







ETLを活用した物流業界におけるデータ連携の仕組みと導入事例を解説

WMS・TMS・ERPといった複数の基幹システムを抱える物流現場では、システム間のデータ連携を手作業のExcel転記や個別スクリプトに頼り続けているケースが少なくありません。
「担当者が変わったらスクリプトが動かなくなった」「在庫の実態を把握するのに翌日まで待たなければならない」そうした状況に課題を感じながらも、具体的な解決策が見えていない担当者は多いはずです。
ETL(Extract・Transform・Load)は、異なるシステム間のデータを自動的に抽出・変換・格納する仕組みです。物流業務における手作業の削減、属人化の解消、リアルタイムなデータ把握の実現に直接つながる技術として、国内の物流企業でも導入事例が積み上がってきています。
この記事では、物流現場でデータ連携が手作業に頼り続ける構造的な理由を整理したうえで、ETLの仕組みと物流業務への具体的な適用シーン、実際の導入事例、そしてツール選定の判断基準を順に説明します。
ETL導入で確認すべきポイントとは?メリットや注意点、選定のポイントも解説
物流現場のデータ連携が手作業に頼り続ける理由

物流業界のデータ連携問題は、単一の原因ではなく複数の構造的要因が絡み合っています。
- システムごとのデータ形式の不一致
- 手作業・属人スクリプトへの依存
- データ分散によるリアルタイム把握の困難さ
これらの要因が複合的に作用することで、「わかっていても変えられない」状況が生まれています。
1. システムごとに異なるデータ形式が生む「つなぎ目の断絶」
WMS(倉庫管理システム)・TMS(輸送管理システム)・ERP(基幹業務システム)は、それぞれ異なるベンダーが異なる時期に開発・導入してきた経緯があります。
そのため、同じ「商品コード」という項目ひとつをとっても、WMSでは8桁の数字、ERPでは英数字混在の12桁、TMSでは取引先ごとの独自コードといった具合に、桁数・命名規則・更新タイミングがシステムごとにバラバラなのが実態です。
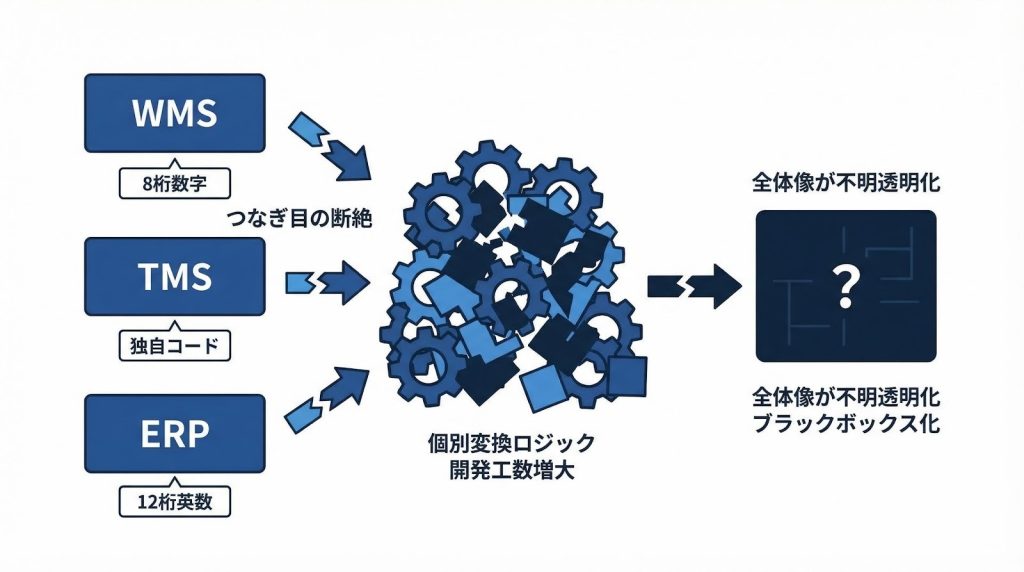
この「つなぎ目の断絶」は、システムを導入するたびに個別の変換ロジックを開発しなければならないことを意味します。
標準化が進んでいない環境では、取引先が増えるたびに対応工数が積み上がり、やがて全体像を把握している担当者が誰もいなくなるという状況に陥りがちです。
2. 手作業・属人スクリプトへの依存が生む3つのリスク
データ形式の不一致を「とりあえず動く形」で解決しようとすると、多くの現場ではExcelの手作業転記か、担当者が独自に書いたスクリプトに行き着きます。この対処法は短期的には機能しますが、時間が経つにつれて3つのリスクが顕在化してきます。
手作業ではヒューマンエラーが発生しやすい
第一に、ヒューマンエラーの問題です。手作業でのデータ転記は入力ミスを生みやすく、誤ったデータが在庫管理や請求処理といった下流の業務に波及するリスクがあります。
気づいたときには複数のシステムに誤データが広がっており、修正に多大な工数がかかるケースも珍しくありません。
業務が属人化しやすい
第二に、属人化のリスクです。個人が作成したスクリプトは、その担当者が異動・退職すると誰もメンテナンスできなくなります。
「なぜこのロジックになっているのか」という背景が引き継がれないまま、業務継続性が損なわれる状況は物流現場で繰り返し起きています。
データ統合に時間がかかり、機会損失が発生する
第三に、機会損失の問題です。集計やレポート作成に多大な工数を費やすことで、本来注力すべき分析・改善業務に時間を割けなくなります。
データを「作る」ことに追われ、データを「使う」ことができない状態です。
顧客データ統合とは?仕組みから名寄せ・要件定義まで基礎を解説
データが分散したままでは何が見えなくなるか
受注・在庫・出荷・配送のデータがそれぞれ別のシステムに分散したまま管理されていると、現場で起きていることをリアルタイムに把握することが難しくなります。
欠品が発生しても気づくのが翌日、配送遅延の兆候があっても集計が終わるまで確認できない。こうした「後手に回る対応」が常態化します。
影響は現場だけにとどまりません。経営層が在庫削減や輸送コストの見直しを判断しようとしても、必要なデータが揃っていなければ根拠のある意思決定ができません。データが分散している状態は、現場の作業効率だけでなく、経営判断のスピードと精度にも直接影響します。
データのサイロ化により企業が被る損失とCDP活用による解決策
ETLとは何か:物流データ連携における3つの役割
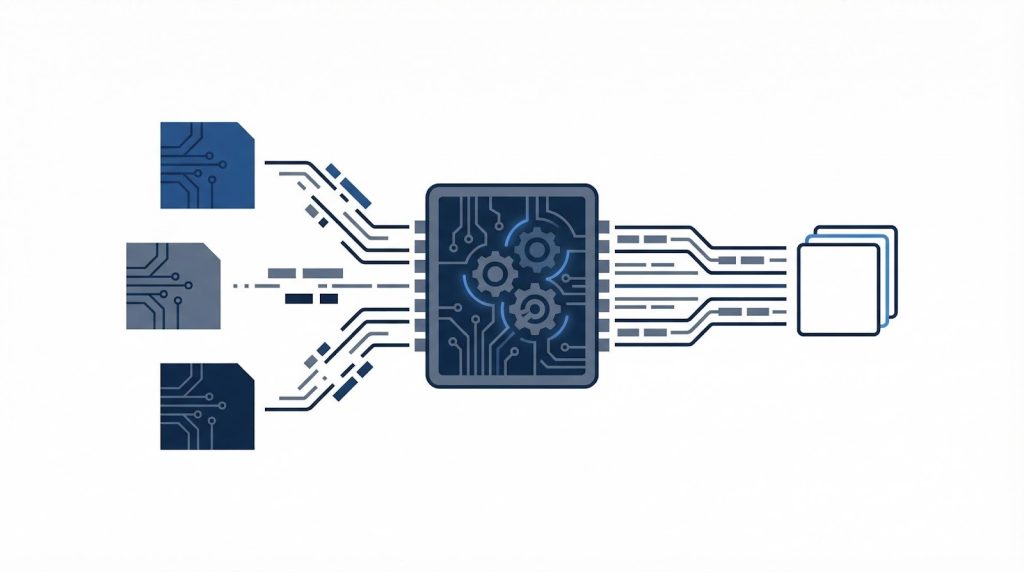
ETLとは、Extract(抽出)・Transform(変換)・Load(格納)という3つの工程を通じて、複数のシステム間のデータを自動的に統合する仕組みです。
物流の文脈では、WMS・TMS・ERP・EDIといった異なるシステムが持つデータ形式の差を吸収し、分析や業務活用に使える状態へ変換する役割を担います。各工程が具体的に何をしているかを順に見ていきます。
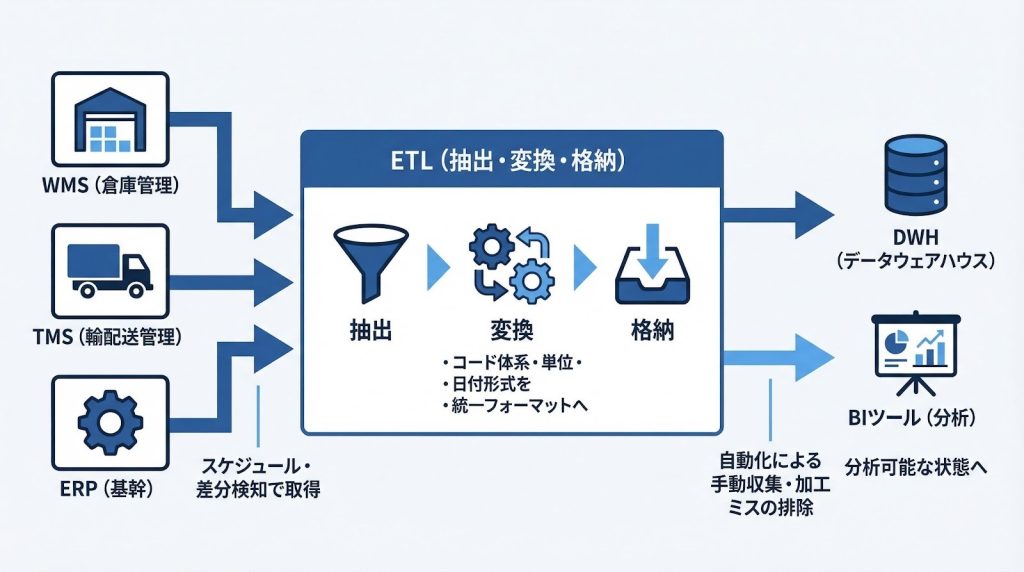
Extract(抽出):複数の物流システムからデータを集める
Extract工程では、WMS・TMS・ERP・EDIなど異なるシステムに散在するデータを自動的に取り出します。スケジュール実行(例:毎夜0時に前日分を一括取得)や差分検知(更新されたレコードのみを検出して取得)といった方式を使うことで、人が手動でデータを収集する必要がなくなります。
手動収集との最大の違いは、取得漏れや取得タイミングのばらつきが生じない点です。複数のシステムから同じ基準で定期的にデータを引き出せるため、後続の変換・格納工程が安定して機能します。
Transform(変換):バラバラなデータ形式を統一する
Transform工程は、ETLの3工程の中で最も複雑な処理が行われる部分です。システムごとに異なるコード体系・単位・日付形式を、下流システムで利用できる統一フォーマットへ変換します。たとえば、WMSでは「20240101」形式の日付をERPが要求する「2024/01/01」形式へ変換する、あるいは取引先ごとに異なる商品コードを自社の統一コードへマッピングするといった処理がここで行われます。
物流業界特有の観点として、流通BMSや物流EDIといったデータ形式への対応が挙げられます。これらの形式に標準対応しているETLツールであれば、取引先とのデータ交換をカスタム開発なしに自動化できます。対応していない場合は個別の変換ロジックを開発する必要があり、導入コストと工数が大きく膨らむ点に注意が必要です。
Load(格納):分析・活用できる場所にデータを届ける
Load工程では、変換済みのデータをDWH(データウェアハウス)・BIツール・ERPなどの目的地へ格納します。この工程が完了することで、経営ダッシュボードや分析基盤での即時活用が可能になります。
ここで、ETLと混同されやすい2つの概念を整理しておきます。ELTはExtract・Load・Transformの順で処理する方式で、変換前のデータをまずDWHへ格納し、DWH上で変換処理を行います。大量データをクラウドDWHで扱う場合に向いています。
ETL導入で確認すべきポイントとは?メリットや注意点、選定のポイントも解説
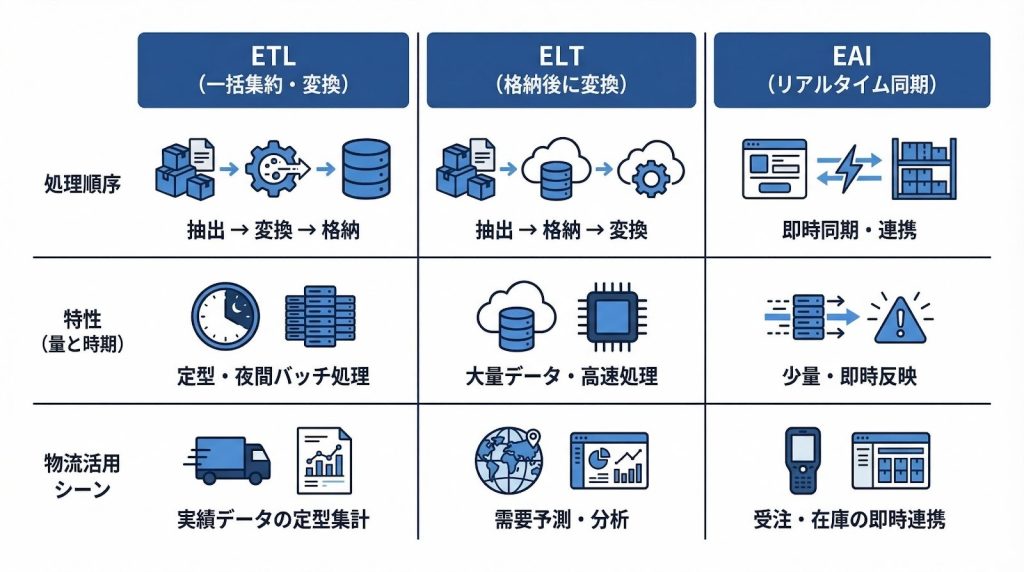
一方、EAI(Enterprise Application Integration:企業アプリケーション統合)は、複数の業務システム間でデータやプロセスをリアルタイムに連携させるアーキテクチャです。受注が入った瞬間に在庫システムへ即時反映するといった、イベント駆動型の連携に向きます。
近年はクラウド対応が進んだiPaaS(Integration Platform as a Service)として発展しており、ETLと組み合わせて使われるケースも増えています。ETLは大量データの一括集約・変換に強みがあり、夜間バッチによる全拠点データの集計といった物流業務の定型処理と相性が良い方式です。
物流業務でETLが使われる具体的な場面
ETLの仕組みが物流業務のどの場面で機能するかを理解することが、自社への適用を検討する際の出発点になります。
在庫管理・受発注・配送実績・入荷棚卸という主要な業務フローごとに、「連携前の課題」と「ETLによって何が変わるか」を整理します。
在庫データの一元管理:WMS・ERP間の自動連携
複数の倉庫を持つ企業では、拠点ごとにWMSが導入されており、それぞれの在庫データがERPと連携されていないケースが多く見られます。
この状態では、全拠点の在庫を把握するために各システムからデータを手動で取り出して集計する作業が必要になり、把握できるのは「昨日時点の在庫」にとどまります。
複数倉庫のWMSとERPをETLで自動連携することで、拠点をまたいだ在庫状況をリアルタイムに一元把握できるようになります。EC事業者であれば、欠品による機会損失や、過剰在庫による保管コストの増大を早期に検知して対処できるようになります。在庫の「見える化」は、補充発注のタイミング判断や販売計画の精度向上にも直接つながります。
受発注データの自動連携:手作業入力からの脱却
受注システムに入ったデータをERPへ手動で入力している現場では、入力ミスと処理工数の両方が課題になります。取引先が多いほど入力量は増え、繁忙期には処理が追いつかなくなるリスクもあります。
受注システムからERPへのデータ転送をETLで自動化することで、手入力ミスの排除と処理工数の削減を同時に実現できます。さらに、流通BMSや物流EDIに対応したETLツールを使えば、取引先ごとに異なるEDI仕様への個別対応工数を大幅に削減できます。
取引先が増えても、新しい接続設定を追加するだけで対応できる体制が整います。
配送実績・レポートの自動集約:TMS・ERPのデータ統合
TMSに蓄積される配送実績データ(配送コスト・積載率・遅延状況など)は、ERPや分析基盤と連携されていなければ活用できません。
手作業で集計・レポート化している場合、担当者の工数が毎月大きく取られるうえ、レポートが完成するころには状況が変わっているという問題も生じます。
夜間バッチでTMSの全拠点データをERPへ自動集約することで、翌朝には配送コスト・積載率・遅延状況を反映した経営ダッシュボードを参照できる状態になります。
より即時性が求められる場合は、ETLとCDC(Change Data Capture:データ変更検知)を組み合わせることで、データ更新のタイムラグをさらに短縮することも可能です。経営層が「昨日の全拠点の輸送状況」を朝一番に確認できる環境は、意思決定のスピードを大きく変えます。
入荷・棚卸データの集計自動化:現場データの活用
入荷検品や棚卸の結果データは、WMSに記録されていても集計・分析に活用されていないケースが多くあります。担当者がWMSからデータをエクスポートし、Excelで集計してレポートを作成するという作業が定期的に発生している現場も珍しくありません。
WMSの入荷検品・棚卸データをETLで自動集計することで、手作業による集計工数を削減しつつ在庫精度を向上できます。RFIDやバーコードスキャンで取得したデータをリアルタイムにWMSへ反映し、そのデータをETLで分析基盤へ連携する構成にすれば、現場の作業実績が即座に在庫管理や発注判断に活用できる状態になります。
物流業界でのETL導入事例:2社の課題と成果

実際に物流企業がデータ基盤の構築に取り組んだ事例を見ると、共通するパターンが浮かび上がります。分散していたデータを統合し、可視化できる状態にすることで、コスト削減や意思決定の高速化という具体的な成果につながっています。ここでは業態の異なる2社の事例を紹介します。
ロジスティード株式会社(物流業)
3PL(Third Party Logistics:物流業務の一括受託)事業者として多数の顧客のサプライチェーンを支えるロジスティード株式会社では、顧客ごと・システムごとにデータが分散管理されており、全体を横断した状況把握や分析が困難な状態でした。在庫の最適化や輸送コストの可視化が進まないことが、顧客への提供価値向上を妨げる課題となっていました。
この課題に対し、同社は顧客のサプライチェーン情報を統合・可視化・分析するための「デジタル事業基盤」を構築しました。各種システムからデータを収集・統合し、BIツール(Domo)を活用することで、経営層と現場が同じ情報をリアルタイムに共有できる仕組みを整備しています。
成果として、データ受領から分析結果の提供まで10人月かかっていたところが2人月(1/5の工数)に短縮されています。また、工場から卸までの在庫情報の可視化や、緊急輸送費の実態把握による輸送量の平準化など、データ活用による業務改善が進んでいます。
出典参照元:https://www.domo.com/jp/customers/logisteed-2023-1
F-LINE株式会社(物流業・食品物流)
食品物流を専門とするF-LINE株式会社では、従来のデータ基盤のパフォーマンス不足がデータ活用推進の障壁となっていました。加えて、データの分析・加工プロセスが属人化しており、担当者間での知見共有が進まない状況が続いていました。
解決策として、DWHにSnowflake、BIツールにTableauを導入し、誰もが使いやすいデータ分析・活用基盤を新規に構築しました。データ加工の定型化を進めることで、特定の担当者に依存していた分析作業を標準化し、属人化を解消しています。
DWHの新規構築により、データダウンロードにかかる時間が従来の約30分から約3分へと約10分の1に短縮されたことで、データを使う側の心理的なハードルが下がりました。その結果、事業本部会議などでデータに基づいた経営課題の分析が開始されるようになり、データ活用の文化が組織全体に広がっています。
ETLとELTの違いとは?処理順序における違い・メリット・選定基準を解説
出典参照元:https://www.hitachi-solutions.co.jp/snowflake/case01
物流業務に合ったETLツールを選ぶ4つの基準
ETLツールの選定で失敗しやすいのは、機能の豊富さだけで判断してしまうケースです。物流業務に特有の要件を軸に評価しないと、導入後に「使いこなせない」「個別開発が必要になった」という状況に陥ります。
リバースETLとは?DWHから業務ツールへデータを同期する仕組みと導入方法
ここでは、判断に迷いやすい4つの基準を整理します。
1. 物流システムとの接続アダプタの豊富さ
ETLツールを選ぶ際にまず確認すべきは、自社が使っているWMS・TMS・ERP・EDI・クラウドサービスへの接続アダプタが標準提供されているかどうかです。
接続アダプタが揃っていれば、設定作業だけで連携を開始できます。対応していない場合は個別の接続プログラムを開発する必要があり、導入コストと期間が大幅に増大します。
特に注意が必要なのは、現在使っているシステムだけでなく、今後導入を検討しているシステムへの対応状況も確認することです。物流DXの進展に伴って連携対象が増えることを想定し、アダプタのラインナップが継続的に拡充されているベンダーを選ぶことが、中長期的な運用コストを抑えることにつながります。
2. ノーコード/ローコードでの操作性
物流現場の業務担当者がETLツールを自律的に運用できるかどうかは、導入後の定着を左右する重要な要素です。プログラミングスキルが必要なツールでは、設定変更のたびにIT部門や外部ベンダーへの依頼が発生し、結果として「IT担当者への依存」という新たな属人化を生み出します。
GUIで直感的に操作できるノーコード対応ツールであれば、業務部門が自律的に設定・運用できるため、こうしたリスクを低減できます。
単なるデータ転送にとどまらず、統合データをAIで分析・可視化まで行いたい場合は、ETLに加えてDWH(データウェアハウス)やBIツールを組み合わせたデータ基盤の構築も選択肢として検討する価値があります。
顧客接点データの統合・活用まで視野に入れる場合は、CDP(Customer Data Platform:顧客データ基盤)の活用も有効です。
3. 物流特有のデータ形式への対応力
流通BMS・物流EDI・RFIDデータといった物流業界特有のデータ形式に、ツールが標準対応しているかどうかは見落としやすいポイントです。汎用的なETLツールの中には、こうした形式への対応が薄く、実際に使おうとするとカスタム開発が必要になるケースがあります。
標準対応がないツールを選んでしまうと、取引先とのデータ交換を自動化するたびに個別の変換ロジックを開発する必要が生じます。
取引先の数が多い物流企業ほど、この問題は深刻になります。導入前のPoC(Proof of Concept:概念実証)段階で、自社が扱う主要なデータ形式への対応状況を実際に確認することを強くお勧めします。
4. スモールスタートできる価格体系と拡張性
ETLツールの導入で失敗しやすいもう一つのパターンは、最初から全社・全システムへの展開を前提とした大規模導入です。一部業務・一部拠点から試験導入できるサブスクリプションや従量課金モデルのツールを選ぶことで、初期投資を抑えながら導入効果を検証できます。
同時に、将来的な拡張性も確認しておく必要があります。連携するシステムが増えたとき、データ量が増大したときに、追加コストや設定変更の工数がどの程度発生するかを事前に把握しておくことが重要です。スモールスタートで効果を確認しながら段階的に展開できる体制が、物流DXを着実に進めるうえでの現実的なアプローチです。
まとめ:物流データ連携の自動化にETLを活用するために
この記事では、物流現場でデータ連携が手作業に頼り続ける構造的な背景から始まり、ETLの仕組み、具体的な活用シーン、実際の導入事例、ツール選定の基準までを整理してきました。
自社の優先課題が手作業の削減なのか、属人化の解消なのか、それともリアルタイムな在庫・配送状況の把握なのかによって、最初に連携すべきシステムと選ぶべきツールの要件は変わります。
データ連携の自動化を実現したうえで、その先の分析・可視化まで見据えた基盤を選ぶことが、物流DXの中長期的な成果につながります。まずは自社の「最も痛い課題」を一つ特定し、そこから製品比較やベンダーへの問い合わせを始めることをお勧めします。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。













