データウェアハウス(DWH)とは?導入のメリットや選び方について解説
「データウェアハウス(DWH)を導入するよう言われたが、そもそも何が違うのかよくわからない」そう感じている方は少なくありません。通常のデータベースとの違いも曖昧なまま、データレイクやデータマートという言葉も飛び交い、どこから整理すればよいか迷ってしまうのは自然なことです。
データウェアハウスとは、ERP・CRM・POSなど複数の基幹システムに分散したデータを、分析・意思決定の目的で時系列に統合管理する専用のデータ基盤です。日常業務の処理を担うデータベースとは設計思想が根本的に異なり、「過去データを削除せず履歴として蓄積する」という点がその本質にあります。
この記事では、DWHの定義と4つの特徴から始め、混同されやすいDB・データレイク・データマートとの違い、導入で得られるビジネス上のメリット、そして主要クラウドサービスの選び方まで、判断に必要な情報を体系的に整理していきます。
データウェアハウス(DWH)とは何か

DWHへの理解を深めるには、まず「なぜこの基盤が生まれたのか」という背景から入るのが近道です。
定義だけを暗記しても、実際の設計判断には役立ちません。ここでは定義・背景・4つの特徴・周辺技術との関係を順に整理します。
DWHの定義と生まれた背景
データウェアハウスは、「意思決定支援のために、主題別に編成され(subject-oriented)、統合され(integrated)、時系列性を持ち(time-variant)、非更新性(non-volatile)を備えたデータの集合体」と定義されます。この定義はデータウェアハウスの概念を体系化したビル・インモン(William H. Inmon)氏によるもので、現在も広く参照されています。
この基盤が必要とされた背景には、企業内のデータ分散という構造的な問題があります。販売管理にはERP、顧客管理にはCRM、店舗運営にはPOSシステムと、業務ごとに異なるシステムが導入されると、それぞれのデータは独立したサイロに閉じてしまいます。
「先月の売上と顧客の購買傾向を合わせて分析したい」という横断的なニーズに、個別のシステムは応えられません。DWHはこの課題を解決するために設計された専用の分析基盤です。
DWHの4つの特徴
DWHには、通常のデータベースとは異なる4つの設計原則があります。これらを理解すると、「なぜDWHはデータを削除しないのか」「なぜ分析に向いているのか」という疑問が自然に解消されます。
1. サブジェクト指向
DWHのデータは、業務処理の流れではなく「分析テーマ」を軸に整理されます。売上・顧客・在庫・商品といったテーマ(サブジェクト)ごとにデータを編成するため、特定の問いに対して必要なデータをすぐに引き出せる構造になっています。
受注処理や在庫引き当てといった業務フローを中心に設計されるOLTPシステムとは、根本的に編成の考え方が異なります。
2. 統合性
複数のシステムから集めたデータは、命名規則や単位、コード体系がバラバラなことがほとんどです。DWHではETLプロセスを通じてこれらを統一フォーマットに変換・クレンジングしてから格納します。
「A社システムでは”男性”、B社システムでは”M”と表記されていた性別データを統一する」といった名寄せ作業がその典型です。
3. 時系列性
DWHに格納されるデータには必ずタイムスタンプが付与され、過去から現在にわたる変化を追跡できます。
「昨年同月比での売上推移」や「顧客の購買頻度の変化」といった時系列分析が可能になるのは、この設計原則があるためです。
4. 非更新性
一度格納されたデータは原則として更新・削除されません。これにより、同じ条件でクエリを実行すれば常に同じ結果が返るという「分析の再現性」が担保されます。
業務システムでは最新状態に更新し続けるのが当然ですが、DWHでは過去の事実を変えないことが分析の信頼性の根拠になります。
データレイクとデータウェアハウスの違いとは?選び方と使い分けを解説
データマートとは?DWH・データレイクとの違いと構築手順を解説
ETL・BIツールとDWHの関係
DWHは単独で機能するシステムではなく、データの流れの中核に位置する基盤です。上流にはETL、下流にはBIツールが連携し、3層のアーキテクチャを形成しています。

ETL(Extract・Transform・Load)は、各業務システムからデータを抽出し、クレンジング・変換を施してDWHへ格納するプロセスです。DWHに入るデータの品質はETLの精度に依存するため、分析の信頼性を左右する前段工程といえます。
ETLとDWHとは?役割の違いからBIツールとの連携構造まで解説
BIツール(Business Intelligence)はDWHに蓄積されたデータをダッシュボードやレポートとして可視化・分析するフロントエンド層です。Tableau・Power BI・Lookerなどが代表的で、経営層や現場担当者がSQLを書かずにデータを参照できる環境を提供します。データソース→ETL→DWH→BIツールという一方向の流れが、基本的なアーキテクチャになります。
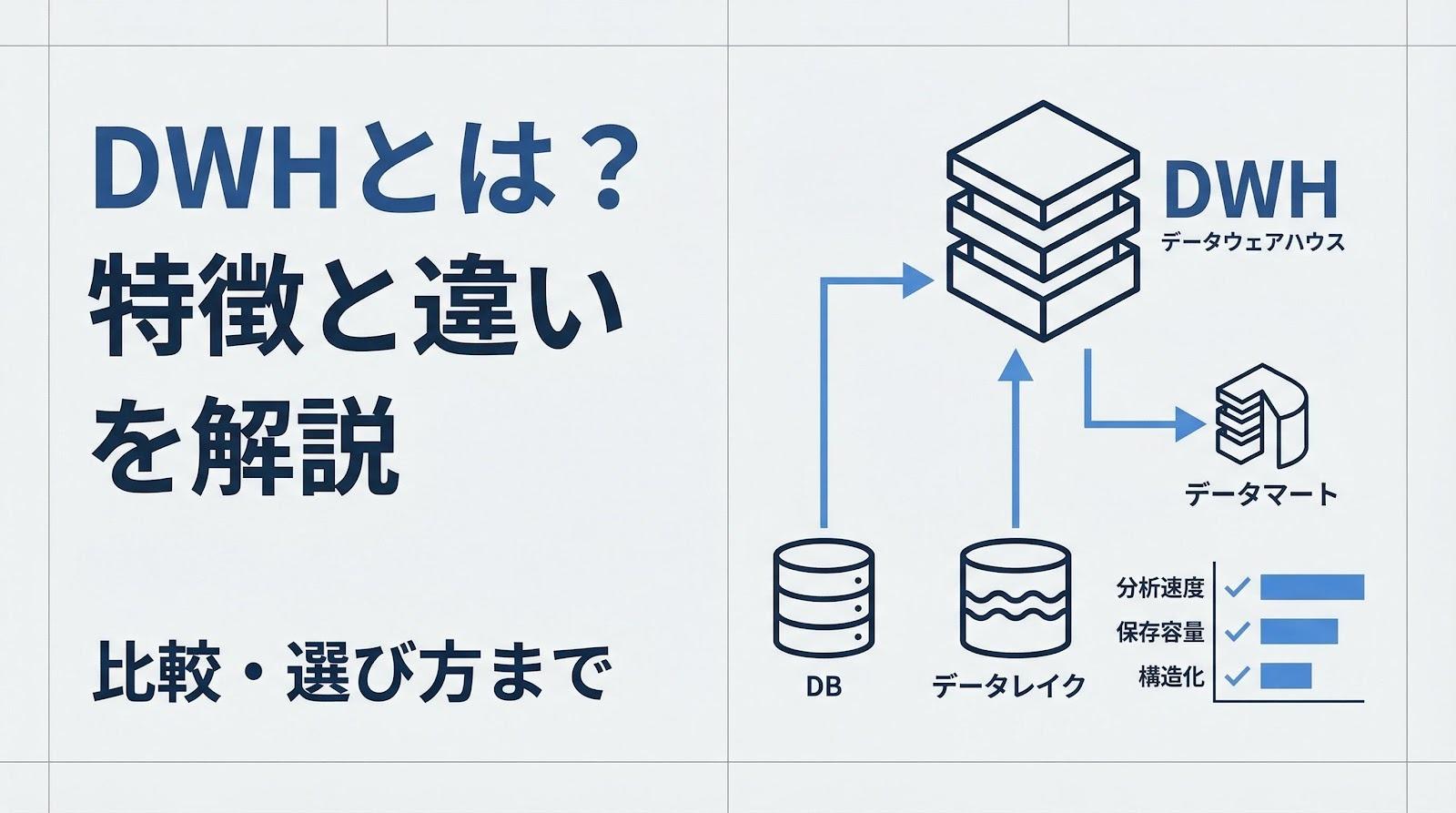
データベース・データレイク・データマートとの違い

「DWHとデータベースは何が違うのか」「データレイクとどう使い分けるのか」この混乱は、それぞれの概念が似た文脈で語られることが多いために起きます。
用途・対象データ・更新方式・規模の4軸で整理すると、違いが明確になります。
| 概念 | 主な用途 | 対象データ | 更新方式 | 規模・対象範囲 |
| データベース(DB) | 業務処理(OLTP) | 構造化データ | 随時更新・削除 | 業務システム単位 |
| データウェアハウス(DWH) | 分析・意思決定 | 構造化データ | 追記のみ(非更新) | 全社横断 |
| データレイク | 生データの一元格納 | 構造化・非構造化データ | 生データのまま格納 | 全社横断 |
| データマート | 部門特化の分析 | 構造化データ(DWHから切り出し) | 追記のみ(非更新) | 部門・業務単位 |
DWHと通常のデータベース(DB)の違い
データベース(DB)は、受注・在庫・会計といった日常業務をリアルタイムで処理するために設計されています。注文が入れば在庫数を減らし、支払いが完了すれば請求ステータスを更新する。このように「現在の状態を正確に保つ」ことがDBの本来の役割です。
DWHはこれとは逆の発想で設計されています。過去のデータを削除せず履歴として積み重ねることで、「3年前と比べて顧客単価はどう変化したか」「季節ごとの需要パターンはどうなっているか」といった問いに答えられます。日常業務の処理にはDB、過去データを含む横断的な分析にはDWHという使い分けが基本的な判断軸です。両者は競合するものではなく、DBで処理されたデータがETLを経てDWHに蓄積されるという補完関係にあります。
データベースとデータウェアハウスの違いとは?OLTPとOLAPの役割から解説

DWHとデータレイクの違い
データレイクは、画像・動画・ログファイル・SNSの投稿データなど、形式を問わずあらゆるデータを生のまま格納する基盤です。「将来どう使うかはまだ決まっていないが、とにかく捨てずに蓄積しておく」という思想で設計されています。
DWHとの最大の違いは、データの「加工度」にあります。DWHに格納されるデータはETLで変換・クレンジング済みの構造化データであり、分析クエリをすぐに実行できる状態になっています。データレイクは生データのまま保存するため、分析に使うには別途加工が必要です。
分析用途が明確で構造化データが中心であればDWH、多様なデータを将来の活用のために蓄積するならデータレイクが適しています。なお、データレイクとDWHの両方の特性を兼ね備えた「データレイクハウス」というアーキテクチャも、Apache IcebergやDelta Lakeなどのオープンテーブルフォーマットの普及とともに、2026年現在では主要な選択肢の一つとして定着しています。
データレイクとデータウェアハウスの違いとは?選び方と使い分けを解説
DWHとデータマートの違い
データマートはDWHの下位概念です。全社横断のデータを統合管理するDWHから、特定の部門や業務に必要なデータだけを切り出して構築した小規模な分析基盤を指します。
たとえば、マーケティング部門が顧客セグメント分析に使うデータマートや、経理部門が月次レポート用に使うデータマートといった形で、DWHを源泉として複数のデータマートが派生します。全社統合の分析基盤が必要ならDWH、特定部門の分析ニーズに素早く応えたいならデータマートという使い分けになりますが、多くの場合は両者を組み合わせて運用します。
データマートとは?DWH・データレイクとの違いと構築手順を解説
DWH導入で解決できる業務課題とビジネスメリット

DWHの定義と類似概念との違いを整理したところで、次は「実際に導入すると何が変わるのか」という実務的な問いに移ります。
データ分散という構造的な課題を抱える企業にとって、DWHが解決できる範囲と限界を把握しておくことが、導入判断の出発点になります。
1. データ統合による分析精度の向上
DWH導入前の典型的な状況は、「売上データはERPに、顧客データはCRMに、購買データはPOSに」という分散状態です。この状態では、部門をまたいだ分析のたびにデータを手動で突き合わせる作業が発生し、レポート作成に数日かかることも珍しくありません。
DWHで複数システムのデータを一元管理すると、この手作業が不要になります。ETLによるクレンジング・名寄せを経てデータが統一フォーマットで蓄積されるため、「どのデータが正しいか」という確認コストが下がり、分析結果への信頼性が高まります。
2. 意思決定速度の向上
時系列でデータが蓄積されることで、トレンド分析や季節変動の把握も現実的になります。「昨年の同時期と比べて顧客の離脱率はどう変化したか」「四半期ごとの在庫回転率の推移はどうか」といった問いに、BIツールを通じて迅速に答えられる環境が整います。
意思決定の根拠をデータに求める文化を組織に根付かせるには、こうした「問いを立てたらすぐ確認できる」基盤が前提条件になります。
DWHの選び方と主要クラウドサービスの比較

DWHの導入を具体的に検討する段階では、「どのサービスを選ぶか」よりも先に「何を基準に判断するか」を整理することが重要です。
選定基準が曖昧なまま製品比較に入ると、機能の多さや知名度で選んでしまい、運用フェーズで想定外のコストや工数が発生しやすくなります。
【製品比較】データウェアハウスのおすすめ10選|選定時のポイントとは?
クラウド型とオンプレミス型の選択
現在のDWH市場はクラウド型が主流です。初期投資が不要でスケーラビリティが高く、インフラの運用管理をクラウドベンダーに委ねられる点が、多くの企業にとって現実的な選択肢になっています。
一方、オンプレミス(アプライアンス型)が有力な選択肢になるのは、自社業務への高度な最適化が必要な場合や、データをクラウドに置くことへのセキュリティ上の制約がある場合です。金融機関や官公庁など、厳格なデータ管理要件がある業種では依然として検討されます。
クラウド型を選ぶ場合でも、インフラ管理が不要になる一方でデータエンジニアリングの知識は必要です。ETLパイプラインの設計・運用、クエリのチューニング、コスト管理といった作業は社内で担う必要があるため、「クラウドにすれば運用が楽になる」という期待は過度に持たないほうが安全です。
社内にデータエンジニアがいるか、あるいは外部パートナーに委託できるかを事前に確認することが、選定の前提条件になります。
データパイプラインとは?ETLとの違いから設計・構築手順まで解説
DWH選定に際する主なチェックポイント
クラウドDWHを選定する際に確認すべき項目は、大きく5つあります。
- データ量・拡張性:現在のデータ量だけでなく、3〜5年後の増加を見越したスケーラビリティを確認する
- 既存クラウド環境との親和性:AWS・Azure・GCPのいずれかをすでに利用している場合、同一エコシステム内のDWHを選ぶと連携コストが下がりやすい
- 運用管理の容易さ:サーバーレス型かどうか、インフラ管理の負荷がどの程度かを確認する
- コスト体系:ストレージとコンピュートが分離課金か、クエリ量に応じた従量課金かによって、利用パターンによるコストが大きく変わる
- BIツール・ETLツールとの連携性:すでに利用しているBIツールやETLツールとのコネクタが整備されているかを確認する
主要なクラウドDWHサービスの特徴
選定基準を整理したうえで、代表的なクラウドDWHサービスの特徴を確認します。
| サービス名 | アーキテクチャ | 主な強み | 適合シーン | 料金体系 |
| Google BigQuery | サーバーレス | ペタバイト級の超高速クエリ処理、BigQuery AIによる生成AI・ML統合(自然言語クエリ、ベクトル検索、AI関数) | GCP環境を利用中、大規模データ分析、MLとの統合を検討 | 従量課金(クエリ量・ストレージ) |
| Snowflake | ストレージ・コンピュート分離 | マルチクラウド対応(AWS・Azure・GCP)、柔軟なスケーリング | 複数クラウド環境をまたぐ、コスト最適化を重視 | コンピュート使用量+ストレージ従量課金 |
| Azure Synapse Analytics | 統合分析プラットフォーム | DWH・データ統合・ビッグデータ分析・AI/MLを統合、Power BIとの高い親和性 | Azureエコシステムで完結したい、Power BIをすでに利用中 | 要確認(公式で確認) |
| Amazon Redshift | 列指向ストレージ+MPP(超並列処理 | AWSサービスとの深い統合、大規模データの高速クエリ、ゼロETL統合 | AWS環境を利用中、既存のAWSデータパイプラインと連携 | Provisioned(ノードタイプ別時間課金)またはServerless(RPU時間課金)の2形態 |
| Oracle Autonomous Data Warehouse | 自律型(自動チューニング) | 自動スケーリング・自動バックアップ・自動パッチ適用、Oracle DBからの移行が容易 | Oracle製品をすでに利用中、DBA不在でも運用したい | 要確認(公式で確認) |
各サービスは得意とするアーキテクチャや適合シーンが異なるため、自社の既存環境や優先事項と照らし合わせて検討してください。
CDPとDWHの違いとは?それぞれの機能や活用方法まで徹底解説
まとめ

この記事では、データウェアハウスの定義から類似概念との違い、導入メリット、主要サービスの選び方まで、DWH導入を検討するうえで必要な情報を整理してきました。
DWHの本質は「分析のために過去データを削除せず統合管理する基盤」という一点に集約されます。通常のデータベースが現在の状態を正確に保つために設計されているのに対し、DWHは時系列の履歴を蓄積することで横断的な分析を可能にします。データレイクとの違いは「加工度」、データマートとの違いは「対象範囲の広さ」で整理できます。
自社にDWHが必要かどうかを判断する起点として、次の3点を確認してみてください。
- 複数のシステムにデータが分散しており、横断的な分析ができていないか
- 過去データの時系列分析(トレンド把握・季節変動・前年比較など)が業務上必要か
- 部門をまたいだ統合分析を、定期的に実施する必要があるか
顧客データの統合・活用が主目的であれば、DWHに加えてGENIEE CDPのようなCDPも選択肢として検討する価値があります。ノーコードでの複数ツール連携、ID名寄せによる顧客の一元管理、AIを活用した分析サポートといった機能により、データエンジニアリングの専門知識がなくても顧客データ活用を始められる点が特徴です。
目的に応じてDWHとCDPを使い分けることで、データ基盤の投資対効果を高められます。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。