AI時代のデータ基盤構築:組織全体でデータ品質を高める「DataOps」とは?

この記事で分かること
- AI活用を見据えたデータ基盤構築において、データエンジニアだけでは対応しきれない課題とその解決策
- 組織全体でデータライフサイクルを回す「DataOps」の考え方と実践方法
- データモデルに「階層」を設定し、品質と軽快さを両立させる仕組み
- データオーナー制度の導入により、ビジネス部門が主体的にデータ管理を行う体制づくり
- AI活用に必要なメタデータとセマンティクスを段階的に整備し、組織をAI Readyにする具体的なアプローチ
はじめに:AI時代に求められるデータ基盤の変化
DX推進が加速する中、多くの企業がAIやデータ分析を活用した意思決定の高度化に取り組んでいます。しかし、AI活用を実現するためには、単に最新のAIツールを導入するだけでは不十分です。
データ基盤そのものが「AI Ready」な状態、つまり高品質なデータとメタデータが整備され、組織全体でデータを活用できる体制が整っていることが不可欠です。
この記事ではデータ基盤の再構築を通じて、組織全体でデータライフサイクルを回す「DataOps」の仕組みやAI時代に求められるデータ基盤構築の実践的なアプローチ手法について紹介します。
AI活用を阻む組織的課題:少数のデータ人材では対応しきれない現実

データエンジニアがボトルネックになる構造
多くの企業では、データ分析やデータ基盤の構築・運用を少数のデータサイエンティストやデータエンジニアなどの専門人材が担っています。しかし、AI時代においてビジネスの変化スピードは加速しており、データ人材のスキルをAIで強化したとしても、ビジネスのスケールアウト速度には追いつかないという現実があります。
データエンジニアが品質管理に集中すると新規要求に対応できず、逆にビジネス課題だけに向き合うと同じ問題を何度も解く「二度手間 」が発生するというジレンマに直面することが多いのではないでしょうか。具体的には、同じ指標が複数存在し、同じクエリが量産され、数値の不一致が頻発するという問題が起きるという事象です。
ドメイン知識の壁とリードタイムの長期化
データエンジニアは技術的な専門性を持つ一方で、ビジネスの意思決定者ではないため、ドメイン知識の解像度が低くなりがちです。
その結果、データ分析の依頼から提供までのリードタイムが長くなり、調整コストや人件費も増大します。
AI時代においては、このリードタイムがビジネスの変化スピードに追いつかず、競争力の低下につながる恐れがあります。
さらに、データ品質が低い状態でAIを活用すると、アウトプットする情報の精度も低く手戻りが多い状態となることで、間違った情報が結果的に誤った意思決定を招くリスクも高まります。
組織全体でデータ品質に向き合わなければ、AI活用の価値を十分に引き出すことはできません。
DataOps:組織全体でデータライフサイクルを回す仕組み
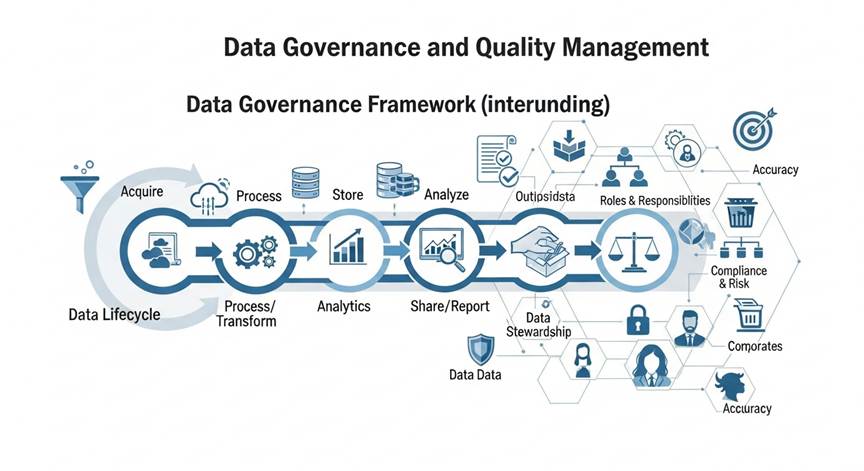
DataOpsとは何か
DataOpsとは、DevOpsの考え方をデータ領域に適用したアプローチです。データのライフサイクル(作成→活用→評価→改善→削除)を高速で回し、組織全体でデータを育てていく発想が特徴です。
AI時代におていは、このDataOpsの考え方を取り入れ、データ基盤を再設計することでデータドリブンな経営が成立する確度が高まるのです。
具体的には、クラウドのAIと相性の良いAIデータプラットフォームをベースにデータ変換ツール、BIツールを組み合わせた基盤を構築します。
この基盤では、ビジネス部門のメンバーがSQLを活用せずとも分析や可視化まで実施できる環境を整えることが大切です。
データオーナーを決める
運用面では各部署に「データオーナー」を配置するとデータガバナンスやデータの取り扱いについてのルールに沿った運用を促進できます。
データオーナーとは、各チームの意思決定責任者(多くはプロダクトマネージャー)であり、ビジネス理解が最も深く、データの利用目的を理解し、品質への責任を持つ人材を配置すると良いでしょう。
データオーナーとその配下の開発メンバーは、SQLの知識を活かしてデータモデルを作成し、データの取り扱いや運用ルールまでを定義します。
そうすることでビジネスやファクトへの解像度が最も高い人材がデータ管理を担うことで、データの品質と活用スピードが大幅に向上します。
ある企業では、短期間で複数名のデータオーナーが誕生し、全員でデータライフサイクルを回す体制の下地が整います。
【関連情報】データ基盤の詳細については、こちらの製品サイトもご参照ください
階層管理による品質とアジリティの両立

データモデルに階層を設定する意義
DataOpsを実践する上で重要なのが、データモデルに階層を設定し、品質基準を明確にすることです。例えば以下のようにデータモデルに段階や階層を設けて分類し、それぞれに異なる品質基準とデータ保持期間を設定します。
最も品質が高い階層は監査や外部公表に使用するデータで、メタデータとテストが完備され、永続的に保持されます。
次に高い階層レベルでは経営KPI、次の階層レベルでは部門意思決定に使用するデータで、いずれもメタデータとテストが必須です。
一方、そこから下の階層レベルでは主にマーケティングや営業現場でデータの可視化に使用するデータとし、一定期間後に自動削除されても支障のないものを取り扱うといった階層分類です。
軽快さと品質の両立を実現する仕組み
下層の階層レベでは、現場でのスピードや利活用の柔軟性を重視したデータモデルです。
新機能のリリース直後に速報値を確認したり、日々の営業活動やマーケティング活動にデータを活用したりと迅速な意思決定を行うために、自由度が高く、素早く試せる環境を提供します。
一方でセキュリティレベルの高い上位階層ではデータ品質を重視し、メタデータとテストを完備することで、中長期的な意思決定の質を高めるといった運用が適しています。
これらのデータのセキュリティや運用内容による階層構造の仕組み化により、「データを作って終わり」というデータが日に日に膨れ上がることを防ぎ、コストの最適化と同時に不要なデータは自動削除され、重要なデータだけは段階的に品質を向上させることができます。
組織の力学を理解したDataOpsの実装と運用が、この仕組みの成功の鍵となっているのです。
AI基盤の比較や選定については、こちらのホワイトペーパーを参考にして下さい。
情報資産をセマンティクス化し、AI活用を次のステージへ
メタデータとセマンティクスの一元管理
AI活用において、メタデータとセマンティクス(データの意味情報)の整備は極めて重要です。
例えば、AIBIツールとデータ変換ツールでメタデータとセマンティクスを一元管理し、AIを活用してセマンティックレイヤーを自動変換・同期する仕組みを構築するなどが該当します。
具体的には、データオーナーがAIを搭載したBIツールでメタデータとメトリクスを定義すると、それが自動的にデータウェアハウスのセマンティックビューに変換されるなどの仕組みとなります。
セキュリティレベルの高い上位階層到達したデータモデルは、いつの間にか品質の高いモデルとしてAI分析ツールでも利用可能になるといった仕組みとなります。
CDP活用の具体的なガイドについては、こちらのホワイトペーパーもご覧ください
組織がAI Readyな状態になるために必要なこととは?
定量的成果
前述したDataOpsと階層管理の導入により、以下のような顕著な成果が得られるはずです。
二度手間がなくなり、工数が大幅に削減されます。同じ指標が複数存在する問題や、同じクエリが量産される問題が解消され、データエンジニアの負担が軽減されます。
また、数値の不一致が解消され、信頼できる唯一の情報源の実現に大きく前進することでしょう。
データの信頼性が向上することで、データドリブンな意思決定の質も向上していくはずです。
定性的成果
定性的な成果としては、SQLを書けない人も段階的に分析が可能になることが挙げられます。
AIBIツールを活用し、自然言語でデータと対話することで、ビジネスメンバーも即時にアドホックな分析ができるようになります。
さらに、AI Readyへ移行する組織文化が醸成されていきます。品質とメタデータにみんなで向き合うことで、いつの間にかAI Readyな状態が実現されていく構図が形成できます。
データエンジニアがボトルネックにならず、真に必要なデータを全員が使える状態、つまり
データの民主化
の環境整備が進んでいくことでしょう。
AIBI(AI搭載型分析)ツールの活用
下位階層レベルのデータモデルが整備されることで、高度なAI分析ツールも同時に活用できるようになるはずです。最近一部の企業からリリースされているAIBIツール一体型CDPシステムでは自然言語でデータと対話し、チャートやトレンド分析を自動生成する機能なども加われうことで、ビジネスメンバーが自ら分析を行い、迅速な意思決定を実現しているという情報も聞かれます。
例えば、「過去数ヶ月のUUの推移を教えてください」「メディア別のユーザー数を比較してください」といった質問に対して、AIが自動的にSQLを生成し、結果を可視化します。これにより、データエンジニアに依頼することなく、ビジネスメンバーが自律的にデータ分析を行える環境が整備されます。
まとめ:AI Readyは段階的に作れる
AI時代のデータ基盤構築において重要なのは、単に最新のAIツールを導入することではなく、組織全体でデータ品質に向き合い、段階的にAI Readyな状態を作り上げることです。
これまで触れてきた内容から以下の3つのポイントが成功の鍵であることが分かります。
第一に、階層定義で品質を可視化することです。データモデルを段階的に分類し、それぞれに適切な品質基準を設定することで、現場でのデータ活用のスピードと品質を両立できます。
第二に、データオーナーを配置しデータの取り扱いに関しての責任と権限を明確化することです。ビジネス部門が主体的にデータ管理を行うことで、ドメイン知識の壁を乗り越え、リードタイムを短縮できるといったメリットもあります。
第三に、AIBI分析ツールを活用することです。品質向上が自分の業務や組織の業務改善や組織や会社としての現場競争力を高めることを実感できる設計が、継続的な利用や改善を促します。
AI活用を目的とするのではなく、組織がAI Readyになることで、いつの間にかAI分析ツールが使える状態を作ることが最短かつ本質的なアプローチと言えるのではないでしょうか。
組織の力学を理解したDataOpsの実装と運用が、AI時代のデータ基盤構築の成功を左右します。
本記事でご紹介したようなデータ基盤の構築やAI活用にご興味をお持ちの方は、ぜひお気軽にお問い合わせください。
また、データ基盤やAI READYなデータ環境を構築する次世代型CDP活用に関する詳細な資料もご用意しております。
DX推進やデータ活用でお悩みの企業様、システム部門やマーケティング部門の責任者の方々からのご相談をお待ちしております。
貴社のビジネス課題に合わせた最適なソリューションをご支援いたします。
定着率99%の国産SFAの製品資料はこちら

- SFAやCRM導入を検討している方
- どこの SFA/CRM が自社に合うか悩んでいる方
- SFA/CRM ツールについて知りたい方





GENIEE’s library編集部です!
営業に関するノウハウから、営業活動で便利なシステムSFA/CRMの情報、
ビジネスのお役立ち情報まで幅広く発信していきます。