はじめに
GENIEE インフラチーム片岡です。2019年に新卒として入社し、最初の二年間は DSP のフロントチームで管理画面の開発をしていましたが、2021年中頃からチームを異動し、今はインフラ寄りのお仕事をしています。
そのころから、DSP のレポート集計基盤を刷新するプロジェクトが動いており、なんやかんやあって遂に数ヶ月前にリプレイスが終わりました。今回はこれについてお話をしたいと思います。

片岡 崇史/高知工科大学大学院を卒業後 2019 年に新卒入社。R&D アドプラットフォームサプライサイド開発部 DevOps チーム所属。
レポート集計基盤について
弊社では、オープンソースの列指向 DBMS のひとつである ClickHouse を使ってレポートデータを閲覧できるようにしています。
過去の ClickHouse の利用については以下をご覧ください。
レポート集計基盤は、弊社の DSP から配信された広告の成果ログから成果を集計し、最終的に ClickHouse のレポートテーブルに結果を入れます。
旧レポート集計基盤
旧レポート集計基盤は以下のような流れになっていました(図1)。ログを出力するサーバは、ログを Logstash によって Kafka に転送します(図1①)。Flink は Kafka からログを読んで集計処理を行います(図1②)。Flink アプリケーションの処理は大きく分けて、重複排除を行うステップ、数値を集約するステップ、ClickHouse のレポート DB に格納するデータの形に変換するステップがあります。各ステップの処理結果は kafka に転送され、次のステップは先のステップの結果を Kafka から読んで処理を行います。最後に ClickHouse は集計結果を Kafka から読み、レポートテーブルに格納します(図1③)。
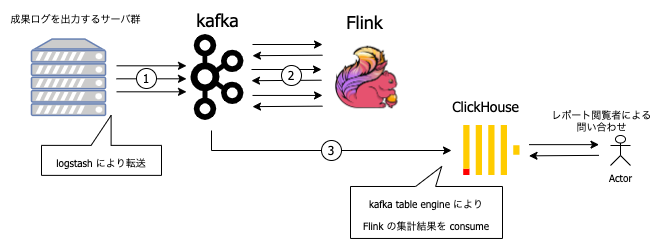
↑図1
旧レポート集計基盤の辛かったところ
旧レポート集計基盤では主に以下が問題になっていました。
- 成果ログを使った調査が面倒
- Flink を運用保守できる人が少ない(再集計が必要になったときの作業が面倒)
- Logstash が何故か安定しない
運用上、生の成果ログを使った調査を行いたいことがしばしばあります。しかし、ログファイルは大きいので調査対象の期間が長くなると検索するだけで何十分と時間がかかることもあります。
2つ目の問題として、Flink アプリケーションの保守&運用が難しく、誰も触りたがらないものとなってしまっていてなんとかしなければいけません。
また、ログパイプライン上で何か問題が起きて流れているログが一部欠損したような場合は、その時間帯のログからレポートを再集計する必要がありますが、そのときの手順も複雑でかなり面倒なものとなっていました。この手順のミスで再び再集計作業が必要になることもありました。
ログパイプライン上で問題が起きやすかったのは、ログ転送エージェントとして利用していた Logstash です。突然ログの転送が停止し、「よくわからないが再起動したらなおったのでヨシ」ということもしばしばありました。バージョンアップやチューニング、Logstash のソースコード調査などを行いましたが、結局解決されず原因は謎のままです。
方針と期待する効果
新しいレポート集計基盤の方針としては以下のようになりました。
- Flink は撤廃し、成果ログをそのまま ClickHouse に流し、ClickHouse 上で集計を行う
a. ClickHouse に成果ログを保持するテーブルを設けることで、成果ログの調査 が簡単になる
b. Kafka のストレージ容量・通信量が削減される - ログ転送エージェントを Logstash から td-agent-bit に変える
- ログ形式を JSON に変更する
まず Flink は撤廃することにします(さようなら)。代わりに成果ログの処理を行うのは ClickHouse で行うことにしました。弊社ではこれまで ClickHouse をレポート閲覧・分析用の DB としてのみ利用していたので新しい使い方にはなりますが、先輩方のこれまでの知見もありこれ自体に大きな問題もなく実現することができました。使い方としては基本的に普通の SQL なのでチームの人員に入れ替わりがあっても対応できそうです。
これに伴い、生の成果ログを ClickHouse に流すことになるわけですが、この成果ログを ClickHouse のログテーブルとして一定期間保持するようにすることにしました。これによって、その保持期間の間は調査に必要なログを SQL を使って取得することができます。成果ログを頻繁に調査する人にとっては結構嬉しい改善です。
先に述べたように、旧集計基盤の Flink アプリケーションは、各ステップの処理結果のデータが Flink と Kafka の間で往復していました。今回の変更はこのやりとりを無くすことになるので、Kafka のストレージ容量と通信量が大きく削減されます。
ログ転送エージェントの Logstash が安定しない問題の対策として、これを td-agent-bit (fluent-bit) に置き換えることにしました。弊社ではログ転送エージェントに td-agent (fluentd) を使っている部分が多いですが、以下の理由で td-agent-bit を選択しました。
- Kafka にログ転送を行うにあたり、td-agent-bit は librdkafka のバージョンが新しいものが使われていてかつ細かい設定が可能である
- CPU 使用率が大きく減少した。遅延が減ると期待できる
また、元々のログ形式は LTSV でしたが、これを JSON にすることにしました。多少ログのサイズが大きくなることが予想されましたが、代わりにログを扱いやすくすることを目指しました。
新しいログパイプラインとレポート集計系
以上を踏まえて設計すると以下のようになりました。(図2)
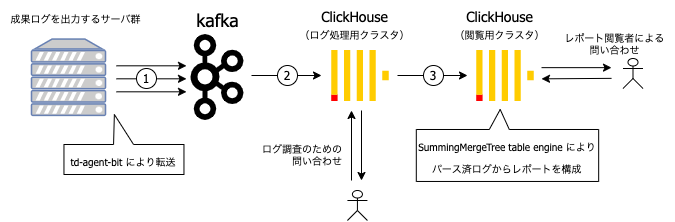
↑図2Kafka にログを流すところまでは、ログ転送エージェントが変わったこと以外は基本的に同じです。
上で述べたように、生ログの処理も ClickHouse で行うのですが、これまでレポート閲覧に使っていた ClickHouse クラスタ(以下、閲覧用クラスタと呼ぶ)とは別に、新しくログ処理のための ClickHouse クラスタ(以下、ログ処理用クラスタと呼ぶ)を作りました。Kafka からログを読むのはこのログ処理用クラスタのみになります(図2②)。このクラスタは Kafka から読んだログをパースして一定期間保持します。また、パース済みログを ClickHouse の Materialized View を利用して結果を閲覧用クラスタのレポートテーブルに挿入します(図2③)。このレポートテーブルはテーブルエンジンに SummingMergeTree を使っており、ここで数値が集計されます(後にもう少し詳しく説明します)。このようにクラスタを分けることにより、多くのレポート分析クエリが走って負荷が大きくなってもログ処理系に影響が出ないようにしました(その逆も同様)。
旧レポート集計系の良くなかったところとして、広告配信コストの計算のようなビジネスロジックの一部を Flink で行っていたということがあります。基本的にビジネスロジックは、ログを作るアプリケーション側で処理をして結果をログに落とすという形を取っていたので、ビジネスロジックを処理する場所が分散していました。そのため、今回 Flink に残っているビジネスロジックは全てログを作るアプリケーション側に寄せる変更を行いました。これによって、ClickHouse の集計はログに書いてある値を集約するだけで可能になりました。
ClickHouse 上でのレポート集計に使った機能
簡単にですが、ClickHouse 上でのレポート集計を支える機能の一部をご紹介します。
Kafka table engine
Kafka からログを読むのは Kafka table engine を利用しています。このテーブルを select することで Kafka のデータを consume して読むことができます。consume するので同じデータが読めるのは一度だけで、実際には以下で説明する Materialized View を使ってデータを読みます。
Materialized View
一般的な DB の Materialized View は、クエリ結果を期限付きでキャッシュする形で動作しますが、ClickHouse はそうではありません。ClickHouse の Materialized View は参照しているテーブルにレコードが挿入されたのをトリガーとして、そのレコードのみに対して処理を行い、結果をその Materialized View または指定する別テーブルに挿入します(別テーブルに挿入した結果はもちろん消えることはありません)。差分に対してのみ処理が行われるため高速に処理してくれます。
新レポート集計基盤では主に以下の用途で Materialized View を使っています。
- 生ログテーブルを読み、パースしてパース済みのログテーブルに挿入する
- パース済みのログテーブルを読み、レポートテーブル(SummingMergeTree table engine)に挿入する
1 では JSON 形式のログをパースして、必要なプロパティをカラムにしてログテーブルに挿入しています。
最終的なレポートテーブルは SummingMergeTree table engine を使っています。SummingMergeTree table engine は、挿入されたレコードを、テーブル定義の中で明示的に指定した特定のカラム(数値の型)のみ足し上げてくれます。2 の Materialized View が各成果情報を SummingMergeTree のレポートテーブルに挿入することによって、レポートテーブル上で必要な各種広告配信の指標(インプレッション数やクリック数、その他配信費など)が足し上げられ、結果が閲覧できます。
JSON を扱うための関数群
ClickHouse では JSON を扱うための SQL の関数が用意されており、我々はこれを利用して JSON のパースを行っています。C++ や simdjson を使って実装されているため、大量のログも高速に処理できています。
改善されたこと
当初の狙いだった以下のことについては達成することができました。
- 成果ログの調査が楽になった
- レポート集計基盤が安定し、再集計が必要になることがなくなった
- Flink を完全撤廃することができた(以前より運用しやすい状態になった)
上記以外では、Kafka の転送量が減ったことによって Kafka のサーバ台数も減らすことができました。Kafka サーバは約半数減、Flink サーバ全台撤廃、ClickHouse の集計用クラスタに数台のサーバを追加となり、全体のサーバの増減としては 10 台以上のサーバ減となりました。
また、ログが落ちてからレポートに反映されるまでの遅延が大幅に短くなりました。旧レポート集計基盤ではピークタイムに約 30 分の遅延がありましたが、新レポート集計基盤では基本的に 2 分以内に収まっています。
おわりに
レポート集計基盤の刷新した件について、新旧の違いと改善できたこと等を説明しました。と、まあ全てが上手くいったような書き方をしてきましたが、間で多々問題があったので着手から完了までかなり時間がかかり、関係各所にはご迷惑をおかけしました。今回は多くの勉強・反省することがあったので、今後これを活かして頑張っていきたいと思います。