ジーニーが大切にしているValueの一つである「Well-being」。ビジネスでの成功を組織に還元し、社員の経済やキャリア、そして健康や幸せを実現できる職場づくりを目指しています。
そんなWell-beingを象徴するのが充実した福利厚生制度。そのなかで「時差勤務」を活用し、仕事もプライベートも充実させている社員をご紹介します。
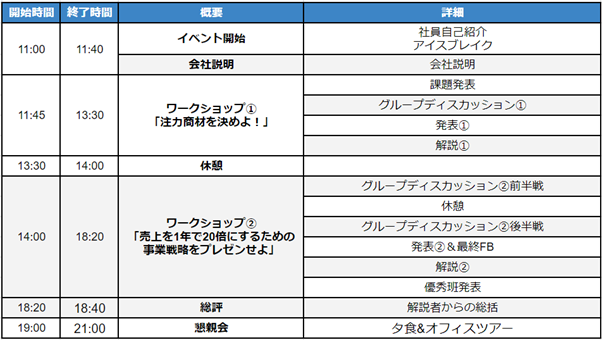
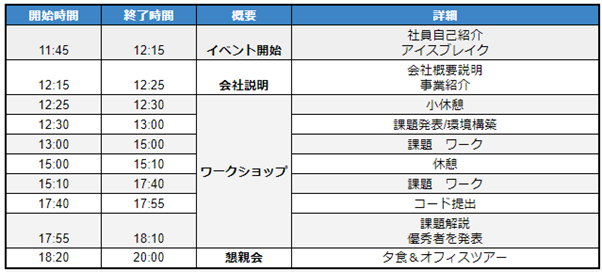
■時差出勤制度 概要
通勤や事情がある場合、12時までの勤務開始を条件に勤務時間をずらすことができます。
※エンジニアなど専門性の高い業種では本制度とは別に「専門業務型裁量労働制」で働くこともできます。
CASE1

▲アドプラットフォーム統括本部 デマンドサイド事業部 アカウントマネジメント部 Performance Team 3 リーダー 松元さん
旅行や映画など、趣味の時間を楽しむために制度を活用している松元さん。
仕事のメリハリが生まれ、家族との時間も増えたといいます。
華金の夜から徳島旅行でリフレッシュ
ーーどのように制度を活用していますか?
旅行へ行ったり、映画を観行ったり、プライベートを充実させるために使っています。この前は金曜の18時に退勤して、そのまま飛行機で徳島へ行きました。航空会社のセールでチケットがたまたま安かったので(笑)。
徳島では「大塚国際美術館」という、世界の名画をタイルで再現した “触れる絵” を展示している美術館へ行きました。メジャーな観光地へ行くよりも新しい体験ができて、良い刺激になりました。

メリハリのある働き方で家族との時間も大切に
ーー時差制度を使って働き方は変わりましたか?
以前は「仕事が終わったら帰る」というスタイルで退勤時間を決めずに仕事をしていましたが、時差勤務を使って夜に予定を入れることで、オンオフがはっきりとしました。
時差出勤の日、事前に決めたタスクをすべて終わらせてから用事に向かえる時は気持ちがいいです。
また、以前はパートナーから「帰りが遅いね」と言われていましたが、「今日は一緒に映画観るから早く帰ろう」と決めることで、家族との時間も増えましたね。
ダラダラと長く働くのと、短い時間で集中して終わらせるなら、短いほうがいいじゃないですか。自分の仕事のやり方やスケジュール管理も整理できるようになるので、仕事に対しての責任感を持ち、自己管理や社内共有がしっかりできる人にはおすすめできます。
ーー最後に一言お願いします!
「仕事以外のこともやりたい、自分の時間をもっと有益に使いたい!」という働き方への希望は上司や周りの人に相談すれば話を聞いてくれる環境です。
キャリアの実現を目標にするのも良いですが、それだけでは長続きしません。こうした制度でリフレッシュすることが仕事へのモチベーションに繋がり、いいサイクルとなります。会社にとっても自分にとっても、良い働き方を見つけるために制度をうまく使えればと思います。
CASE2

▲人事部 労務 リーダー 薄井さん
ヨガ教室に通っているという薄井さん。決まったレッスン時間に合わせて業務を進行することで、残業も減り健康的な生活になったといいます。夕方になると周囲から「ヨガの時間ですよ!」と声をかけられる日もあるほど、仕事と生活の一部にヨガが溶け込んでいるそうです。
ヨガが生活の一部に。業務への集中力もアップ
ーーどのように制度を活用していますか?
会社近くのヨガ教室に通うため、業務の調整ができる日は1時間終業時間を前倒しています。
日々の運動習慣をつけたいと思っていた時に、ヨガ教室が近くにあることを知ったのをきっかけに通い始めました。
実は、ヨガを始める前までは恒常的に残業していました。「いつまでも時間がある」という気持ちから、仕事の量をこなす意識で働いていました。今は、ヨガに行くために終業時刻を決めて逆算して効率を意識しながら業務を進めています。
また、ヨガで心身を整えることで常に体と頭がすっきりし、集中力もアップしました。新しい業務課題がたくさん発生しますが、スピード感や、専門知識のアップデートなどの集中力が必要なタスクの処理は、ヨガを始める前よりも格段に良くなりました。
時差出勤が働き方改革の一助に
ーー薄井さん以外にも時差勤務をされている方はいますか?
周りの人も、
「好きなブランドのファミリーセールの初日に行って、欲しかった服がゲットできました!」とか、「予約がとりにくい有名な焼肉屋さんが17:00~で予約がとれたので行ってきます!」とか、ちょっとした楽しみに使っているという人が多いと思います。
もちろん私も毎日時差出勤というわけではないですし、他の方もそれは同じだと思います。
忙しい時は仕事に集中し、オフに予定がある時は周りの方とお互い予定を調整し合いながら各自がメリハリを持って働いています。
ーー最後に一言お願いします!
時差出勤の日があることで、仕事以外の時間を計画的使うことができているので、1日の充実度がアップします。目的意識を持って仕事も自分の時間も有意義に使っていきたい方におすすめです。
■ジーニーについて
ジーニーは、「誰もがマーケティングで成功できる世界を創る」
「日本発の世界的なテクノロジー企業となり、日本とアジアに貢献する」
というパーパス(企業の存在意義)のもと、企業の収益拡大・生産性向上など様々な課題解決につながるソリューションを開発・提供するマーケティングテクノロジーカンパニーです。