







データマートの設計方法を解説!作り方の手順・テーブル定義書の書き方

データマートの設計を担当することになったとき、最初に迷うのは「そもそもDWHやビューと何が違うのか」という基本的な位置づけの問題です。テーブルで作るべきかビューで作るべきか、スタースキーマをどう適用するか、設計書には何を書けばよいか。判断が必要な場面が次々と現れ、どこから手をつければよいか見えにくくなりがちです。
データマートは、特定の部門や用途に特化した分析用データセットです。データレイクで生データを蓄積し、DWHで全社統合を行い、その先の「消費層」としてデータマートが位置づけられます。この3層の役割分担を理解することが、設計判断の出発点になります。
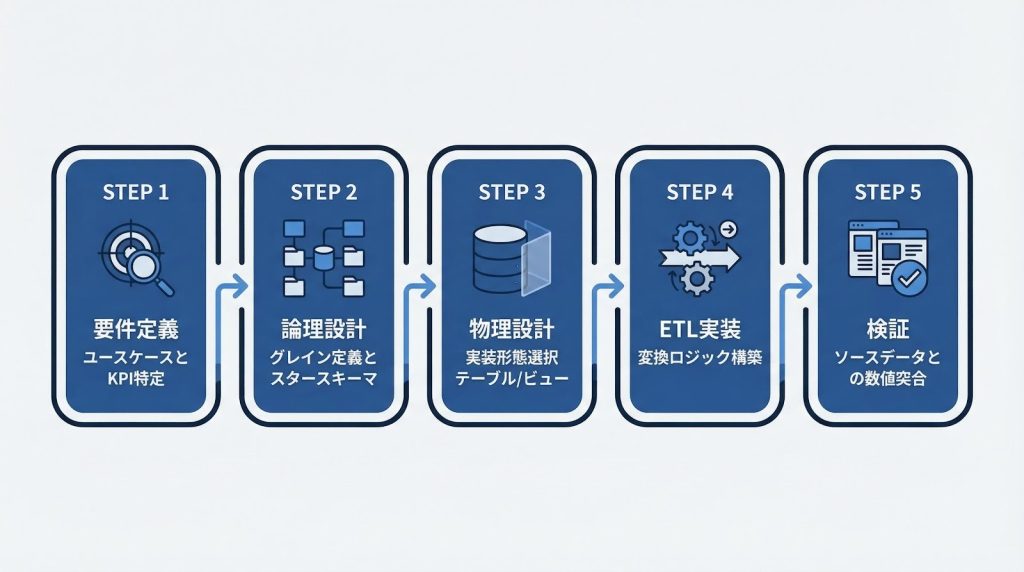
設計の進め方は、ユースケースとKPIの特定から始まり、論理設計・物理設計・ETL実装・検証という5つのステップで構成されます。各ステップで何を決め、何を成果物として残すかを把握しておくことで、後工程での手戻りを大幅に減らせます。
データレイク・データウェアハウス・データマートの違いや特徴を比較
データマートとは何か:DWH・データレイク・ビューとの役割の違い
データマートを正しく設計するには、まず「何のためのデータセットか」という目的を明確にする必要があります。
DWHやデータレイクと混同したまま設計に入ると、対象範囲が広すぎるマートや、逆に粒度が細かすぎて使いにくいマートができあがります。ここでは3層構造の役割分担を整理し、ビューとの概念的な違いも含めて確認します。
データレイク・DWH・データマートの3層構造
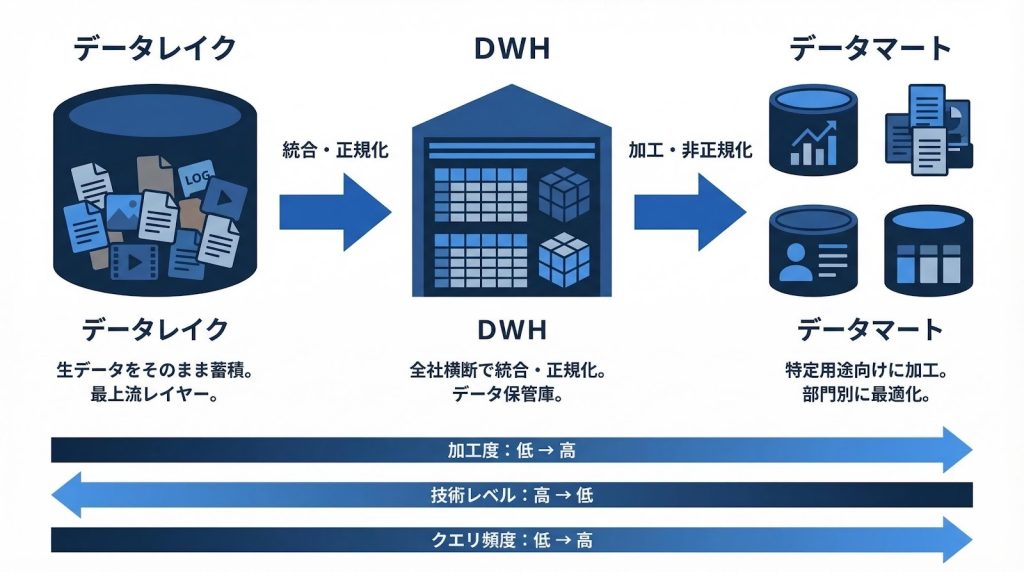
データ基盤は一般的に、データレイク・DWH・データマートという3つのレイヤーで構成されます。
それぞれの役割は明確に異なり、どのレイヤーに何を置くかを誤ると、クエリ性能の低下や管理コストの増大につながります。
| レイヤー | 主な役割 | 格納データの性質 | 主な利用者 |
| データレイク | 生データの蓄積 | 未加工・多形式(ログ、CSV、JSONなど) | データエンジニア |
| DWH | 全社統合・整理 | クレンジング済み・正規化されたデータ | データエンジニア、アナリスト |
| データマート | 部門・用途別の消費 | 目的別に加工・集計されたデータ | ビジネスユーザー、BIツール |
各レイヤーへの配置判断は、データの加工度・利用者の技術レベル・クエリ頻度の3軸で考えると整理しやすくなります。生データをそのままBIツールに接続するのではなく、用途に合わせた加工を経てデータマートとして提供することで、利用者側の負担を減らせます。
データマートとは?DWH・データレイクとの違いと構築手順を解説
データマートとDWH・ビューの違い
DWHとデータマートは「どちらも分析用データ」という点で混同されやすいですが、設計の方向性が根本的に異なります。また、「ビューを作ればデータマートになる」という誤解も現場でよく見られます。
DWHは全社横断のデータを高い正規化度で保持し、更新整合性を重視した設計が基本です。
一方、データマートは特定の部門や用途に絞り、クエリ性能を優先した非正規化設計を採用します。対象範囲・粒度・最適化の方向性、いずれも異なります。
ビューについては、概念としてのデータマートとは別物として理解する必要があります。データマートは「特定用途に最適化されたデータセット」という概念であり、その実装手段としてビュー・物理テーブル・マテリアライズドビューのいずれも選択できます。
ビューを作ることがデータマートの設計ではなく、目的に応じた実装形態の一つとしてビューを選ぶ、という順序が正しい考え方です。
データマート設計の全体ステップ:要件定義から検証まで

データマートの設計は、何から始めて何を順に決めるかが明確でないと、途中で方向性がぶれて手戻りが発生します。
設計は以下の5ステップで進め、各フェーズの成果物を明確にすることが重要です。
- 要件定義
- 論理設計
- 物理設計
- ETL実装
- 検証
なお、要件定義や実装の工程で社内リソースに不安がある場合は、GENIEE CDPといった導入支援チームが伴走するサービスやノーコード連携ツールの活用も選択肢として念頭に置いておくと、設計開始までのリードタイムを短縮できます。
CDPとデータマートの違いとは?構造・役割・使い分けの判断基準を解説
ステップ1:ユースケースとKPIの特定(要件定義)
設計の最初のアクションは、利用部門へのヒアリングです。ユースケースが曖昧なままモデリングに入ると、集計粒度の再設計や不要カラムの混入が発生し、後工程での修正コストが積み上がります。
ヒアリングで最低限確認すべき項目は次の4点です。
- 何のKPIを見たいか(売上・CVR・在庫回転率など)
- どの軸でフィルタするか(期間・地域・商品カテゴリなど)
- 更新頻度はどの程度か(リアルタイム・日次・週次など)
- どのBIツールを使うか(Tableau・Looker・Power BIなど)
この4点が固まらないと、ファクトテーブルの粒度もディメンションの構成も決められません。特に「どのBIツールを使うか」は物理設計の構造に直接影響するため、要件定義の段階で確定させておく必要があります。
社内にデータ設計の専門家がおらず、ヒアリング設計や要件定義の進め方自体に不安がある場合は、のように導入支援チームが要件定義から伴走するサービスを活用することで、設計開始までの工数を大幅に短縮できます。
ステップ2:論理設計(ディメンションとメジャーの洗い出し)
要件定義でユースケースが固まったら、次はファクトテーブルとディメンションテーブルの役割分担を決める論理設計に入ります。このフェーズで最も重要な決定事項は、集計粒度(グレイン)の定義です。
グレインとは「ファクトテーブルの1行が何を表すか」を定義したものです。たとえば「1注文明細行」なのか「1日・1商品・1店舗の集計値」なのかによって、テーブルの構造が根本的に変わります。粒度が曖昧なままファクトテーブルを設計すると、二重集計や欠損が生じ、BIツール上の数値が信頼できなくなります。
スタースキーマの基本構造として、ファクトテーブルには数値メジャーと外部キーのみを持たせ、属性情報はすべてディメンションテーブルに分離します。「売上金額」「数量」はファクト、「商品名」「カテゴリ」「地域」はディメンションという切り分けが基本です。
ステップ3:物理設計(テーブル構造・実装形態の選択)
論理設計で構造が決まったら、実際にどの形態で実装するかを選択します。物理テーブル・ビュー・マテリアライズドビューの3つが主な選択肢であり、それぞれ適した用途が異なります。
| 実装形態 | 適したケース | 主なトレードオフ |
| 物理テーブル | クエリ頻度が高く、データ量が大きい場合 | ストレージコストと更新管理が必要 |
| ビュー | ソースデータの更新頻度が高く、常に最新値が必要な軽量集計の場合 | クエリのたびに再計算が走るため、大量データや複雑な集計には不向き |
| マテリアライズドビュー | クエリ性能とデータ鮮度のバランスが必要な場合(例:日次更新の中規模集計) | 更新タイミングの設計が必要。DBMSによって自動更新の仕様が異なる |
BIツール接続を前提とする場合、集計粒度の統一とフィルタ軸のディメンション設計への反映を物理設計の段階で確定させることが重要です。BI側で追加の加工が必要になると、ツールごとに計算ロジックが分散し、数値の不一致が起きやすくなります。インデックス・パーティション・クラスタリングの設計も、クエリパターンを踏まえてこの段階で決めておきます。
ステップ4〜5:ELT実装・データ投入・検証
物理設計が固まったら、ETL/ELTの実装とデータ投入に進みます。このフェーズでは、変換ロジックをどう管理するかと、ユーザー検証をどう進めるかが主な論点です。
ELTツールとしてdbtを活用すると、変換ロジックをSQLコードとして管理し、モデル間の依存関係を可視化しながらドキュメントを自動生成できます。手動でスプレッドシートに変換仕様を書き続ける運用と比べると、スキーマ変更時の影響範囲の特定が格段に速くなります。
ユーザー検証では、BIツール上の集計値をソースデータの期待値と突合することが基本です。「売上合計がDWHの集計と一致するか」「フィルタをかけたときに正しく絞り込まれるか」を確認します。あわせて、クエリ実行時間が要件を満たしているかもこの段階で確認し、必要であればインデックスやパーティションの設定を見直します。
ETL実装の工数を削減したい場合は、ノーコードでのデータ連携機能を持つツールの活用が有効です。GENIEE CDPは標準で多数のツールとノーコード連携でき、複数のデータソースを集約する実装工程を大幅に短縮できます。
データモデリング手法の選択と適用:スタースキーマ・非正規化の判断基準

設計ステップの全体像を把握したところで、論理設計の核心であるモデリング手法の選択に踏み込みます。
スタースキーマとスノーフレークスキーマのどちらを選ぶか、非正規化をどこまで進めるかは、クエリ性能・更新頻度・ユーザーの利用パターンを軸に判断します。
なぜデータマートは非正規化設計が基本なのか
OLTPシステムのデータベースは、更新整合性を保つために正規化設計が基本です。しかしデータマートでは、この正規化がクエリ性能の足かせになります。
正規化されたテーブル群に対してBIツールがクエリを発行すると、多数のJOINが発生します。テーブル数が増えるほど実行計画が複雑になり、ユーザーがダッシュボードを開くたびに待ち時間が生じます。分析の文脈では、データの更新よりも読み取りの速度が優先されるため、JOINを減らす方向で設計するのが合理的です。
非正規化によってJOIN数を削減すると、BIツールが発行するクエリの実行時間が短縮され、ユーザーの分析体験が向上します。「商品マスタ」「カテゴリマスタ」「ブランドマスタ」を別々のテーブルに持つのではなく、ディメンションテーブルに属性をまとめて持たせることで、ファクトテーブルとの1回のJOINで必要な情報が取得できるようになります。
スタースキーマの設計方法と適用基準
スタースキーマは、1つのファクトテーブルを複数のディメンションテーブルが囲む構造です。BIツールからのアドホッククエリが多い場合や、ビジネスユーザーが直接テーブルを参照する場合に最も適しています。
ファクトテーブルには集計粒度・数値メジャー・ディメンションへの外部キーのみを持たせます。「売上金額」「数量」「割引額」といった数値と、「日付ID」「商品ID」「顧客ID」「店舗ID」といった外部キーだけで構成するのが基本です。商品名やカテゴリ名などの属性情報はすべてディメンションテーブルに集約します。
ディメンションの属性が時間とともに変化する場合(SCD:緩やかに変化するディメンション)は、設計段階で対応方針を決めておく必要があります。
- Type1(上書き):最新の値のみ保持。履歴は不要だが変更前の分析ができなくなる
- Type2(履歴保持):変更のたびに新しい行を追加し、各行に有効開始日・有効終了日(または現在フラグ)を付与する。過去時点の状態を正確に再現できるが、テーブル行数が増加する
- Type3(前後値保持):現在値と直前値のみカラムで保持。シンプルだが履歴の深さに限界がある
どの方針を選ぶかは、「過去時点の状態を正確に再現する必要があるか」という分析要件で決まります。
スノーフレークスキーマと非正規化度合いの調整
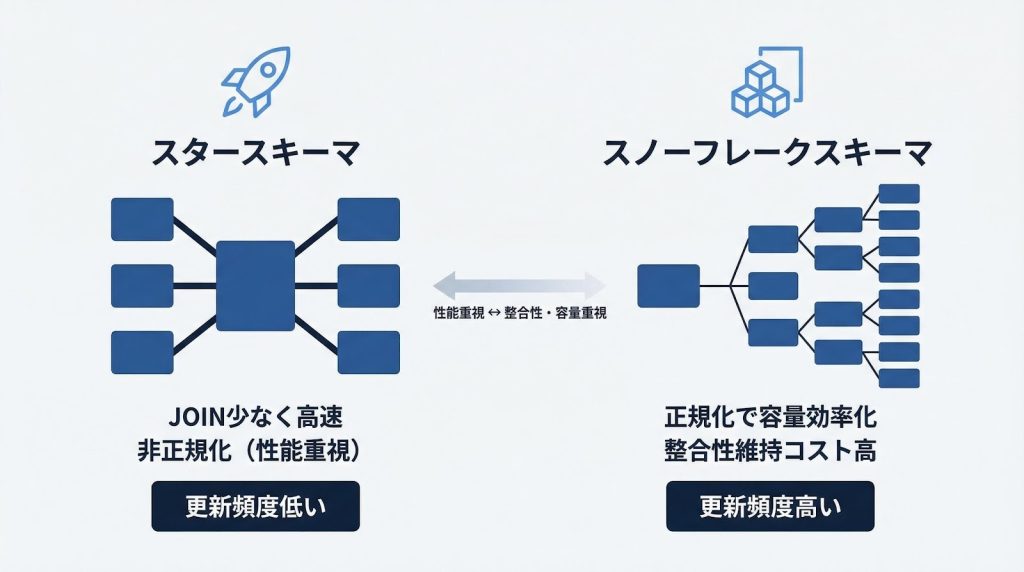
スタースキーマがすべての場面で最適とは限りません。ディメンションの階層が深い場合や、ストレージ効率を優先したい場合は、スノーフレークスキーマが選択肢になります。
スノーフレークスキーマは、ディメンションテーブルをさらに正規化して階層構造を持たせた設計です。たとえば「商品」→「サブカテゴリ」→「カテゴリ」という階層を別テーブルに分離します。重複データが減るためストレージ効率は上がりますが、クエリ時のJOIN数が増えるため、スタースキーマと比べてクエリ性能は低下しやすくなります。
非正規化の度合いを調整する主な判断軸は、階層の深さとストレージ効率です。ディメンションの階層が深い場合(商品→サブカテゴリ→カテゴリ→部門など)はスノーフレーク化によってデータの重複を削減できます。
一方、更新頻度が高い属性(価格、在庫状況など)は、ディメンションテーブルに含めるとSCDの管理コストが増大するため、ファクトテーブルに直接持たせるか、SCD Type4(ミニディメンション)として分離する設計が推奨されます。どちらか一方に統一するのではなく、ディメンションごとに判断するのが実務的なアプローチです。
設計書・テーブル定義書に記載すべき項目と書き方
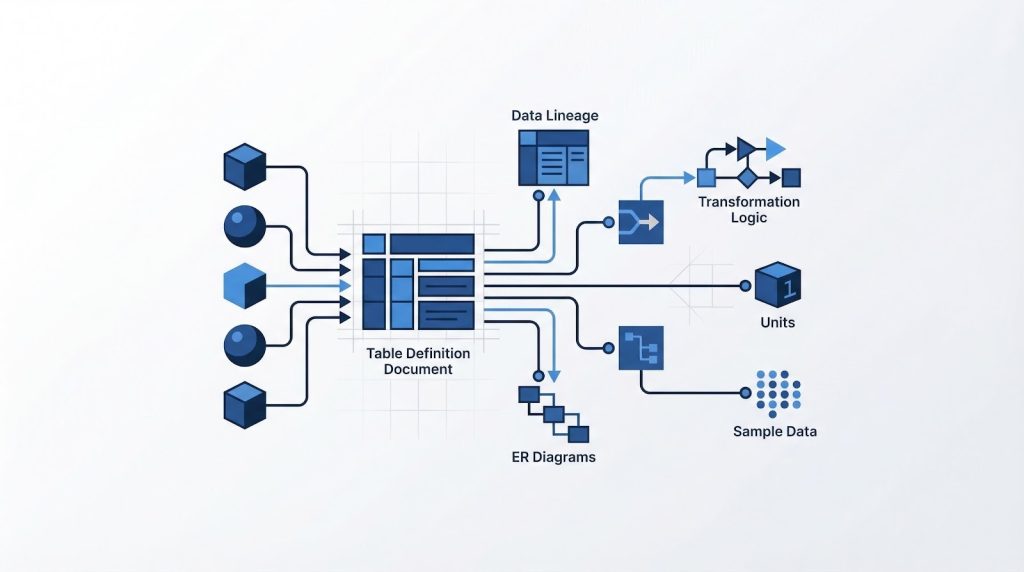
モデリングの設計が固まったら、それを設計書として記録する工程が必要です。設計書の整備を後回しにすると、実装者が独自解釈でSQLを書き始め、集計値の不一致や仕様の属人化が起きます。
テーブル定義書・データリネージ・ER図の役割分担を理解したうえで、何をどこに記録するかを決めておきましょう。
テーブル定義書の必須記載項目
テーブル定義書には、次の10項目を最低限記載します。
| 項目 | 記載内容の例 | 省略した場合の問題 |
| カラム名 | sales_amount | 命名の揺れが発生する |
| データ型 | DECIMAL(15,2) | 型変換エラーが実装時に発覚する |
| ソーステーブル | orders | 影響範囲の特定ができなくなる |
| ソースカラム名 | order_amount | マッピングが属人化する |
| 変換ロジック | 税抜金額 × 数量 | 実装者が独自解釈し集計値が不一致になる |
| 単位 | 円(税抜) | 円・千円・百万円の混在が起きる |
| サンプルデータ | 12500 | カラムの意味を誤解するリスクが残る |
| NULL許容 | NOT NULL | NULLの扱いが実装者任せになる |
| 主キー/外部キー | PK / FK(dim_product.product_id) | JOIN条件の誤りが発生しやすくなる |
| 更新頻度 | 日次(毎朝6時) | ETLスケジュールとの整合が取れなくなる |
特に変換ロジックと単位の省略は、実務上の影響が大きい項目です。変換ロジックを省略すると実装者が独自解釈でSQLを書き、集計値の不一致が発生します。
単位を省略すると円・千円・百万円の混在が起き、BIツール上の数値が信頼できなくなります。サンプルデータを記載しておくと、実装者がカラムの意味を誤解するリスクを減らせるうえ、レビュー時の確認工数も削減できます。
データリネージの記録方法
テーブル定義書が「各カラムの仕様」を記録するものだとすれば、データリネージは「データがどこから来てどう変換されたか」という流れを記録するものです。ソーステーブルのスキーマ変更が発生したとき、データリネージがなければ影響を受けるデータマートのカラムを特定するのに時間がかかります。
データリネージの記録に含めるべき情報は、ソーステーブル名・ソースカラム名・変換ロジック・出力カラム名の対応関係です。これが整備されていると、「orders.order_amountのデータ型が変わった」という変更が発生した際に、影響を受けるデータマートのカラムを即座に洗い出せます。
dbtを活用している場合、モデル間の依存関係をDAG(有向非巡回グラフ)として可視化し、ドキュメントを自動生成する機能を利用できます。手動でスプレッドシートにリネージを管理する運用と比べると、スキーマ変更への対応速度が大きく変わります。
テーブル定義書以外に整備すべき設計ドキュメントとして、ER図(テーブル間の関係)・データフロー図(ソースからマートへの変換経路)・集計定義書(KPIの計算ロジック)があります。それぞれ記録する情報の性質が異なるため、テーブル定義書に詰め込もうとせず、役割を分けて管理することをお勧めします。
データマートのガバナンス設計と運用時の失敗回避
設計書が整備されても、組織全体のルールがなければデータマートは無秩序に増殖します。部門ごとに独自のマートが作られ始めると、集計定義のばらつき・依存関係の複雑化・属人化という3つの問題が連鎖的に発生します。
これらを防ぐには、命名規則・マート台帳・アクセス制御・ETL依存関係の可視化を設計段階で組み込む必要があります。
マート乱立を防ぐ命名規則とマート台帳の設計
データマートの乱立は、多くの場合「誰かが既存のマートを知らずに同じようなものを作る」ことから始まります。これを防ぐ最初の手段が、命名規則とマート台帳の整備です。
命名規則は、マート名を見ただけで用途・オーナー部門・粒度が識別できる形式にします。たとえば mart_{部門}_{用途}_{粒度} というパターンを定めると、mart_sales_revenue_daily(営業部門・売上・日次)のように一覧を見るだけで内容が把握できます。命名規則がないと、sales_data・sales_summary・sales_report のような名前が乱立し、どれが正式なマートか判断できなくなります。
マート台帳には次の項目を記載し、新設申請時に既存マートとの重複確認に使います。
- マート名
- 用途・分析目的
- オーナー部門
- 更新頻度
- 依存ソーステーブル
- 廃止予定の有無
マート新設時に「既存マートで代替できないか」を確認するレビューゲートを設けることで、重複マートの発生を設計プロセスの段階で抑制できます。このレビューを形式化しておかないと、台帳があっても参照されないまま新設が繰り返されます。
のような統合基盤を活用すると、複数のデータソースを同一環境で一元管理できるため、部門ごとに野良マートが発生する状況を構造的に防ぐことができます。データが一か所に集約されていれば、マート台帳の管理負荷そのものを大幅に下げられます。
アクセス制御とセキュリティ要件の組み込み方
アクセス制御とPIIマスキングは、実装後に追加しようとすると対応コストが大きくなります。設計段階で組み込むことが、実装漏れと後付け対応コストを防ぐ最も確実な方法です。
PIIを含むカラム(氏名・メールアドレス・電話番号など)は、設計段階でマスキング対象として特定し、変換ロジックをテーブル定義書に記載します。「このカラムはハッシュ化する」「このカラムは部分マスク(下4桁のみ表示)する」という仕様を設計書に明記しておくことで、実装者が独自判断で処理を省略するリスクを防げます。
カラムレベルのアクセス制御は、部門ごとに参照可能なカラムを設計書上で定義し、実装時にデータウェアハウスの権限設定と対応させます。たとえば「人事部門のみが参照できる給与関連カラム」「営業部門が参照できる売上カラム」のように、設計書とDWHの権限設定を1対1で対応させる運用が管理しやすくなります。
こうしたアクセス制御やPIIマスキングの設定を個別に実装・管理する手間を削減したい場合は、セキュリティ管理機能を標準搭載した製品を選ぶことで設計・運用コストを抑えられます。GENIEE CDPはID名寄せや権限管理の機能を標準で備えており、設計段階で定めたアクセスポリシーをそのまま運用に落とし込みやすい構成になっています。
ETL依存関係の可視化と更新頻度の設計
ETLジョブの依存関係が可視化されていないと、ソーステーブルの変更がどのデータマートに影響するかを把握するのに時間がかかります。特に複数のマートが同じソーステーブルを参照している場合、依存関係が不明確だと変更時の影響調査が属人化します。
dbtのDAGは、staging(ソース整形)・intermediate(中間変換)・mart(消費層)の3レイヤーで責務を分離し、モデル間の依存関係を自動的に可視化します。どのモデルがどのモデルに依存しているかが一目でわかるため、ソース変更時の影響範囲を即座に特定できます。
更新頻度の設計は、リアルタイム性の要件とコストのバランスで決めます。リアルタイム性が求められるKPI(在庫数・注文件数など)はストリーミング処理、日次・週次の集計レポートはバッチ処理という使い分けが基本です。すべてのマートをリアルタイム更新にしようとすると、インフラコストが不必要に膨らむため、KPIごとに必要な鮮度を確認してから更新頻度を決めることをお勧めします。
なお、GENIEE CDPはオンライン・オフラインを問わずすべての顧客接点からのデータをリアルタイムで一元管理する機能を備えており、更新頻度の設計と実装を同一基盤上で完結させたい場合の選択肢として検討できます。自然言語でデータを分析できるAI機w能も搭載しているため、設計者だけでなくビジネスユーザーの自走を促し、運用負荷を分散させる効果も期待できます。
CDPツールランキングおすすめ15選!主要機能や選び方を解説
まとめ:データマート設計を成功させるための判断基準

この記事では、データマートの定義と3層構造における位置づけから始まり、設計の5ステップ、モデリング手法の選択基準、設計書の記載項目、ガバナンス設計の考え方を整理しました。
設計を前進させるうえで押さえておくべき判断基準は、次の順序で積み上がります。まず「データマートが3層のどこに位置するか」を確認し、DWHのビューで代替できるかを判断します。次に「ユースケースとKPIが特定できているか」を確認し、これが固まらないうちはモデリングに入らないことが重要です。
dbtのようなELTツールを活用すると、変換ロジックのコード管理・依存関係の可視化・ドキュメント自動生成を同時に実現でき、設計書の手動管理コストを大幅に削減できます。設計の最初のアクションとして、まず利用部門へのヒアリングを行い、KPIとフィルタ軸を確定させることから始めてください。
設計工数の確保や社内専門性の不足が課題になる場合は、GENIEE CDPのような導入支援チームが伴走し、ノーコード連携・AI分析・統合管理機能を標準搭載した基盤の活用も選択肢として検討に値します。
自前でゼロから構築するアプローチと、支援ツールを組み合わせるアプローチを比較したうえで、自社の状況に合った進め方を選んでください。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。













