







Snowflake ETLとは?ELTとの違い・ツール選定・コスト対策を解説

Snowflakeへのデータ取り込みを検討し始めると、「ETLとELTのどちらを選ぶべきか」「Fivetran・Matillion・AWS Glueなど複数のツールの違いが整理できない」「高頻度書き込みでコストが膨らんだ」といった悩みに直面することがあります。Snowflake ETLの構成は選択肢が多い分、判断基準が曖昧なまま進めると後から設計を見直す羽目になりかねません。
ETLとDWHとは?役割の違いからBIツールとの連携構造まで解説
Snowflake環境では、ロード後にSnowflake内部で変換を行うELT方式が、基本的な推奨アプローチです。ただし、ソース側でのクレンジングが必須な場合や、オンプレミスのレガシーシステムと接続する場合は、ETL的な前処理を組み合わせるハイブリッド構成が現実的な選択肢になります。
この記事では、取り込み方式の選択(バルクロード・Snowpipe・ストリーミング)、ツール選定の判断軸など、実務で判断が必要になる論点を順に整理しています。
SnowflakeにおけるETLとELTの違い
ETLとELTは「変換をどこで行うか」という点で根本的に異なります。Snowflakeのアーキテクチャ特性を踏まえると、多くのケースでELTが有利ですが、ソース側の事情によってはETL的な前処理が必要になる場面もあります。
まず両者の処理フローの違いを整理し、Snowflake環境でELTが推奨される技術的な根拠を確認しましょう。
ETLとELTの処理フローの違い
ETL(Extract・Transform・Load)は、ソースからデータを抽出した後、外部のサーバーやツール上で変換処理を完了させてからロード先へ格納する方式です。
ロード先のスキーマに合わせたデータのみが格納されるため、DWH側には整形済みのデータだけが入ります。変換ロジックはETLツール側で管理されるため、DWH内部の処理は比較的シンプルに保てる反面、変換仕様を変更するたびにETLツール側の設定を修正する必要があります。
ETLとELTの違いとは?処理順序における違い・メリット・選定基準を解説
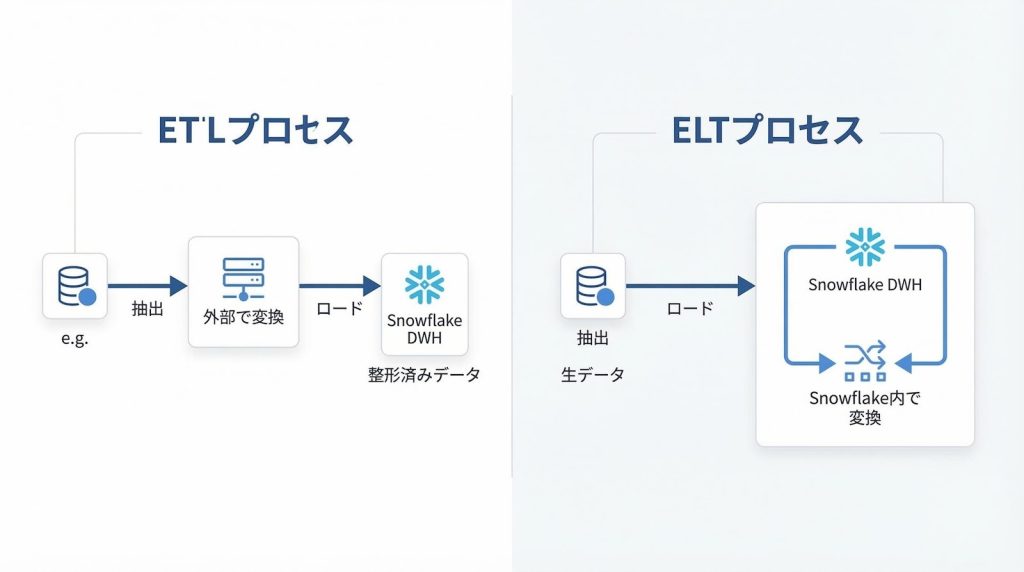
ELT(Extract・Load・Transform)は、生データをまずSnowflakeへロードし、変換処理をSnowflake内部のSQLやツールで行う方式です。変換ロジックをSnowflake側で管理するため、仕様変更への対応が柔軟で、生データを保持したまま変換定義だけを更新できます。
| 比較項目 | ETL | ELT |
| 変換場所 | 外部サーバー・ツール上 | Snowflake内部 |
| 処理順序 | 抽出 → 変換 → ロード | 抽出 → ロード → 変換 |
| ロード後のデータ | 変換済みデータのみ | 生データ(raw)を保持 |
| 変換仕様の変更 | ETLツール側を修正 | Snowflake側のSQLを修正 |
| 向いているケース | レガシー接続・厳格なクレンジング要件 | 大規模変換・柔軟な仕様変更 |
Snowflake環境でELTが推奨される理由
Snowflakeがコンピュートとストレージを分離した仮想ウェアハウス構成を採用していることが、ELTとの高い親和性の技術的な根拠です。
仮想ウェアハウスは必要なタイミングでスケールアップ・スケールアウトできるため、ロード後の大規模な変換処理をSnowflake内で効率的に実行できます。外部サーバーに変換処理用のリソースを別途用意する必要がなく、変換コンピュートをSnowflakeに集約できる点がコスト・管理の両面で有利に働きます。
一方、すべてのケースでELTが最適というわけではありません。ソース側のデータ品質が低く、ロード前に不正値の除去や型変換が必要な場合、あるいはロード前に個人情報のマスキングが求められる場合は、ETL的な前処理をSnowflakeへのロード前に挟むハイブリッド構成が現実的な選択肢になります。
判断の基本軸は「変換処理をSnowflakeのコンピュートに任せられるか」「ソース側でのクレンジングが必須かどうか」の2点です。この2点を確認することで、ELT単独・ETL前処理との併用・ETL主体のいずれが自社の要件に合うかが絞り込めます。
Snowflakeへのデータ取り込み方式の種類と使い分け

ETL/ELTの方針が決まったら、次に考えるのはSnowflakeへの具体的な取り込み方式です。
バルクロード・Snowpipe・ストリーミング取り込みの3方式はそれぞれ仕組みが異なり、「データ量」「更新頻度」「リアルタイム性の要件」「コスト効率」の4軸で使い分けを判断するのが基本です。増分ロードやCDCの概念も含めて整理します。
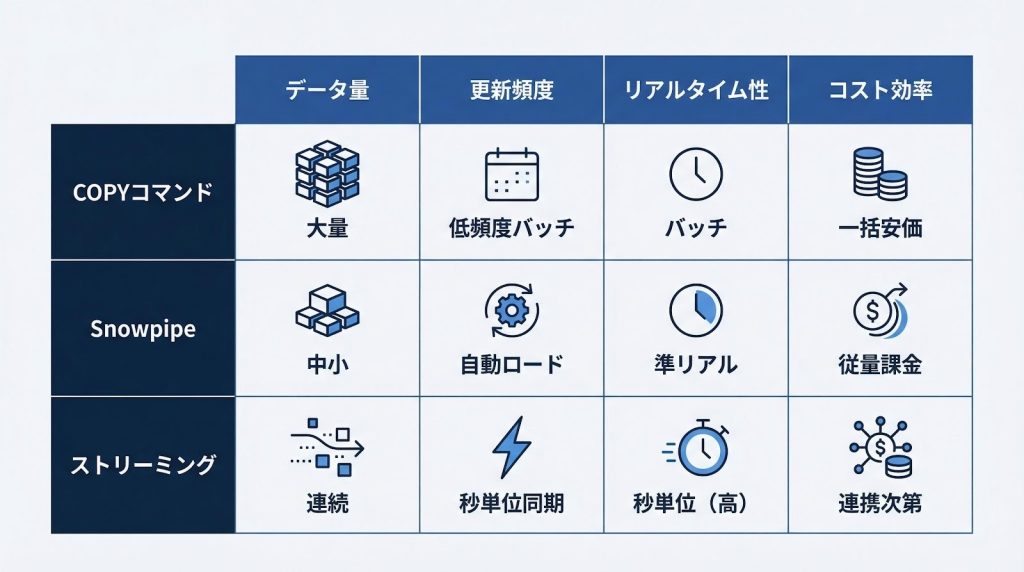
バルクロード(COPYコマンド):大量データの一括取り込み
COPYコマンドは、ステージング領域(内部ステージまたはS3・Azure Blob・GCSなどの外部ストレージ)にファイルを配置してからSnowflakeへ一括ロードする方式です。大量データの定期バッチ処理や、過去データの履歴移行に適しています。
ファイルの分割方法がスループットに影響します。単一の大容量ファイルでロードするよりも、数十MB〜数百MB単位に分割して並列ロードする方がパフォーマンスが向上するとされており、ファイル分割はバルクロードを設計する際の基本的な考慮点です。
向いているユースケースは、日次・週次などの定期バッチ処理、初期データ移行(フルロード)、更新頻度が低く一度に大量のレコードを処理するケースです。逆に、数分おきにデータが発生するような高頻度の取り込みには向きません。ウェアハウスを起動したままにする時間が長くなり、コストが積み上がりやすいためです。
Snowpipe:ファイル到着時の自動継続取り込み
Snowpipeは、ファイルがステージに到着したタイミングで自動的にロードをトリガーするサーバーレスサービスです。ユーザーが仮想ウェアハウスを常時起動しておく必要がなく、Snowflake側がコンピュートリソースを管理します。
コスト面での特徴は、サーバーレス課金(取り込みデータ量ベース)である点です。2025年12月の価格改定により、Snowpipeはファイル取り込み・ストリーミングを問わず、インジェストされたデータ1GBあたり0.0037クレジットという統一された料金体系になりました。高頻度の小規模ファイル取り込みでは、ユーザー管理ウェアハウスを常時起動するよりも低コストになるケースがあります。ただし、大量データを一括処理する場合はCOPYコマンドの方が有利になることもあるため、更新頻度とファイルサイズの組み合わせで使い分けを判断してください。
※執筆時点での情報を元に記載しています。最新情報は公式サイトをご参照下さい。
SaaSツールのイベントデータや、数分〜数十分単位での準リアルタイム連携に向いています。ファイルが生成されるたびに自動でロードが走るため、スケジュール管理の手間を省けるのも実運用上のメリットです。
ストリーミング取り込みと増分ロード:リアルタイム・差分同期の選択肢
秒〜分単位のリアルタイム性が求められる場合は、Kafka Connector for Snowflakeを使ったストリーミング取り込みが選択肢になります。IoTデバイスのセンサーデータやアプリケーションログのように、継続的に大量のイベントが発生するユースケースに対応できます。
一方、リアルタイム性は不要だがフルロードのコストと処理時間を削減したい場合は、増分ロード(差分同期)の導入を検討してください。増分ロードには大きく2つのアプローチがあります。
- タイムスタンプベースの差分抽出:更新日時カラムを基準に前回取得以降のレコードのみを抽出する方法
- CDC(変更データキャプチャ):ソースDBのトランザクションログを読み取り、INSERT・UPDATE・DELETEの変更差分のみを取得する方法
CDCはソースDBへの負荷が低く、削除レコードの追跡も可能なため、データ量が多い・更新頻度が高い・ソース側がフルエクスポートに対応していないケースで特に有効です。フルロードと比較してSnowflakeへの転送データ量と処理負荷を大幅に削減できます。
Snowflake対応ETL/ELTツールの比較と選定基準
取り込み方式が決まったら、それを実現するツールの選定に入ります。
Snowflakeと連携可能なETL/ELTツールは多岐にわたりますが、①データソースの種類と数、②変換処理の複雑さ、③運用チームのスキルレベル(ノーコード〜コード)、④コスト体系の4軸で絞り込むのが基本的なアプローチです。
以下では、カテゴリ別に各ツールの得意領域と向き不向きを整理します。
ELT特化・ノーコード型:Fivetran・Airbyte
多様なSaaSデータソースをSnowflakeへ素早く集約したい場合、ELT特化型のコネクタサービスが有力な選択肢です。変換処理よりもデータの収集・ロードに特化しており、エンジニアリソースが限られているチームでも導入しやすい設計になっています。
Fivetranは2024年時点で既に700以上のコネクタを持ち、ソース側のスキーマ変更に自動追随する機能を備えています。Salesforce・HubSpot・Google Analyticsなど多様なSaaSソースを短期間でSnowflakeに接続したい場合に適しており、スキーマ変更への追随を手動で管理する手間を省けます。従量課金制のため、データ量が増えるにつれてコストが上昇する点は事前に試算しておく必要があります。
※最新情報は公式サイトをご参照ください。
Airbyteはオープンソース版と商用クラウド版の2形態があります。オープンソース版は自社ホスティングによるコスト抑制が可能で、クラウド版はマネージドサービスとして運用負荷を下げられます。コネクタ数はFivetranより少ない場合がありますが、カスタムコネクタの開発が可能なため、独自システムとの接続が必要なケースでも対応できます。
変換処理特化型:Matillion・dbt Cloud
変換ロジックが複雑で、データモデリングやビジネスルールの適用に重点を置く場合は、変換処理に特化したツールが適しています。
ロード後の変換をSnowflake内で実行するELTアーキテクチャと組み合わせることで、外部サーバーのコストを抑えながら高度な変換パイプラインを構築できます。
MatillionはGUIで変換パイプラインを設計でき、変換処理をSnowflakeのコンピュートリソース上で実行するPush-down ELTを採用しています。SQLに習熟していないチームでも視覚的にパイプラインを組み立てられる点が特徴で、複雑な変換ロジックをノーコード〜ローコードで管理したい場合に向いています。
dbt CloudはSQLによるデータモデリング・自動テスト・Git連携によるバージョン管理を提供します。なお、2025年11月より「dbt Projects on Snowflake」が一般提供開始され、Snowflakeのネイティブ環境(Snowsight)上でdbt Coreプロジェクトを直接管理・実行できるようになりました。dbt Cloudを別途契約せずにSnowflake内でdbtを活用したい場合の選択肢として把握しておく価値があります。データエンジニアチームがコードベースで変換ロジックを管理し、テストとドキュメントをパイプラインに組み込みたい場合に適しています。後述するデータ品質チェックとの親和性も高く、dbt testを活用した品質管理が実装しやすい構成です。
クラウドネイティブ・エンタープライズ型:AWS Glue・Azure Data Factory・Talend Cloud
既存のクラウド環境との統合を重視する場合や、オンプレミスとのハイブリッド接続・エンタープライズガバナンスが求められる場合は、クラウドネイティブサービスやエンタープライズ向けツールが候補になります。
AWS GlueはサーバーレスでDPU時間ベースの従量課金を採用しており、S3などAWSエコシステムとの連携が多い環境でSnowflakeへのETL処理を構築する場合に有力な選択肢です。Glue Data Catalogとの統合によるメタデータ管理も強みのひとつです。
Azure Data FactoryはAzure環境との統合に強く、ビジュアルなパイプライン設計ツールを備えています。Azure Blob StorageやAzure SQL Databaseとの連携が多い環境でSnowflakeへのデータ統合を行う場合に適しています。
Talend Cloud(旧Talend Cloud)は1,000以上のコネクタとデータ品質・ガバナンス機能を備え、オンプレミスからハイブリッド環境まで対応しています。エンタープライズのガバナンス要件が厳しい場合や、レガシーシステムとの接続が多い環境に適しています。
ETL運用ではウェアハウスコストの増加に注意

ツールを選定してパイプラインを構築した後、実運用で最初に直面しやすいのがウェアハウスコストの想定外の増大です。
Snowflakeの課金構造を理解せずにETLツールのスケジュールを設定すると、処理量に対してコストが不釣り合いに膨らむことがあります。仕組みを把握した上で、設計段階から対策を組み込むことが重要です。
高頻度書き込みがコストを増大させる仕組み
Snowflakeの仮想ウェアハウスは、ウェアハウスが起動している時間に対してクレジットが消費されます。処理が完了してもウェアハウスはすぐには停止せず、自動停止設定の待機時間が経過するまで起動状態が続きます。
問題が起きやすいのは、ETLツールで高頻度スケジュール(例:毎分・5分おきの書き込み)を設定した場合です。短い間隔で書き込みが発生し続けると、ウェアハウスが自動停止するタイミングが来ないまま常時起動状態になります。
実際の処理時間は短くても、ウェアハウスが起動している時間全体に対してクレジットが消費されるため、処理量に対してコストが大きく膨らむパターンが生まれます。
コスト最適化のための設計・設定の見直しポイント
コスト増大を防ぐための対策は、大きく4つの観点から整理できます。
1. 自動停止時間の設定最適化
自動停止時間はユースケースに応じて設定を調整することが基本です。インタラクティブなクエリ用途では、ユーザーが次のクエリを実行するまでの待機時間を考慮して短めに設定します。
バッチ処理専用のウェアハウスであれば、処理完了後に即停止する設定が無駄なクレジット消費を防ぎます。用途別にウェアハウスを分けることで、それぞれに適した自動停止設定を適用しやすくなります。
2. バッチ処理への集約
高頻度スケジュールを見直し、書き込みをまとめてバッチ処理に集約することで、ウェアハウスの起動回数と起動時間を削減できます。
許容できるデータの鮮度(レイテンシ)を確認した上で、スケジュール間隔を広げられないかを検討してください。
3. Snowpipeへの切り替え判断
書き込み頻度を下げられない場合は、ユーザー管理ウェアハウスからSnowpipeへの切り替えを検討します。
取り込みデータ量・頻度・許容レイテンシの3点でコスト試算を行い、どちらが有利かを確認した上で判断してください。
4. ウェアハウスサイズの適正化
ウェアハウスサイズ(XS〜4XL)は処理内容に対して適切なサイズを選ぶことが重要です。過大なサイズを常時起動するよりも、小さいサイズで処理時間が多少長くなる方がトータルコストが低くなるケースがあります。
同時実行クエリが多い場合はマルチクラスタリングの活用も選択肢になりますが、常時有効化するとコストが増えるため、ピーク時のみ有効にする設定が基本的な考え方です。
Snowflake ETL/ELTパイプライン構築のベストプラクティス
コスト管理と並んで重要なのが、パイプライン自体の設計品質です。データレイヤーの構造・増分ロードの実装・品質チェックの組み込みという3点を設計段階から押さえておくことで、後から大きな修正が必要になるリスクを減らせます。
また、分析結果を業務システムへ戻すリバースETLも、データ活用の幅を広げる選択肢として把握しておく価値があります。
ステージング層の設計と増分ロードの実装
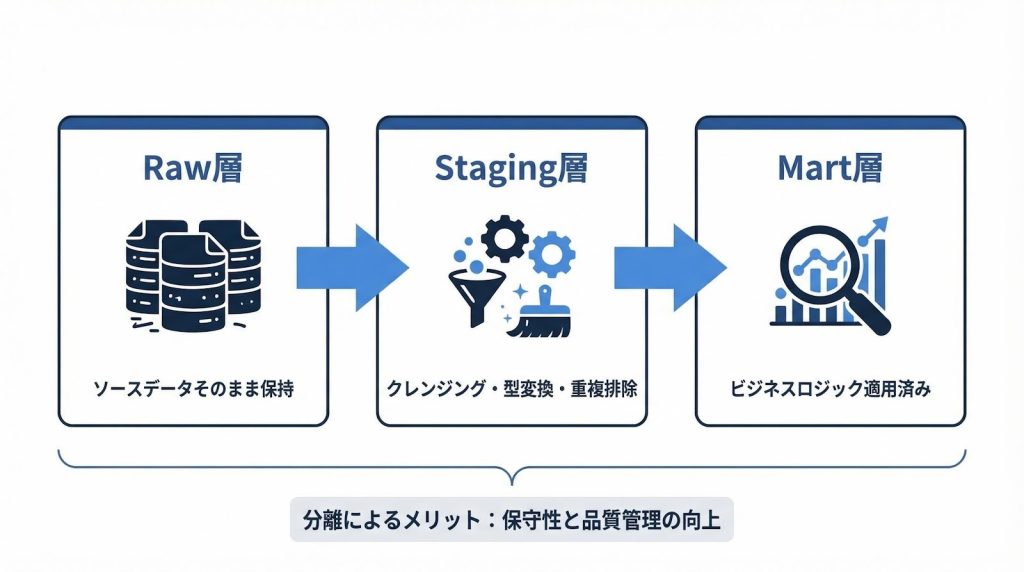
パイプライン設計の基本は、データレイヤーを役割ごとに分離した3層構造です。
- raw層:ソースデータをそのままの形で保持する層。変換処理は行わず、生データの保管場所として機能します。
- staging層:raw層のデータに対してクレンジング・型変換・重複排除などを適用した層。ビジネスロジックはまだ適用しません。
- mart層:ビジネスロジックを適用した分析用テーブルを提供する層。BIツールやレポートが参照する最終的なデータモデルです。
各層の役割を明確に分離することで、変換仕様が変わった場合に影響範囲を特定しやすくなり、品質問題の原因追跡も容易になります。
増分ロードの実装は、タイムスタンプベースの差分抽出またはCDCで行うのが一般的です。データ量が多い・更新頻度が高い・ソース側がフルエクスポートに対応していない場合に特に有効で、フルロードと比較してSnowflakeのコンピュートコストと処理時間を削減できます。
ただし、ソース側にタイムスタンプカラムがない場合や、削除レコードの追跡が必要な場合はCDCの導入を検討してください。
データ品質チェックとガバナンスの組み込み
パイプラインに品質チェックを組み込まないと、下流の分析やレポートに誤ったデータが流れ込んでも気づくのが遅れます。
dbt testをパイプラインに組み込むことで、NULLチェック・一意性チェック・参照整合性チェックをデータ変換の実行と同時に自動検証でき、品質問題の早期発見が可能になります。
品質チェックが失敗した場合のアラートと対応フローも設計段階で決めておくことが重要です。チェック失敗時に後続処理を止めるか、警告のみで続行するかは、データの用途と業務への影響度によって判断してください。
ガバナンス面では、Snowflakeのデータマスキングポリシーやタグ付けをETL工程で設定しておくことで、個人情報保護やアクセス制御の要件をパイプライン設計の段階から担保できます。後から追加しようとすると既存のパイプラインへの影響が大きくなるため、初期設計時に組み込む方が現実的です。
リバースETLの仕組みと代表的なツール
リバースETLは、DWHで加工・集計した顧客データをCRM・MAツール等の業務システムへ同期する、通常のETLとは逆方向のデータフローです。
リバースETLとは?DWHから業務ツールへデータを同期する仕組みと導入方法
分析結果を業務アクションに直結させたい場合、たとえば顧客スコアリング結果を営業チームのCRMに反映したり、セグメント情報をMAツールに同期してキャンペーンに活用したりするニーズに対応します。
国内マーケティングツールとの連携を重視する場合は、GENIEE CDPも選択肢のひとつです。SnowflakeをDWHとして活用しながら、分析した顧客セグメントをGENIEE MAやGENIEE ENGAGEなどの国内マーケティングツールへシームレスに連携できます。
リバースETLが必要かどうかの判断基準は、「分析結果を業務システムへ手動でエクスポートする作業が定期的に発生しているか」「分析チームと営業・マーケティングチームの間でデータの受け渡しにラグが生じているか」の2点を確認することです。
これらに該当する場合は、リバースETLの導入によって手作業を自動化できる可能性があります。
まとめ
この記事では、Snowflake環境でのETL/ELT選択から取り込み方式・ツール選定・コスト管理・パイプライン設計・リバースETLまでを一連の流れで整理しました。
Snowflakeのアーキテクチャ特性上、ELTが基本方針ですが、ソース側でのクレンジングが必須な場合はETL前処理を組み合わせます。取り込み方式は「大量バッチならCOPYコマンド」「準リアルタイムならSnowpipe」「秒〜分単位のリアルタイムならストリーミング」という順で要件に照らして選択します。
コスト管理では高頻度書き込みによるウェアハウスの常時起動を避けること、設計品質では3層レイヤー・増分ロード・品質チェックの3点を初期設計に組み込むことが、後から大きな修正を避けるための実践的な指針です。顧客データの統合・分析・マーケティング施策への活用を一貫して自動化したい場合は、GENIEE CDPのような顧客データ基盤との組み合わせも選択肢に加えてみてください。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。













