ後の再発防止策を設計するときにも役立ちます。主な原因は4つに整理できます。
- システムのサイロ化による分散登録
- 入力ルールの未統一と表記ゆれ
- 組織変更・人事異動による情報更新の断絶
- システム統合・企業合併時のデータ移行
①システムのサイロ化による分散登録
営業・マーケティング・カスタマーサポートが別々のシステムを使う環境では、同一顧客が部門ごとに独立して登録され、統合されないまま重複が蓄積していきます。
DXを阻むデータのサイロ化・属人化を解決【CDPツール】とは?
各部門がそれぞれの業務に最適化されたツールを選んだ結果として生まれる構造であり、意図的に重複させているわけではありません。
企業合併やシステム刷新の場面では、この問題がさらに深刻になります。IDが統一されないままデータ移行が行われると、既存の重複が引き継がれた上に新たな重複が加わります。
データのサイロ化により企業が被る損失とCDP活用による解決策
②入力ルールの未統一と表記ゆれ
「株式会社」と「㈱」、全角と半角の混在、スペースの有無、旧字体と新字体の違い。これらは入力担当者が複数いる環境で自然発生する表記ゆれの典型例です。
一人ひとりが自分の習慣や認識に従って入力するため、ルールを明文化しない限り統一は難しく、名寄せを実施しても再発が繰り返されます。
表記ゆれはシステム上では「別のレコード」として扱われるため、同一企業が複数の名称で登録されていても自動的には検出されません。入力段階での対策(プルダウン選択・入力チェック機能の導入)を講じないまま名寄せだけを繰り返しても、根本的な解決にはなりません。
名寄せを放置した場合のビジネスリスク
重複データを放置すると、複数の問題が同時に発生します。最も直接的なのは、同一顧客への重複アプローチによるクレームや不信感です。
営業担当者が別々に同じ顧客へ連絡してしまうケースは、顧客側から見ると「この会社は社内で情報共有ができていない」という印象を与えます。
コスト面では、DMやメールの二重送付が発生し、郵送費や広告配信費が無駄に積み上がります。分析面では、重複レコードが含まれたままの顧客数や購買データを使うと、セグメントの精度が下がり、マーケティング施策の判断が狂います。
さらに、同姓同名の別人への誤送信は個人情報の漏洩につながるリスクもあり、データ品質の問題は単なる業務効率の話にとどまりません。
複数システムのデータが散在|CDP活用でデータクレンジングと名寄せを自動化
名寄せの進め方:4つのステップで解説
名寄せは「データ調査→対象データ抽出→データクレンジング→マッチング・統合」の4ステップで進めるのが標準的な流れです。前工程の精度が後工程の品質を直接左右するため、順序を守ることが重要です。
各ステップの作業内容と注意点を順に確認します。
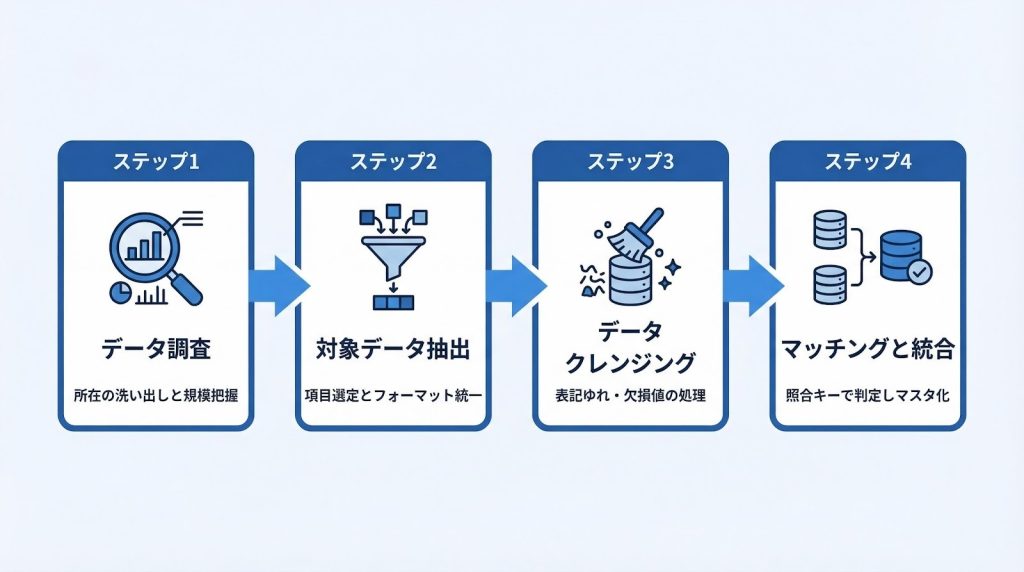
ステップ1:データ調査(現状把握)
まず、自社内に存在するすべての顧客データの保管場所を洗い出すことが出発点です。SFA・CRM・MA・Excelリストなど、部門ごとに管理されているデータソースをすべてリストアップし、各システムのデータ件数・項目・更新頻度・担当部門を確認します。
この段階で重複・不整合の規模感を把握しておくことが、後続の工程の設計に直結します。「どのシステムにどれくらいの件数があるか」「どの項目が共通しているか」を整理しないまま次のステップに進むと、抽出・クレンジングの設計が後から何度も変わることになります。
現状把握に時間をかけることは、全体の工数を減らすことにつながります。
ステップ2:対象データの抽出
名寄せに使う項目(氏名・企業名・電話番号・メールアドレス・住所など)を選定し、統合先となるマスタDBの設計方針を決めます。
どのシステムのデータを正とするか、どの項目を優先するかをこの段階で決めておくと、後のマッチング・統合工程がスムーズになります。
抽出段階で文字コード・区切り文字・日付形式などのフォーマットを統一しておくことも重要です。フォーマットがバラバラなままクレンジングに進むと、本来クレンジングで対処すべき表記ゆれの修正に加えて、フォーマット変換の作業が混在し、工数が膨らみます。
抽出時点での統一が、後続工程の負荷を大きく左右します。
ステップ3:データクレンジング
クレンジングでは、表記ゆれの統一・欠損値の処理・異常値の修正を行います。「株式会社」と「㈱」の統一、全角半角の統一、スペースの有無の統一、旧字体と新字体の統一が代表的な作業です。
欠損値や異常値については、削除・補完・保留のいずれで対処するかを事前にルール化しておく必要があります。判断を担当者に委ねると、同じ種類の欠損値でも処理方法がバラバラになり、後のマッチングで一貫性が失われます。
クレンジングの精度が名寄せ全体の品質を決めると言っても過言ではありません。表記ゆれを解消しないままマッチングを実施すると、同一人物・同一企業が別レコードとして残り続けます。前工程に十分な時間を割くことが、マッチング精度の向上に直結します。
データクレンジングと名寄せの違いとは?実施手順やツールの選び方を解説
ステップ4:マッチングと統合
マッチングでは、どの項目を照合キーとして使うか(マッチングキーの設計)と、どの判定方式を使うかの2点が重要です。
マッチングキーを氏名のみの単一項目に設定すると、同姓同名の別人を誤統合するリスクが高まります。氏名+電話番号、法人番号+部署名など、複数キーを組み合わせることで精度が上がります。
判定方式には完全一致・部分一致・あいまい一致の3種類があり、それぞれ精度と網羅性のトレードオフがあります。完全一致は誤統合が少ない反面、表記ゆれが残っているとマッチングが漏れます。あいまい一致は網羅性が高い反面、別人を同一と判定するリスクが上がります。データの性質に応じて組み合わせて使うのが実務的な対応です。
統合後のマスタレコードをどのシステムのデータを正とするかは、事前にルール化しておくことが不可欠です。
ルールがないと、統合作業のたびに判断が担当者に委ねられ、品質が安定しません。統合結果は目視確認のプロセスも設けておくと、誤統合の早期発見につながります。
Excelと専用ツール、どちらで名寄せすべきか
名寄せの手段を選ぶ際、「Excelで十分か、専用ツールが必要か」という判断に迷う方は多いです。
データ件数・更新頻度・マッチング精度の要求水準・担当者のスキル・予算という5つの軸を組み合わせて判断するのが実務的であり、どれか一つの条件だけで決めるべきではありません。
Excelで名寄せできるケースと限界
Excelは、データ件数が数千件以下でスポット対応が目的であれば、追加コストなく着手できる現実的な選択肢です。VLOOKUP・COUNTIF・条件付き書式・重複の削除といった標準機能を組み合わせることで、重複の検出と統合が可能です。担当者がExcelに習熟していれば、ツール導入の検討コストをかけずに即日着手できます。
ただし、データ件数が数万件を超えると、処理速度の低下・人的ミスのリスク増大・継続運用の困難さが顕在化してきます。大量のデータを手作業で照合するには限界があり、担当者が変わるたびに品質がばらつくという問題も生じます。「今回だけ整理できればよい」という用途には向いていますが、継続的な運用を前提とする場合は専用ツールへの移行を検討する段階です。
Excelで名寄せする方法は?関数の使い方と重複削除の手順を解説
専用ツールが必要になる判断基準
専用ツールの導入を検討すべき条件は、大きく3つあります。データ件数が数万件以上になっている、継続的な更新・運用が必要、高いマッチング精度が求められる。このいずれかに当てはまる場合は、Excelでの対応が現実的でなくなってきます。
ツールを選ぶ際の比較軸としては、名寄せ精度・対応データ形式・SFA/CRM連携の可否・価格体系・サポート体制が挙げられます。無料で使えるオープンソースの選択肢から、エンタープライズ向けの高機能製品まで、選択肢の幅は広くなっています。
なお、名寄せだけでなく複数の顧客接点データを継続的に統合・活用したい場合には、CDPという選択肢も検討に値します。GENIEE CDPはID名寄せ・統合機能を備え、ノーコードで多数のツールとデータ連携を自動化できるため、SFA・CRM・MAにまたがる顧客データを一元管理しながら、複数システムへの重複登録を継続的に解消する仕組みを構築しやすい製品です。
自社規模・用途別の選び方まとめ
自社の規模と用途に応じた選択肢を整理すると、次のように分類できます。
| 規模・用途 | 推奨ツール・手段 | 主な特徴 |
| 中小企業・少量データ・スポット対応 | Excel、OpenRefine | 追加コストなし。担当者のスキルに依存するが、一度きりの整理には十分 |
| 中堅企業・継続運用・SFA/CRM連携が必要 | uSonar、Sansan Data Hub、GENIEE CDP | SFA/CRMとの連携機能を持ち、継続的なデータ品質管理に対応。GENIEE CDPはノーコード連携とID名寄せ機能を標準搭載 |
| 大企業・大規模データ・高精度要求 | Precisely Trillium | エンタープライズ向けの高精度処理。データ品質管理・エンリッチメントも統合 |
継続的な名寄せ運用とSFA/MA連携を重視する中堅・大企業には、ID名寄せ・統合機能を持ちノーコードで複数ツールと連携できるCDPが、Excelや単機能ツールより費用対効果で優る場合があります。
ツール選定は「今の規模」だけでなく、「1〜2年後の運用体制」も見越して判断することが重要です。
名寄せで失敗しないための注意点
名寄せを実施しても、運用設計が伴わなければ効果は長続きしません。典型的な失敗パターンを把握した上で、継続的に機能させる仕組みをセットで設計することが重要です。
よくある失敗パターンと対策
名寄せの失敗は、大きく4つのパターンに集約されます。
1. 誤統合(同姓同名・類似名称の別人を同一と判定)
同姓同名の別人を誤統合すると、個人情報の漏洩トラブルに直結します。防止策は、複数マッチングキーの組み合わせと、統合前の目視確認プロセスの設計です。
氏名だけでなく電話番号や住所を組み合わせることで、誤統合のリスクを大幅に下げられます。
2. マッチングキーの単一設定
氏名のみ、メールアドレスのみといった単一キーでマッチングを設定すると、精度が低下します。特に法人データでは、担当者の異動や部署名の変更によってキーが変わることがあるため、法人番号を軸にした複数キーの設計が有効です。
3. 一度きりの実施で終わる
名寄せを一度実施しても、入力ルールを整備しなければ新規データの蓄積とともに表記ゆれ・重複が再発します。「名寄せをした」という事実で安心してしまい、その後の運用設計を怠るケースが多く見られます。定期的な再実施を前提とした設計が必要です。
4. 入力ルールの未整備
名寄せの実施と並行して、入力ルールの標準化を進めないと再発が繰り返されます。プルダウン入力の導入や法人番号の活用など、入力段階での統制が長期的なデータ品質を左右します。
名寄せを継続的に機能させる運用設計
名寄せを一度きりで終わらせないためには、入力ルールの標準化・定期クレンジングサイクルの設定・担当者の明確化という3つの仕組みをセットで整備する必要があります。
入力ルールの標準化では、プルダウン入力の導入・法人番号の活用・入力チェック機能の設定が有効です。担当者が変わっても同じ品質でデータが入力される環境を作ることが目標です。
定期クレンジングのタイミングは、月次または四半期ごとが目安になりますが、データの更新頻度や業務サイクルに合わせて設定してください。
こうした運用を自動化したい場合、GENIEE CDPのようなCDPはノーコードで多数のツールとのデータ連携・集約を自動化できるため、担当者の運用負荷を抑えながらデータの鮮度を維持しやすいという特長があります。
SFA・CRM・MAなど複数システムのデータを自動で集約し、ID名寄せ・統合を継続的に実行できる仕組みを、専門知識なしに構築できる点は、運用体制が手薄な組織にとって特に有効な選択肢です。
名寄せ後のデータ活用で得られるビジネス効果
名寄せによってデータの重複が解消されると、複数のビジネス効果が同時に得られます。マーケティングのセグメント精度が向上し、同一顧客への重複送付が減ることでDM郵送費や広告配信費の削減にもつながります。
営業面では、重複アプローチが排除され、顧客情報を一元的に参照できる環境が整います。
さらに、統合されたクリーンな顧客データをMAツールやSFAへ連携することで、一人ひとりの行動履歴に基づいたパーソナライズ施策の実行精度が高まります。名寄せは「データを整理する作業」ですが、その先にあるのは顧客との接点の質を上げることです。
データ品質の改善が、施策の精度向上に直結する構造を意識しておくと、名寄せへの投資対効果を社内で説明しやすくなります。
まとめ:名寄せを自社で進めるための判断ポイント

名寄せを自社で進める際の判断材料として、次の4点を確認してください。
- データ件数はどのくらいか(数千件以下ならExcel、数万件以上なら専用ツールを検討)
- 更新頻度はどのくらいか(継続的な運用が必要なら自動化の仕組みが必要)
- 担当者・責任部門は明確か(属人化を防ぐ体制があるか)
- ツール導入の予算はあるか(無料ツールから試せる選択肢もある)
名寄せは一度実施すれば終わりではなく、入力ルールの標準化・定期クレンジング・担当者の明確化とセットで運用することで初めてデータ品質管理の仕組みとして機能します。
まずExcelで現状の重複件数を確認し、規模や運用体制に応じて専用ツールやCDPの活用を検討するという進め方が、現実的な初動として多くの場面で有効です。
継続的な名寄せ運用とSFA・MA連携まで視野に入れている場合は、ID名寄せ・統合機能を持ちノーコードで複数ツールと連携できるGENIEE CDPも選択肢の一つとして検討してみてください。
導入支援チームによる要件定義から、活用ノウハウを持った運用支援チームの伴走まで、サポート体制が整っている点も、継続運用を前提とする組織には心強い材料です。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。















