







ETLとDWHとは?役割の違いからBIツールとの連携構造まで解説

「ETLとDWHの違いがよくわからない」「BIツールを導入したいが、その前に何を整備すればいいのか」データ活用基盤の構築を検討し始めると、こうした疑問が次々と出てきます。
ETL・DWH・BIという3つの用語は、それぞれ独立した概念でありながら、実際のデータ活用では密接に連携しています。どれか一つを理解しただけでは、全体像が見えてきません。
端的に言うと、ETLは「データを整える仕組み」、DWHは「整えたデータを蓄積する場所」、BIは「蓄積したデータを分析・可視化するツール」です。この3層が揃って初めて、社内に散在するデータを経営判断や施策改善に活かせる状態になります。
この記事では、ETL・DWH・BIそれぞれの役割と連携の仕組みを順に整理します
なお、社内にデータ専門家がいない場合や構築・運用負荷を抑えたい場合は、ETL・DWH・BIを個別に組み合わせる方法に加え、GENIEE CDPのような統合型データ基盤という選択肢もあります。
理想のタッチポイントを構築|CDP活用で属人化しないデータ統合
ETLとは何か:抽出・変換・格納の3ステップを理解する
ETLはExtract(抽出)・Transform(変換)・Load(格納)の頭文字を取ったデータ統合プロセスです。複数の業務システムに分散したデータを取り出し、分析に使える形に整えてDWHへ届けるまでの一連の流れを指します。「データを集める」だけでなく、「使える状態にする」ところまでがETLの役割です。
各ステップで行われる処理の内容は異なります。以下でそれぞれを順に見ていきます。
分散する匿名顧客データを統合し成約率を高める|DMP活用で実現する営業変革
Extract(抽出):複数ソースからデータを取り出す
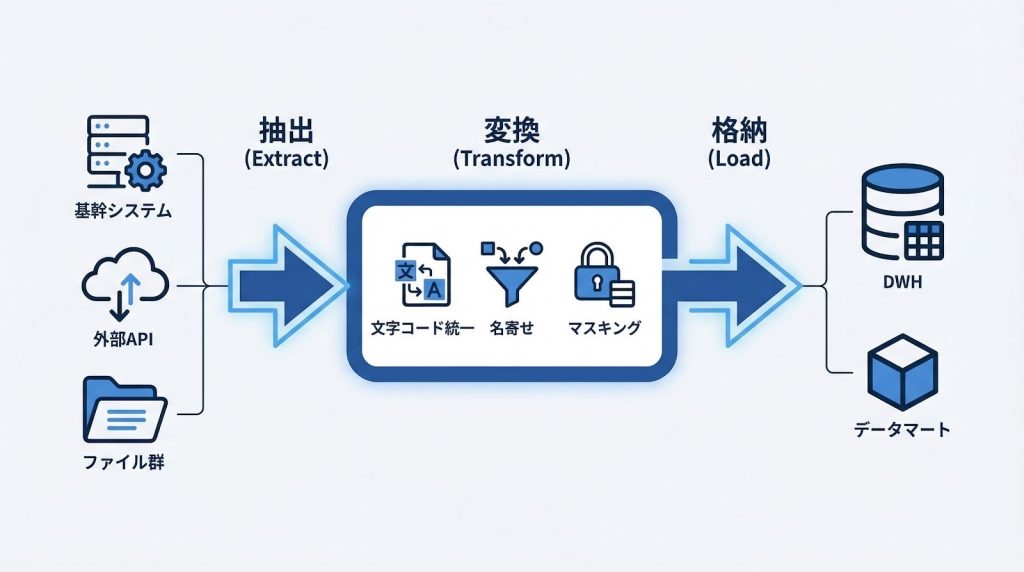
抽出フェーズでは、基幹システム・CRM・SFA・ECサイト・Webログ・クラウドサービスなど、さまざまなデータソースからデータを取り出します。対象はRDBのテーブルデータだけでなく、CSVファイル・APIレスポンス・ログファイルなど形式も多岐にわたります。
取得方法には大きく2種類あります。フルロードはデータソースの全件を毎回取得する方式で、初回構築時や小規模データに向いています。一方、差分抽出は前回取得以降に更新・追加されたレコードのみを取得する方式で、データ量が増えるほど処理時間とシステム負荷を抑える効果が大きくなります。日次バッチ処理では差分抽出が一般的です。
Transform(変換):分析に使える形に整える
変換フェーズは、ETLの3ステップの中で最も処理の種類が多く、データ品質を左右する核心部分です。異なるシステムから集めたデータは、文字コードや日付フォーマットがバラバラだったり、同一人物が別の表記で登録されていたりすることが珍しくありません。
代表的な変換処理には次のようなものがあります。
- 文字コード統一(Shift-JIS → UTF-8 など)
- 日付フォーマット統一(「2024/01/15」「20240115」などの表記ゆれを解消)
- 名寄せ・重複排除(同一顧客の複数レコードを統合)
- 欠損値処理(NULL補完・除外・フラグ付与)
- 個人情報マスキング(氏名・電話番号などの匿名化)
マスキング処理はデータガバナンスの観点でも重要です。個人情報をDWHに格納する前に変換フェーズで匿名化しておくことで、分析環境でのデータ取り扱いリスクを下げられます。
Load(格納):DWHへデータを書き込む
格納フェーズでは、変換済みのデータを格納先に書き込みます。格納先はDWH(データウェアハウス)が代表的ですが、目的によってデータマートやデータレイクが選ばれることもあります。
書き込み方式も要件に応じて使い分けます。
- 上書き(Full Refresh):既存データを全件削除して新しいデータで置き換える。常に最新状態を保ちたい場合に使用
- 追記(Append):既存データを残したまま新しいレコードを追加する。ログや履歴データの蓄積に適する
- マージ(Upsert):既存レコードがあれば更新、なければ挿入する。マスタデータの同期に向いている
格納方式の選択を誤ると、データの重複や欠損が発生します。特に差分抽出と組み合わせる場合は、追記とマージのどちらを使うかを設計段階で明確にしておくことが重要です。
DWH(データウェアハウス)とは何か:業務DBとの違いと役割
DWH(データウェアハウス)は、複数のシステムから集約された構造化データを時系列で蓄積し、大量データへの高速な集計クエリに対応する分析専用の統合格納基盤です。「データの倉庫」という名称が示す通り、日々の業務処理ではなく、過去から現在にわたるデータを整理して保管し、分析に提供することが主な役割です。
業務用データベースとの違い、そしてデータレイクとの使い分けを理解することで、DWHがデータ活用基盤のどこに位置するかが明確になります。
業務用データベース(OLTP)との違い
業務用データベースはOLTP(Online Transaction Processing)と呼ばれ、受注・在庫更新・顧客登録といった頻繁な書き込み・更新処理を高速にこなすことに特化しています。1件のレコードを素早く参照・更新するのは得意ですが、「過去3年間の売上を月別・商品カテゴリ別に集計する」といった大量データへの複雑なクエリには向いていません。
DWHはOLAP(Online Analytical Processing)と呼ばれる分析処理に最適化されており、数百万〜数十億件のレコードを横断する集計クエリを効率的に処理できます。業務DBをそのまま分析に使うと、クエリが業務処理のパフォーマンスを圧迫するリスクがあります。分析専用の環境を別途整備する理由はここにあります。
データレイクとの違いと使い分け
データレイクとDWHはどちらも「データを蓄積する基盤」ですが、蓄積するデータの状態と目的が異なります。
データレイクは、構造化・非構造化を問わず生データをそのままの形で蓄積します。画像・動画・ログ・JSON・CSVなど、あらゆる形式のデータを変換せずに保管できるため、「とにかく集めておく」段階に向いています。一方、DWHは分析用に整形・構造化済みのデータを蓄積します。スキーマが定義されており、BIツールからの集計クエリに即座に応答できる状態になっています。
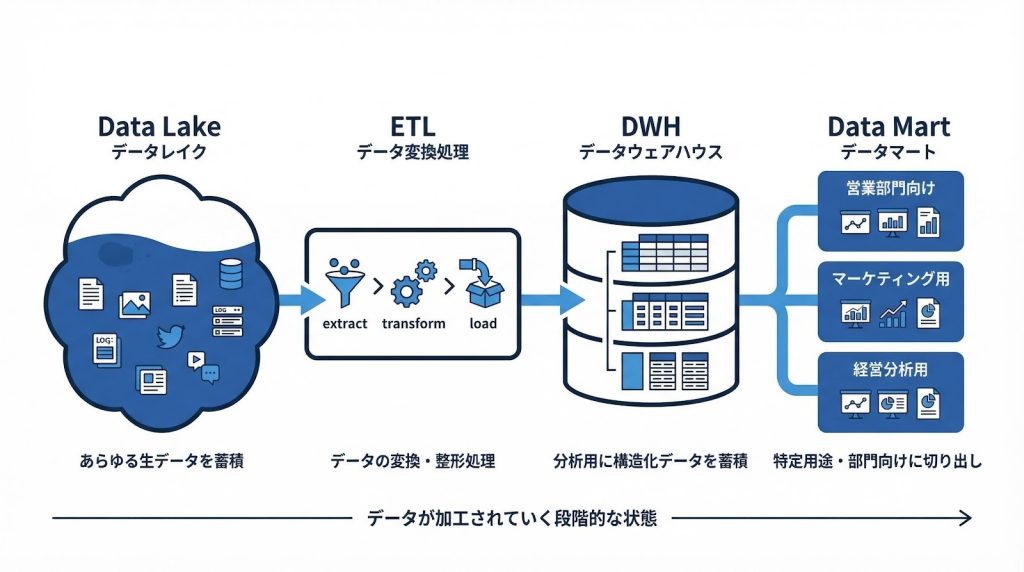
データ活用基盤の全体像を整理すると、次のような4層構造になります。
- データレイク:生データの一次蓄積
- ETL:変換・整形処理
- DWH:分析用データの統合格納
- データマート:部門・用途別に切り出した小規模格納基盤
データマートはDWHから特定部門や用途向けに切り出した小規模な格納基盤であり、BIツールからの参照先として活用されます。全社横断の分析はDWHで行い、営業部門向け・マーケティング部門向けといった用途別の高速参照はデータマートで対応するという使い分けが一般的です。
どちらを先に整備すべきかは、保有データの種類と分析の緊急度によります。すでに構造化データが中心で早期に分析を始めたい場合はDWHから着手し、非構造化データも含めた長期的なデータ蓄積を重視する場合はデータレイクを先に整備するという判断になります。
CDPとETLの違いとは?役割・配置関係・使い分けの判断基準を解説
ETL・DWH・BIツールはどう連携するのか:データ活用基盤の全体像

ETL・DWH・BIの3層は、それぞれが独立して機能するのではなく、データが流れる順番に役割を分担しています。「整える(ETL)→蓄積する(DWH)→分析する(BI)」という流れが基本形であり、どれか一層が欠けると分析の精度・速度・再現性が損なわれます。
経済産業省・IPAが策定したIPAのDX推進推論指標でも、データ活用はITシステムに求められる重要要素として位置づけられており、全社横断のデータ活用基盤の整備はDX推進の基盤として認識されています。
ここでは、データがどのように流れてBIツールに届くのか、そして何をどの順番で整備すべきかを整理します。
データの流れ:ETLがDWHに届けるまで
実際のデータ活用基盤では、基幹システム・CRM・ECサイトなど複数の業務システムが並行して稼働しており、それぞれが異なる形式・スキーマでデータを保持しています。ETLはこれらのシステムからデータを収集し、フォーマットを統一・変換した上でDWHへ格納します。
ETLが介在しない場合、各システムの不整合データや重複レコードがそのままDWHに流入します。たとえば、基幹システムでは「東京都渋谷区」、CRMでは「渋谷区」と登録されている住所データが混在すると、地域別の集計結果が正確に出なくなります。分析結果の信頼性は、DWHに届く前のデータ品質に直接依存しています。
ETL導入で確認すべきポイントとは?メリットや注意点、選定のポイントも解説
BIツールがDWHのデータを分析・可視化する
BIツール(Business Intelligence Tool)はDWH上のデータに接続し、ダッシュボードやレポートを生成します。TableauやPower BIといったツールは、SQLを書かなくてもドラッグ&ドロップの操作でグラフや集計表を作成できるため、非エンジニアのビジネス担当者でも分析できる環境を提供します。
ただし、BIツールはあくまでデータを『見せる』ツールです。接続先のDWHに品質の低いデータや網羅性の欠けたデータが蓄積されていれば、どれだけ優れたBIツールを使っても正確な分析はできません。これはデータ分野で広く知られる『Garbage In, Garbage Out(GIGO)』の原則そのものです。『BIツールを入れたのに使えない』という状況の多くは、DWHとETLの整備が不十分なことに起因しています。。
何をどの順番で整備すべきか
データ活用基盤の整備順序は、DWH選定 → ETL構築 → BI導入が基本です。格納先を先に確定することで、ETLの変換仕様(どの形式に整えるか)とBIの接続設計(どのテーブルを参照するか)を一貫して設計できます。逆にBIツールから先に導入すると、接続先のデータ構造が後から変わるたびにBI側の設定も修正が必要になります。
ただし、既存環境によって順序が変わるケースもあります。すでにオンプレミスのDWHが稼働している場合は、ETLの見直しやBIの追加から着手することになります。クラウドへの移行を検討している場合は、DWHの選定と並行してETLツールのクラウド対応状況を確認しておくと、後工程での手戻りを減らせます。
ETLとELTの違い:どちらを選ぶべきかの判断基準
ETLと似た用語にELTがあります。アルファベットの順序が違うだけに見えますが、処理の流れが根本的に異なります。どちらを選ぶかは、使用するインフラ環境・データ品質への要求水準・運用体制によって変わります。
関連記事
ETLとEAIの違いとは?EDI・API・ELTとの比較と選定基準を解説
リバースETLとは?DWHから業務ツールへデータを同期する仕組みと導入方法
Zero ETLとは?AWSでの設定手順と従来ETLとの使い分けを解説
ETLとELTの処理フローの違い
2つのアーキテクチャの違いは、変換処理をどのタイミングで行うかにあります。
ETLの処理フローは「データソース → 変換 → DWH格納」です。DWHに届く前に変換処理を完了させるため、格納されるデータの品質を事前に保証できます。変換処理はETLツール側のサーバーで行われます。
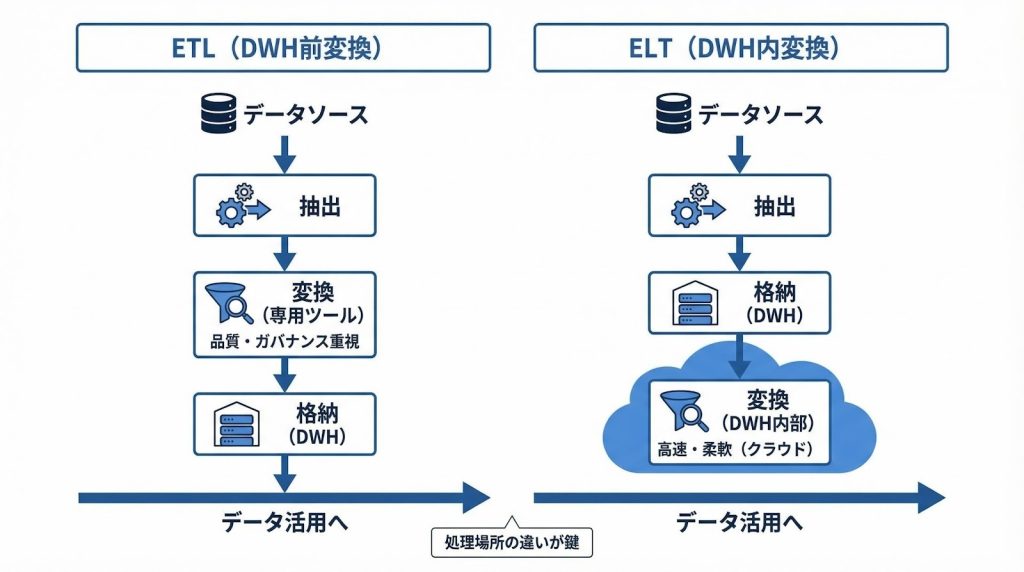
ELTの処理フローは「データソース → DWH格納 → DWH内で変換」です。生データをまずDWHに格納し、その後DWHの計算リソースを使って変換します。BigQueryやSnowflakeのようなクラウドDWHは大量データの並列処理が得意なため、変換処理をDWH側に任せることで高速な処理が可能になります。
ETLとELTの違いとは?処理順序における違い・メリット・選定基準を解説
ETLツール導入のメリットと選定ポイント

ETLの仕組みを理解した上で、次に検討すべきなのが「どのように実装するか」です。手作業やスクリプトで対応するか、専用のETLツールを導入するかによって、運用負荷とリスクの水準が大きく変わります。
手作業・自作スクリプトとETLツールの比較
小規模なデータ加工であれば、PythonやShellスクリプトで対応することは珍しくありません。しかし、データソースの数が増え、変換ロジックが複雑になるにつれて、スクリプト運用の課題が顕在化してきます。
主な課題は4点です。
- 工数の増大:データソースや変換パターンが増えるたびにスクリプトの追加・修正が必要になる
- ヒューマンエラー:手動実行や手動確認が残る工程でミスが発生しやすい
- 属人化:担当者が異動・退職した際に、スクリプトの仕様や実行手順が引き継げなくなる
- 保守コストの増大:データソース側の仕様変更のたびにスクリプトの修正対応が発生する
ETLツールはGUIによる処理フローの可視化・ログの自動記録・エラー通知機能を備えており、これらの課題を組織的に低減できます。特に属人化リスクへの対応は大きく、担当者が変わっても処理フローをツール上で確認・引き継ぎできる点は、スクリプト運用との明確な差です。
ETLツールを選ぶ際の5つの評価軸
ETLツールの選定では、機能の豊富さだけでなく、自社の環境・体制・将来的なデータ量の変化に対応できるかを評価することが重要です。以下の5軸で整理すると、候補ツールの比較がしやすくなります。
- 対応データソースの種類と拡張性:現在使用しているシステムへのコネクタが揃っているか。将来的に扱うデータ形式の変化も見越して拡張性を評価しておくことで、ツール移行コストの発生リスクを低減できます
- GUI操作性・ノーコード対応:エンジニア以外のメンバーが設定・確認できるか
- 変換処理の柔軟性:複雑な変換ロジックやカスタム処理に対応できるか
- 費用対効果:ライセンス費用・従量課金・運用コストの総量で評価する
- サポート体制:日本語サポートの有無、障害時の対応速度
代表的なETLツールの特徴を以下に整理します。
| ツール名 | 特徴 | 向いている環境 |
| AWS Glue | サーバーレス型。AWSエコシステムとの親和性が高く、S3・Redshiftとの連携がスムーズ | AWSを中心に構築されたエンジニア主導の環境 |
| Qlik Talend Cloud(旧Talend) | オープンソース版と商用版を持つ。GUIベースの変換設計と豊富なコネクタが強み | 幅広いデータソースへの対応が必要な環境 |
| Informatica IDMC(Intelligent Data Management Cloud) | エンタープライズ向けの高機能ツール。データガバナンス機能が充実 | 大規模・複雑なデータ統合が必要な環境 |
AWS GlueはサーバーレスでAWSエコシステムとの親和性が高く、エンジニア主導の環境に適しています。Qlik Talend Cloud(旧Talend)はオープンソース版と商用版を持ち、GUIベースの変換設計と豊富なコネクタによって幅広いデータソースへの対応力が強みです。どのツールも、まず自社の現在のデータソース構成と将来の拡張計画を整理した上で評価することをお勧めします。
| DataSpiderとは?ETL・EAIの違いや機能を解説 |
| AWS ETLとは?Glue・Lambda・EMRの使い分けと構成例を解説 |
| Azure ETLとは?Data Factoryの機能・料金・導入判断の進め方を解説 |
なお、上記のようなETLツール・DWH・BIツールを個別に選定・連携させる構成は柔軟性が高い一方、設計・構築・運用にエンジニアリングリソースが必要です。
「社内にデータ専門家がいない」「複数システムへのデータ連携を早期に立ち上げたい」という場合は、GENIEE CDPのような統合型データ基盤も選択肢として検討する価値があります。GENIEE CDPは標準で多数のツールとノーコード連携し、Webサイト・店舗・各種クラウドサービスなど複数のデータソースを集約できます。
売上分析や購入転換率分析などのテンプレートダッシュボードとAI分析機能を標準搭載しており、分析の専門知識がなくても日常的にデータを活用できる環境を整えられます。
まとめ
この記事では、ETL・DWH・BIという3つのコンポーネントの役割と、それらがどのように連携してデータ活用基盤を構成するかを整理しました。
押さえておくべき核心は、「整える(ETL)→蓄積する(DWH)→分析する(BI)」という3層の役割分担と、整備の順序です。DWHの格納先を先に確定し、ETLの変換仕様を設計し、最後にBIを接続するという流れが、後工程での手戻りを最小化します。
データ活用基盤の整備には「ETL・DWH・BIを自社で個別に組み合わせる方法」と「GENIEE CDPのような統合型データ基盤を活用する方法」の2つのアプローチがあります。特に顧客データの統合と早期の成果創出を重視する場合、導入支援チームによる要件定義から運用支援まで伴走するGENIEE CDPは有力な選択肢の一つです。自社に最適な整備方針について、まずは詳細を確認してみてください。
関連記事
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





プロフィール
GENIEE's library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。














