ETLとELTの違いとは?処理順序における違い・メリット・選定基準を解説

ETL(Extract, Transform, Load)とELT(Extract, Load, Transform)は、データを抽出・変換・格納する際の処理順序が異なるデータ統合手法です。従来のオンプレミス環境ではETLが主流でしたが、クラウドDWHの普及に伴い、ELTが注目を集めています。しかし、「どちらを選ぶべきか」「自社のデータ基盤にはどちらが適しているのか」と悩む担当者も少なくありません。
本記事では、ETLとELTの定義と処理順序の違いを明確にしたうえで、それぞれのメリット・デメリットを比較します。さらに、クラウドDWH時代にELTが推奨される技術的背景や、自社に最適な方式を選ぶための判断基準、代表的なツールと実装アプローチまで、実務に役立つ情報を体系的に解説します。
リバースETL(Reverse ETL)は、DWHに蓄積・変換されたデータを、CRM・MA・広告プラットフォームなどの業務システムへ逆方向に同期する手法です。ETL/ELTがデータを「集める・整える」プロセスであるのに対し、リバースETLは「活用する」プロセスを担います。
データ基盤の設計・刷新を検討している方は、ぜひ参考にしてください。
ETLとELTの定義と処理順序の違い
ETLとELTは、データを「抽出(Extract)」「変換(Transform)」「ロード(Load)」する3つのステップで構成される点では共通していますが、変換を行うタイミングと場所が異なります。
この章では、それぞれの基本定義と処理順序の違い、そしてその違いがもたらす本質的な差について順に見ていきます。
ETL(Extract, Transform, Load)とは
ETLは、データソースから抽出したデータを、データウェアハウス(DWH)に格納する前に専用サーバーで変換し、必要なデータ量に絞ってからロードする手法です。
オンプレミス環境でストレージコストが高価だった時代には、DWHに格納するデータ量を最小限に抑えることが重要であり、ETLはその要件に最適化されたアプローチでした。
具体的には、抽出したデータをETLツールや専用サーバー上で集計・結合・フィルタリングし、分析に必要な形に整えてからDWHへ投入します。これにより、DWH側のストレージ負担を軽減し、ロード時間を短縮できます。
【関連記事】ETLツールとは?選び方の6つの比較軸と主要5製品を紹介
ELT(Extract, Load, Transform)とは
ELTは、データソースから抽出した生データをまずDWHへロードし、DWH内の高性能な計算エンジンを利用して必要な時に変換を行う手法です。
クラウドDWHの登場により、ストレージコストが大幅に低下し、かつ並列処理による高速な変換が可能になったことで、ELTはモダンなデータ基盤の標準的なアプローチとなりました。
ELTでは、生データをそのまま保持するため、後から変換ロジックを変更して再集計することが容易です。また、非構造化データや半構造化データ(JSON等)にも柔軟に対応できる点が特徴です。
【関連記事】データ統合ツール(ELT)おすすめ比較16選!選び方も解説
処理順序の違いがもたらす本質的な差
ETLとELTの最も大きな違いは、変換を行う場所とタイミングです。ETLでは変換後のデータのみをDWHに格納するため、元の生データは失われます。一方、ELTでは生データを保持するため、分析要件の変化に応じて変換ロジックを柔軟に変更できます。
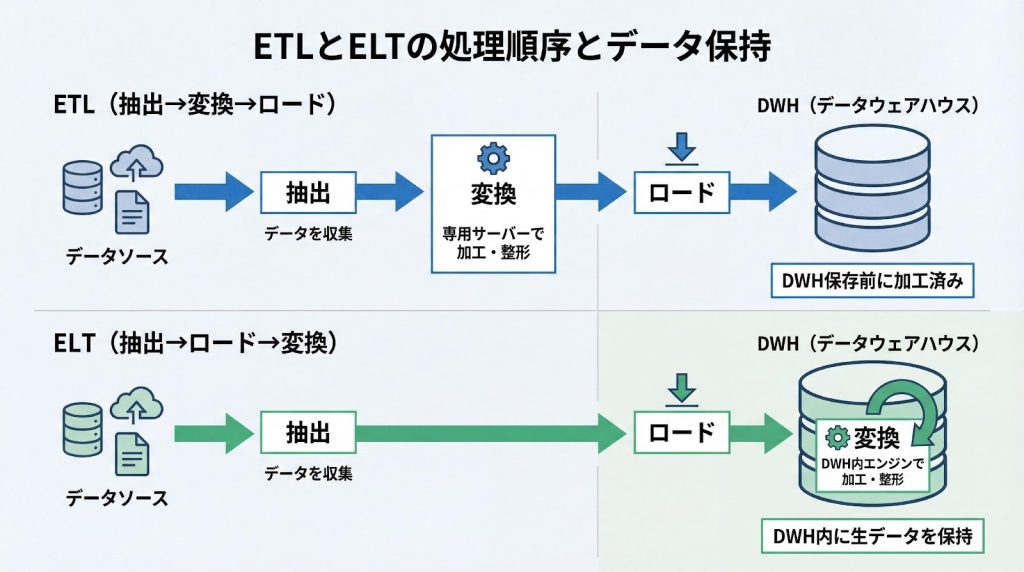
この違いは、データの保持形態や分析の柔軟性に直結します。例えば、新しい分析軸が必要になった場合、ETLでは元データを再抽出して変換し直す必要がありますが、ELTでは既にDWHにある生データに対して新しい変換ロジックを適用するだけで済みます。
また、変換処理を行う計算リソースも異なります。ETLでは専用の変換サーバーが必要ですが、ELTではDWH自体の計算能力を活用するため、インフラ構成がシンプルになります。
ETLとELTのメリット・デメリットを比較

ETLとELTは、それぞれ異なる強みと弱みを持ちます。この章では、処理時間、コスト、柔軟性、データ品質、スキルの5つの軸で両者を比較し、自社の要件に照らし合わせて最適な方式を評価するための判断材料を提示します。
ETL(先に変換)のメリットとデメリット
ETLの最大のメリットは、DWHへのロード前にデータをクレンジング・整形できる点です。これにより、DWHに格納するデータ量を削減し、ロード時間を短縮できます。また、個人情報(PII)の秘匿化や匿名化を事前に行えるため、厳格なセキュリティ要件やコンプライアンス要件に対応しやすいという利点もあります。
一方で、ETLには専用の変換サーバーやETLツールが必要であり、初期構築コストや運用負荷が高くなる傾向があります。また、変換ロジックが固定化されるため、分析要件の変化に対する柔軟性が低く、新しい分析軸を追加する際には元データの再抽出と再変換が必要になる場合があります。
ELT(後に変換)のメリットとデメリット
ELTのメリットは、生データをそのまま保持するため、後から変換ロジックを柔軟に変更できる点です。変換を待たずにデータをロードするため、データ投入が高速であり、スキーマ変更にも柔軟に対応できます。また、クラウドDWHの強力な計算リソースを活用できるため、大量データの並列処理が効率的です。
一方で、ELTではDWH内でSQL等を用いて変換を行うため、一定のSQLスキルやデータモデリングの知識が必要です。また、生データをそのまま格納するため、セキュリティ要件が厳しい場合には事前の匿名化処理が別途必要になる場合があります。
| 評価軸 | ETL | ELT |
| 処理時間 | 変換後のデータのみをロードするため、ロード時間は短い。ただし変換処理自体に時間がかかる場合がある。 | 生データをそのままロードするため、データ投入は高速。変換は必要なタイミングで実施。 |
| コスト | 専用の変換サーバーやETLツールのライセンスが必要。DWHのストレージコストは抑えられる。 | クラウドDWHのストレージと計算リソースを利用。初期投資は低いが、データ量に応じてストレージコストが増加。 |
| 柔軟性 | 変換ロジックが固定化されるため、分析要件の変化に対応しにくい。 | 生データを保持するため、後から変換ロジックを変更して再集計が容易。 |
| データ品質 | ロード前にクレンジング・検証を行うため、DWH内のデータ品質が高い。 | 生データを保持するため、変換時の品質管理が重要。dbt等のツールでテストを自動化可能。 |
| 必要スキル | ETLツールの操作スキル、GUI中心の開発に慣れたエンジニア向け。 | SQLやデータモデリングのスキル、コードベースの開発に慣れたエンジニア向け。 |
もし、自社でのパイプライン構築やSQLによるデータ変換が技術的に難しい場合は、ETL/ELTの機能を内包したCDP(Customer Data Platform)の導入も一つの手です。GENIEE CDPであれば、ノーコードでデータの統合から分析までを行えるため、エンジニアリソースに依存せずにデータ活用基盤を構築できます。
クラウドDWH時代に、なぜELTが推奨されるのか?
現代のデータ基盤設計でELTが主流となっている背景には、クラウドDWHのアーキテクチャとコスト構造の変化があります。
この章では、計算リソースとストレージの分離、ストレージコストの低下とMPP処理の高速化、そしてモダンデータスタックの潮流という3つの観点から、ELTの優位性を紐解きます。
「必要な時だけ起動する」クラウドDWHにより、ELTの実用性が向上した
SnowflakeやBigQueryなどのクラウドDWHは、計算リソース(コンピュート)とストレージを分離してスケールできる設計を採用しています。これにより、必要なときだけ計算リソースを起動し、使用しない時間帯はコストをゼロに抑えることが可能です。
例えば、Snowflakeでは「仮想ウェアハウス」と呼ばれる計算クラスタを、クエリ実行時にのみ起動できます。BigQueryでも、クエリごとに必要なリソースが自動的に割り当てられ、処理が完了すれば即座に解放されます。このアーキテクチャにより、バッチ変換時のコスト効率が極めて高くなり、ELTの実用性が大幅に向上しました。
ストレージコストの低下・MPP処理の高速化により、生データをすべて保存することが現実的になった
クラウドストレージの単価は年々低下しており、生データをすべて保存することが現実的になりました。かつてはストレージコストの制約からETLで事前にデータを絞り込む必要がありましたが、現在ではその制約が大幅に緩和されています。
同時に、クラウドDWHは超並列処理(MPP: Massively Parallel Processing)により、テラバイト級のデータ変換処理も数分で完了させることが可能です。複数のノードが並列にクエリを実行するため、従来のオンプレミス環境では数時間かかっていた処理が、クラウド環境では劇的に短縮されます。
コスト最適化とモダンデータスタックの潮流
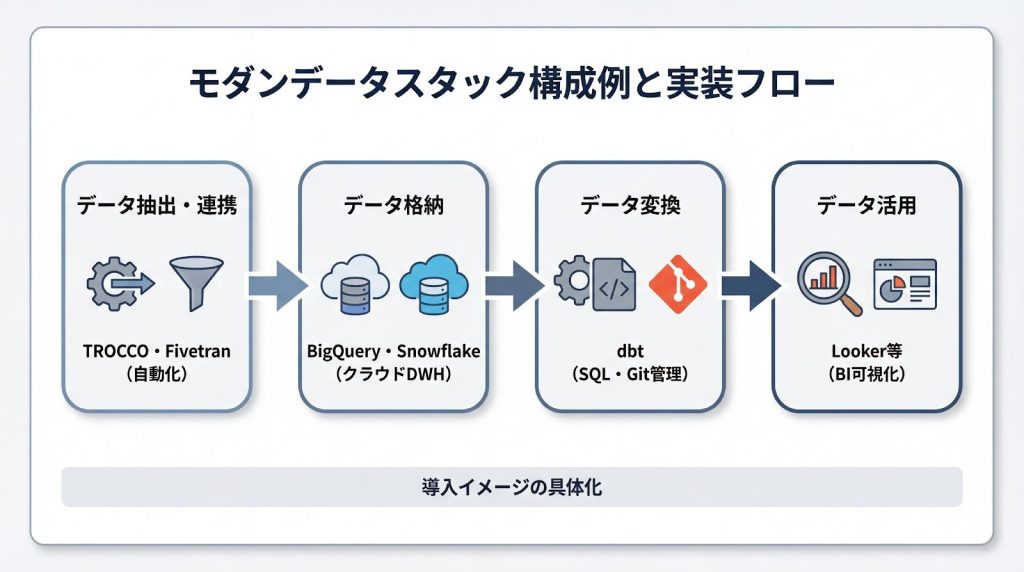
dbtやFivetranに代表されるモダンデータスタックのツール群は、抽出・ロード・変換を分業化し、それぞれの工程を専門ツールで効率化する設計思想に基づいています。これにより、保守性の高いパイプライン構築が容易になりました。
特にdbtは、SQLでデータ変換ロジックを記述し、テストやドキュメント生成を自動化することで、データ品質とメンテナンス性を大幅に向上させています。また、GitHubと連携してバージョン管理やコードレビューを行うことで、ソフトウェア開発と同様の品質管理をデータパイプラインにも適用できます。
これらによって、まずデータを入れておき、あとから変換するELTの実用性がクラウドDWH時代では高まった背景があります。
ETL/ELT選定の判断基準とチェックリスト

自社に最適なデータ統合方式を選ぶには、データ量、スキーマ、スキル、セキュリティ、連携先の5つの観点から総合的に評価する必要があります。この章では、それぞれの判断軸について具体的なチェックリストを提示し、最適な方式を導き出すための指針を示します。
判断軸①:データ量とリアルタイム性
扱うデータ規模と、分析結果を得るまでの許容時間は、ETL/ELT選定の重要な判断軸です。データ量が継続的に増大する環境や、ニアリアルタイムでのデータ反映を求める場合は、ELTが第一候補となります。
具体的には、日次で数百GB以上のデータを処理する場合や、データ投入から分析までの時間を数分以内に抑えたい場合は、クラウドDWHの並列処理能力を活かせるELTが適しています。一方、データ量が比較的少なく、バッチ処理で十分な場合は、ETLでも対応可能です。
判断軸②:スキーマ柔軟性とデータ形式
JSON等の半構造化データや、頻繁な仕様変更への対応力も重要な評価軸です。SaaSのAPI更新などでデータ形式が頻繁に変わる場合、生データを保持するELTの方が修正コストが低くなります。
ETLでは、スキーマ変更のたびに変換ロジックを修正し、過去データを再処理する必要があります。一方、ELTでは生データが保持されているため、変換ロジックのみを修正すれば過去データにも新しいロジックを適用できます。
判断軸③:エンジニアスキルセットと組織体制
現場のエンジニアがSQLに強いか、既存のETLツールに習熟しているかを確認することも重要です。SQLやデータモデリングのスキルが高いチームであれば、ELTとdbtの組み合わせが適しています。特に、ソフトウェア開発に近い手法(Git管理、コードレビュー等)をデータ変換に導入したい場合は、ELTが有利です。
一方、SQLスキルを持つエンジニアが不足している場合でも、諦める必要はありません。AIによる自然言語分析機能を備えたGENIEE CDPなら、専門的なクエリを書くことなく、チャット感覚で高度なデータ分析を実行可能です。
判断軸④:コンプライアンス・セキュリティ要件
個人情報保護法やGDPRへの対応、データの匿名化が必要なタイミングも考慮する必要があります。社外クラウドへ生データをアップロードすることがポリシー上禁止されている場合は、ETLによる事前加工が必要です。
ETLでは、DWHへのロード前に個人情報(PII)の秘匿化や匿名化を行えるため、厳格なセキュリティ要件に適しています。一方、ELTでも、ロード後に匿名化処理を行うことは可能ですが、一時的に生データがDWHに格納される点に注意が必要です。
判断軸⑤:既存システムとの連携と将来拡張性
オンプレミスのレガシーシステムや、最新のSaaS群との接続親和性も評価軸となります。複数のマーケティングSaaSを統合し、即座に施策へ活かしたい場合は、APIコネクタが豊富なELTツールとの連携が効率的です。
特にマーケティング施策への即時反映を重視する場合、汎用的なETLツールよりも、マーケティングツールとの標準連携機能が充実しているGENIEE CDPを選ぶことで、開発工数を大幅に削減し、スピーディーな施策実行が可能になります。
ELTパイプラインの代表的ツールと実装アプローチ
ELTパイプラインを構築するには、データの抽出・ロード、変換、そしてエンタープライズ向けのガバナンス管理など、各工程に適したツールを組み合わせる必要があります。この章では、Fivetran、dbt、Informatica、Azure Data Factoryなど、市場で高く評価されているツールの特徴を整理し、実装のイメージを具体化します。
データ抽出・ロードツール:Fivetran、Airbyte、Stitch
ELTの「E(Extract)」と「L(Load)」を自動化するツールとして、Fivetran、Airbyte、Stitchなどが広く利用されています。これらのツールは、SaaSやデータベースなど多様なデータソースに対応したコネクタを提供し、APIの仕様変更を自動で吸収するため、運用負荷を大幅に削減できます。
Fivetranは、700以上のコネクタを持ち、設定後は自動的にデータを同期し続けるフルマネージドのSaaS型ツールです。Airbyteは、600以上のプリビルトコネクタを持つオープンソースベースのELTプラットフォームです。セルフホスト版とクラウド版の両方を提供しており、AIアシスト型のカスタムコネクタ開発も容易なため、独自データソースへの対応が必要なチームに適しています。。Stitchは(現Qlik傘下)、シンプルな設定と無料プランが特徴で、データ量が少なくコストを抑えたいスタートアップや小規模プロジェクトに適しています。ただし、エンタープライズ用途ではコネクタ数や信頼性の面でFivetranが優位です。
データ変換ツール:dbt(data build tool)
ELTの「T(Transform)」を担うdbtは、SQLでデータ変換ロジックを記述し、テストやドキュメント生成を自動化することでデータ品質を劇的に高められるツールです。dbtは、データエンジニアの間でデファクトスタンダードとなっており、多くの企業が採用しています。
dbtの最大の特徴は、SQLファイルをGitで管理し、ソフトウェア開発と同様のワークフロー(プルリクエスト、コードレビュー、CI/CD)をデータ変換に適用できる点です。
2025年以降はdbt Fusion Engineによる高速処理、AI支援によるモデル構築、dbt Semantic Layerによるメトリクス定義の一元管理など、変換ツールを超えたデータプラットフォームへと進化しています。
エンタープライズ向けツール:Informatica、Azure Data Factory
大規模組織でのガバナンスや、既存のクラウドエコシステムとの親和性を重視する場合は、Informatica Intelligent Data Management Cloud (IDMC)やAzure Data Factoryが選択肢となります。
Informatica IDMCは、エンタープライズレベルのデータ品質管理とノーコード開発を両立するプラットフォームです。データカタログやデータリネージ(由来)の可視化機能も充実しており、大規模なデータガバナンスが求められる環境に適しています。
Azure Data Factoryは、GUIでデータパイプラインを視覚的に構築・管理できるMicrosoft Azureのサービスです。Azure環境との統合が容易で、既にAzureを利用している企業にとっては導入ハードルが低い選択肢です。
また、こうしたモダンデータスタックの一部として、あるいはデータ活用の統合基盤としてGENIEE CDPを組み込むケースも増えています。データの収集・統合から、AIを活用した顧客理解、そしてマーケティングアクションまでを一気通貫で支援するソリューションです。
ETLとELTの違いと選び方まとめ
本記事では、ETLとELTの定義と処理順序の違い、それぞれのメリット・デメリット、クラウドDWH時代にELTが推奨される技術的背景、そして自社に最適な方式を選ぶための判断基準と代表的なツールについて解説しました。
ETLとELTの決定的な違いは、データを「変換」するタイミングがロードの前か後かにあります。ETLは、DWHへのロード前にデータをクレンジング・整形し、必要なデータ量に絞ってから格納する手法です。一方、ELTは、生データをまずDWHへロードし、DWH内の高性能な計算エンジンを利用して必要な時に変換を行います。
ETL/ELTの構築は手段であり、真の目的はデータに基づく意思決定の迅速化です。もしインフラ構築の複雑さや専門人材の不足がボトルネックになっているなら、GENIEE CDPのような統合プラットフォームの活用も検討してみてください。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。